Psychology Department, Goldsmiths University of London, London, UK.
Center for Cognition and Decision Making, National Research University Higher School of Economics, Moscow, Russian Federation.
Sci Rep. 2021 Oct 13;11(1):20303. doi: 10.1038/s41598-021-98571-y.
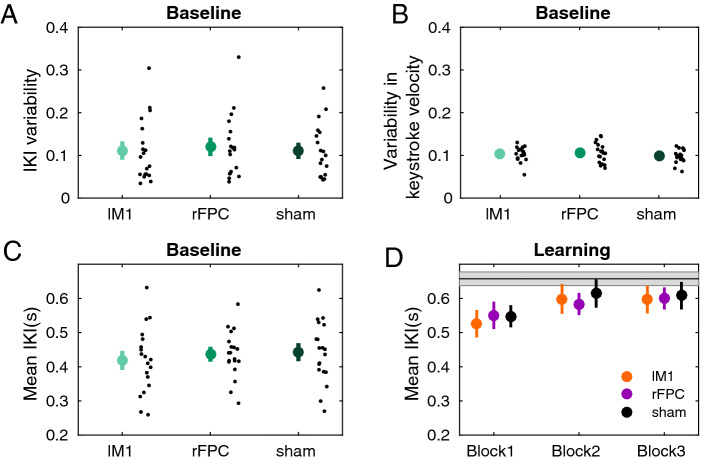
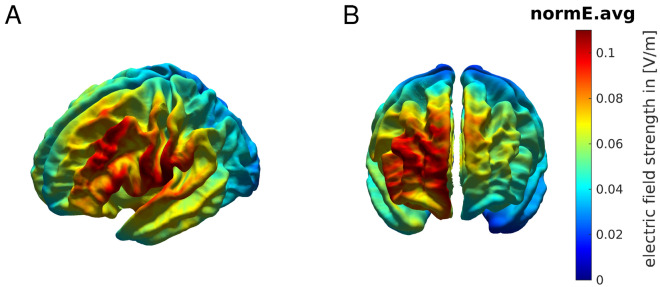
The frontopolar cortex (FPC) contributes to tracking the reward of alternative choices during decision making, as well as their reliability. Whether this FPC function extends to reward gradients associated with continuous movements during motor learning remains unknown. We used anodal transcranial direct current stimulation (tDCS) over the right FPC to investigate its role in reward-based motor learning. Nineteen healthy human participants practiced novel sequences of finger movements on a digital piano with corresponding auditory feedback. Their aim was to use trialwise reward feedback to discover a hidden performance goal along a continuous dimension: timing. We additionally modulated the contralateral motor cortex (left M1) activity, and included a control sham stimulation. Right FPC-tDCS led to faster learning compared to lM1-tDCS and sham through regulation of motor variability. Bayesian computational modelling revealed that in all stimulation protocols, an increase in the trialwise expectation of reward was followed by greater exploitation, as shown previously. Yet, this association was weaker in lM1-tDCS suggesting a less efficient learning strategy. The effects of frontopolar stimulation were dissociated from those induced by lM1-tDCS and sham, as motor exploration was more sensitive to inferred changes in the reward tendency (volatility). The findings suggest that rFPC-tDCS increases the sensitivity of motor exploration to updates in reward volatility, accelerating reward-based motor learning.
额顶皮质(FPC)有助于在决策过程中跟踪替代选择的奖励及其可靠性。在运动学习过程中,这种 FPC 功能是否扩展到与连续运动相关的奖励梯度尚不清楚。我们使用经颅直流电刺激(tDCS)对右额顶叶皮层进行刺激,以研究其在基于奖励的运动学习中的作用。19 名健康的人类参与者在数字钢琴上练习新的手指运动序列,并伴有相应的听觉反馈。他们的目标是使用试验奖励反馈沿着连续维度发现隐藏的性能目标:时间。我们还调节了对侧运动皮层(左 M1)的活动,并包括对照假刺激。与 lM1-tDCS 和假刺激相比,右额顶叶皮层刺激通过调节运动变异性导致更快的学习。贝叶斯计算模型显示,在所有刺激方案中,随着试验奖励预期的增加,随后的利用程度更高,如前所述。然而,在 lM1-tDCS 中,这种关联较弱,表明学习策略效率较低。额顶叶刺激的效果与 lM1-tDCS 和假刺激的效果不同,因为运动探索对推断出的奖励倾向变化(波动性)更敏感。研究结果表明,rFPC-tDCS 提高了运动探索对奖励波动性更新的敏感性,从而加速了基于奖励的运动学习。