Department of Human Movement Sciences, Vrije Universiteit Amsterdam, Amsterdam, The Netherlands.
PLoS One. 2020 Apr 2;15(4):e0226789. doi: 10.1371/journal.pone.0226789. eCollection 2020.
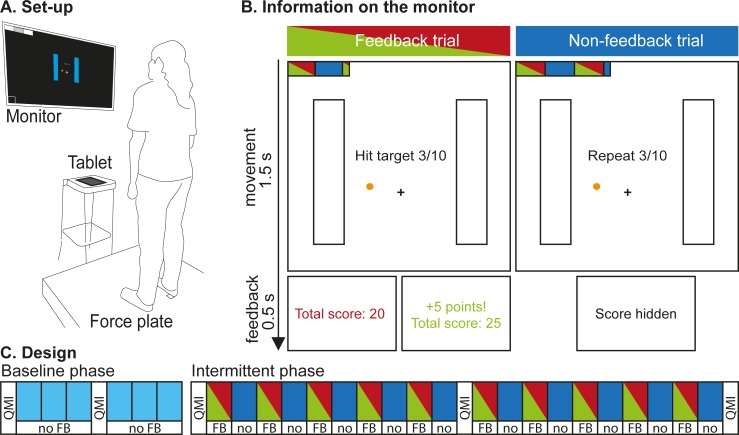
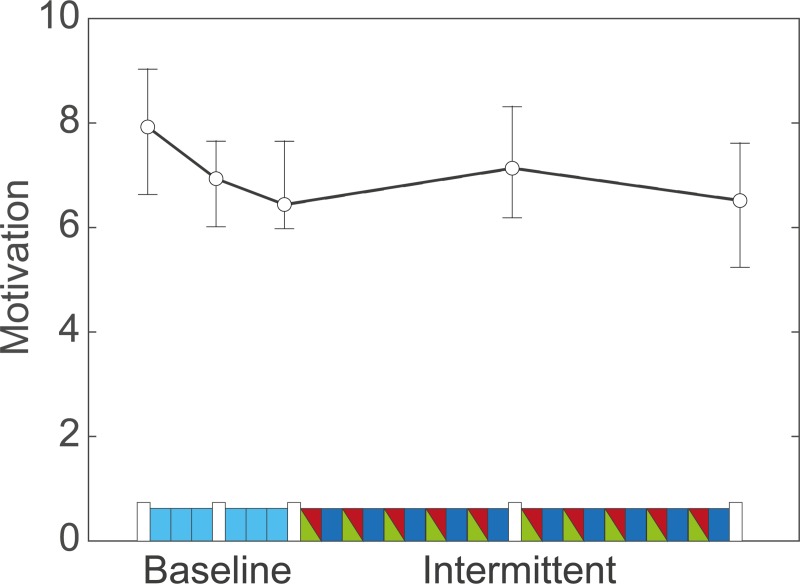
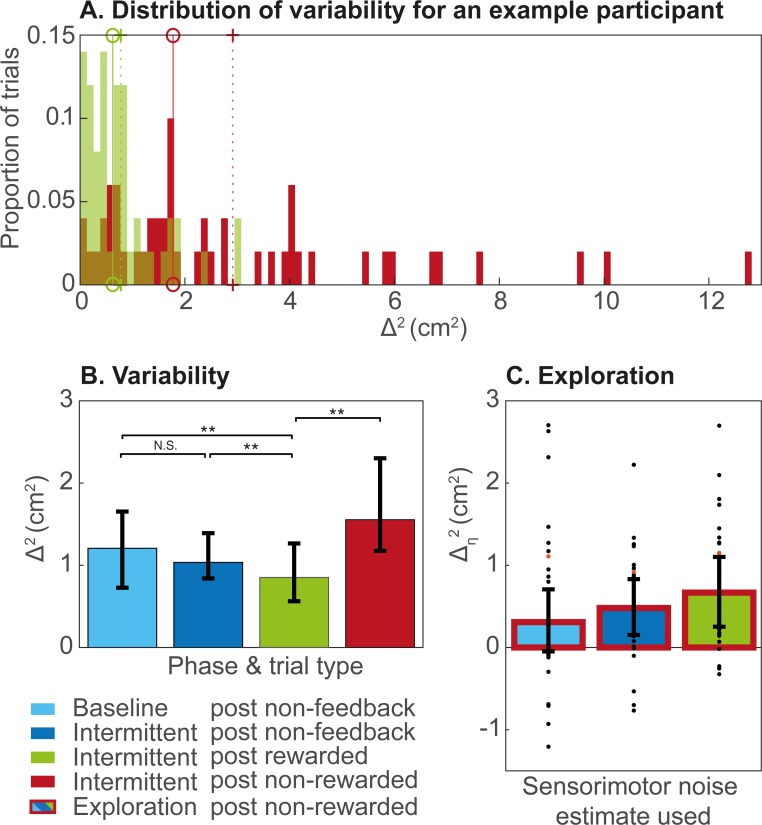
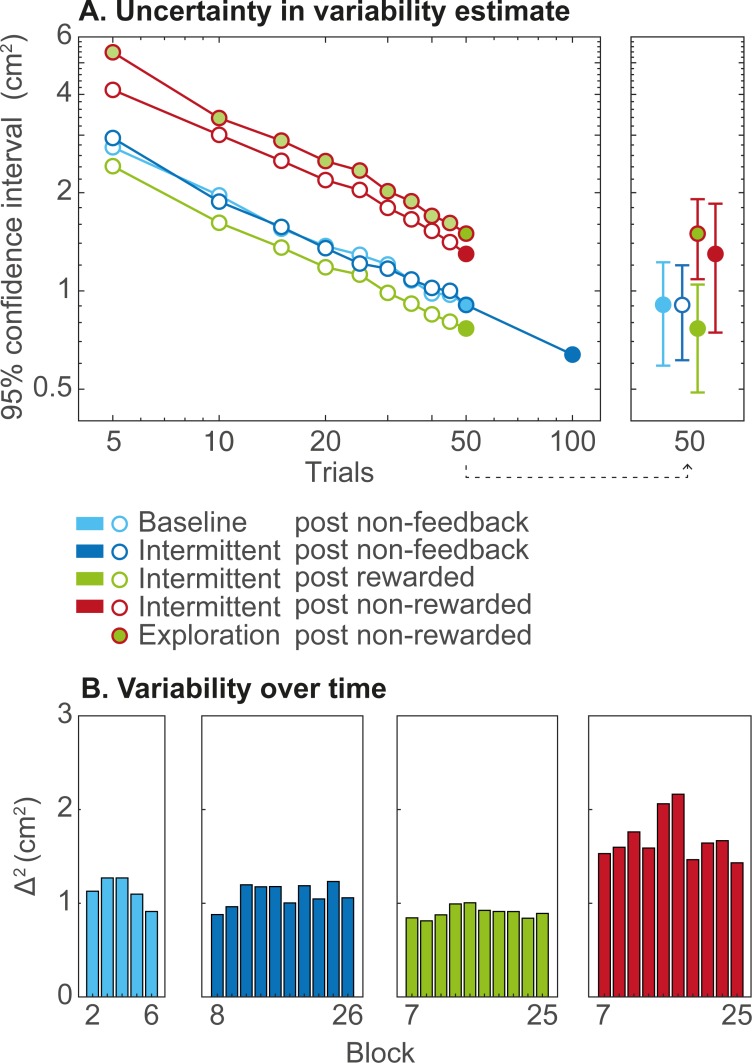
Exploration in reward-based motor learning is observable in experimental data as increased variability. In order to quantify exploration, we compare three methods for estimating other sources of variability: sensorimotor noise. We use a task in which participants could receive stochastic binary reward feedback following a target-directed weight shift. Participants first performed six baseline blocks without feedback, and next twenty blocks alternating with and without feedback. Variability was assessed based on trial-to-trial changes in movement endpoint. We estimated sensorimotor noise by the median squared trial-to-trial change in movement endpoint for trials in which no exploration is expected. We identified three types of such trials: trials in baseline blocks, trials in the blocks without feedback, and rewarded trials in the blocks with feedback. We estimated exploration by the median squared trial-to-trial change following non-rewarded trials minus sensorimotor noise. As expected, variability was larger following non-rewarded trials than following rewarded trials. This indicates that our reward-based weight-shifting task successfully induced exploration. Most importantly, our three estimates of sensorimotor noise differed: the estimate based on rewarded trials was significantly lower than the estimates based on the two types of trials without feedback. Consequently, the estimates of exploration also differed. We conclude that the quantification of exploration depends critically on the type of trials used to estimate sensorimotor noise. We recommend the use of variability following rewarded trials.
基于奖励的运动学习中的探索在实验数据中表现为变异性增加。为了量化探索,我们比较了三种估计其他来源变异性的方法:感觉运动噪声。我们使用了一个任务,在这个任务中,参与者可以在目标导向的权重转移后收到随机的二进制奖励反馈。参与者首先进行了六个没有反馈的基线块,然后是二十个有和没有反馈的交替块。变异性是基于每个试次的运动终点的变化来评估的。我们通过在没有探索预期的试次中,运动终点的试次到试次的中位数平方变化来估计感觉运动噪声。我们确定了三种这样的试次类型:基线块中的试次、没有反馈的块中的试次和有反馈的块中的奖励试次。我们通过非奖励试次减去感觉运动噪声后的中位数平方试次到试次的变化来估计探索。正如预期的那样,非奖励试次后的变异性比奖励试次后的变异性更大。这表明我们的基于奖励的权重转移任务成功地诱导了探索。最重要的是,我们对感觉运动噪声的三种估计值不同:基于奖励试次的估计值明显低于基于两种无反馈试次的估计值。因此,探索的估计值也不同。我们得出结论,探索的量化取决于用于估计感觉运动噪声的试次类型。我们建议使用奖励后试次的变异性。