Heo Jinwon, Baek Jangsun
Department of Mathematics and Statistics, Chonnam National University, 77 Yongbong-ro, Buk-gu, Gwangju 61186, Korea.
Entropy (Basel). 2021 Sep 26;23(10):1249. doi: 10.3390/e23101249.
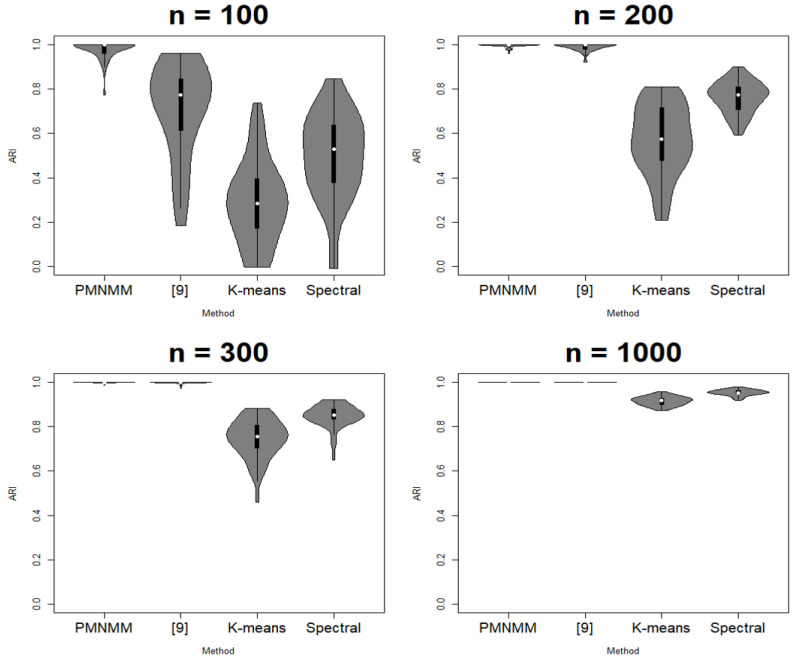
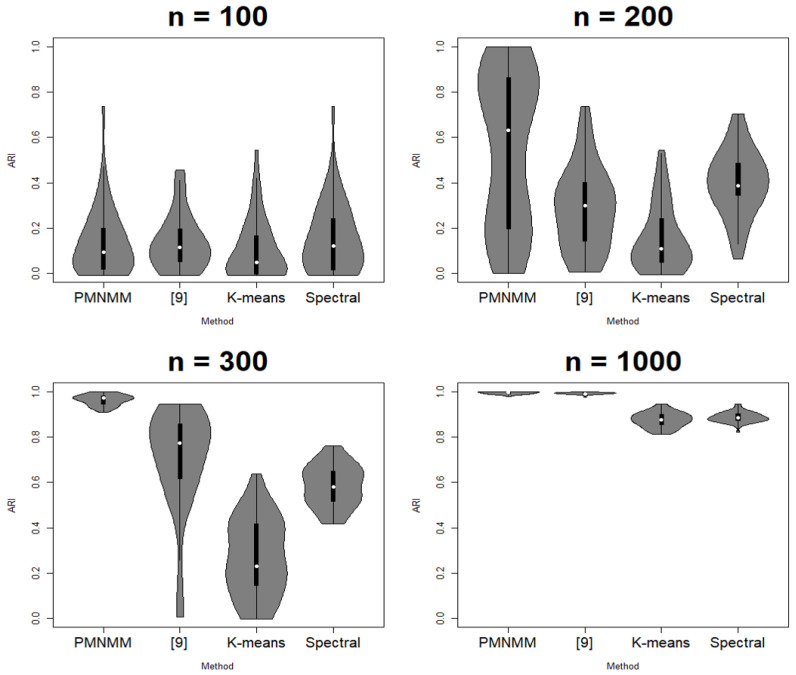
Along with advances in technology, matrix data, such as medical/industrial images, have emerged in many practical fields. These data usually have high dimensions and are not easy to cluster due to their intrinsic correlated structure among rows and columns. Most approaches convert matrix data to multi dimensional vectors and apply conventional clustering methods to them, and thus, suffer from an extreme high-dimensionality problem as well as a lack of interpretability of the correlated structure among row/column variables. Recently, a regularized model was proposed for clustering matrix-valued data by imposing a sparsity structure for the mean signal of each cluster. We extend their approach by regularizing further on the covariance to cope better with the curse of dimensionality for large size images. A penalized matrix normal mixture model with lasso-type penalty terms in both mean and covariance matrices is proposed, and then an expectation maximization algorithm is developed to estimate the parameters. The proposed method has the competence of both parsimonious modeling and reflecting the proper conditional correlation structure. The estimators are consistent, and their limiting distributions are derived. We applied the proposed method to simulated data as well as real datasets and measured its clustering performance with the clustering accuracy (ACC) and the adjusted rand index (ARI). The experiment results show that the proposed method performed better with higher ACC and ARI than those of conventional methods.
随着技术的进步,矩阵数据,如医学/工业图像,已出现在许多实际领域。这些数据通常具有高维度,并且由于其行与列之间固有的相关结构而不易聚类。大多数方法将矩阵数据转换为多维向量并对其应用传统的聚类方法,因此,会面临极高维度问题以及行/列变量之间相关结构缺乏可解释性的问题。最近,有人提出了一种正则化模型,通过对每个聚类的均值信号施加稀疏结构来对矩阵值数据进行聚类。我们通过对协方差进一步正则化来扩展他们的方法,以更好地应对大尺寸图像的维度灾难。提出了一种在均值矩阵和协方差矩阵中都带有套索型惩罚项的惩罚矩阵正态混合模型,然后开发了一种期望最大化算法来估计参数。所提出的方法具有简约建模和反映适当条件相关结构的能力。估计量是一致的,并推导了它们的极限分布。我们将所提出的方法应用于模拟数据以及真实数据集,并使用聚类准确率(ACC)和调整兰德指数(ARI)来衡量其聚类性能。实验结果表明,所提出的方法在ACC和ARI方面比传统方法表现更好。