Feng Cindy Xin
Department of Community Health and Epidemiology, Faculty of Medicine, Dalhousie University, 5790 University Avenue, Halifax, B3H 4R2 Nova Scotia Canada.
J Stat Distrib Appl. 2021;8(1):8. doi: 10.1186/s40488-021-00121-4. Epub 2021 Jun 24.
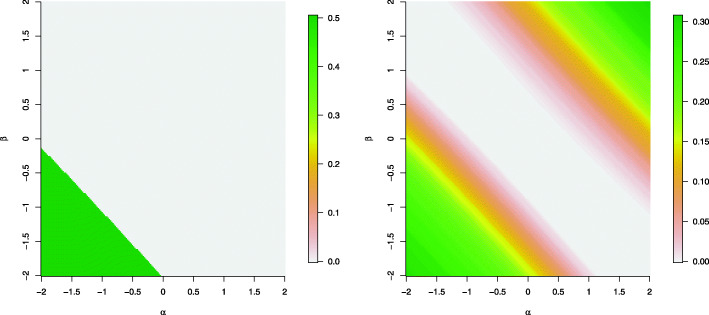
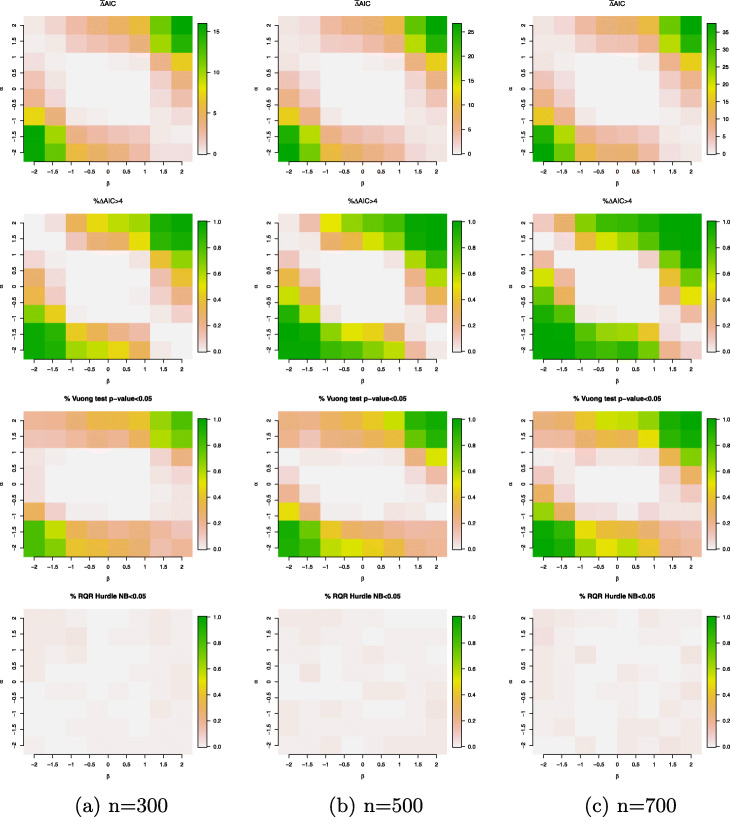
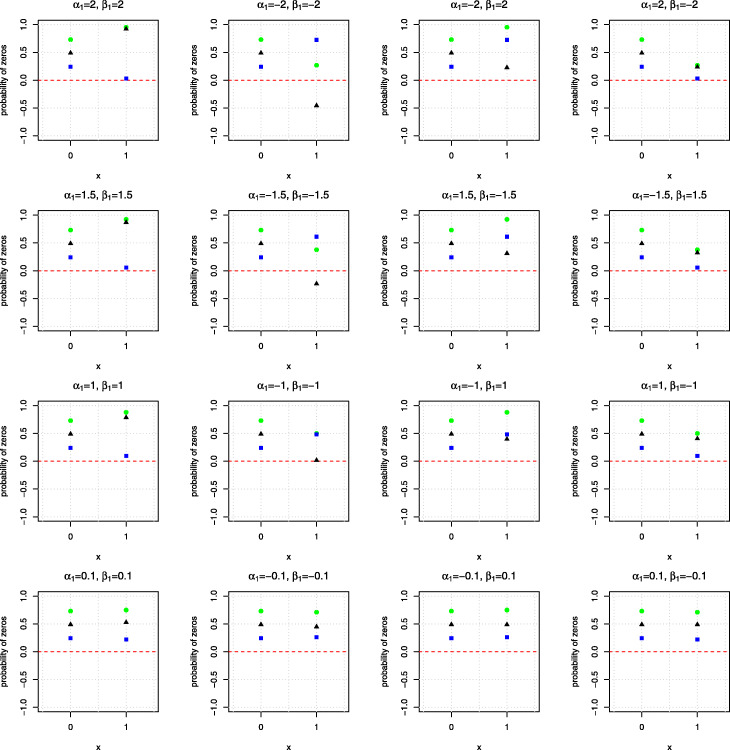
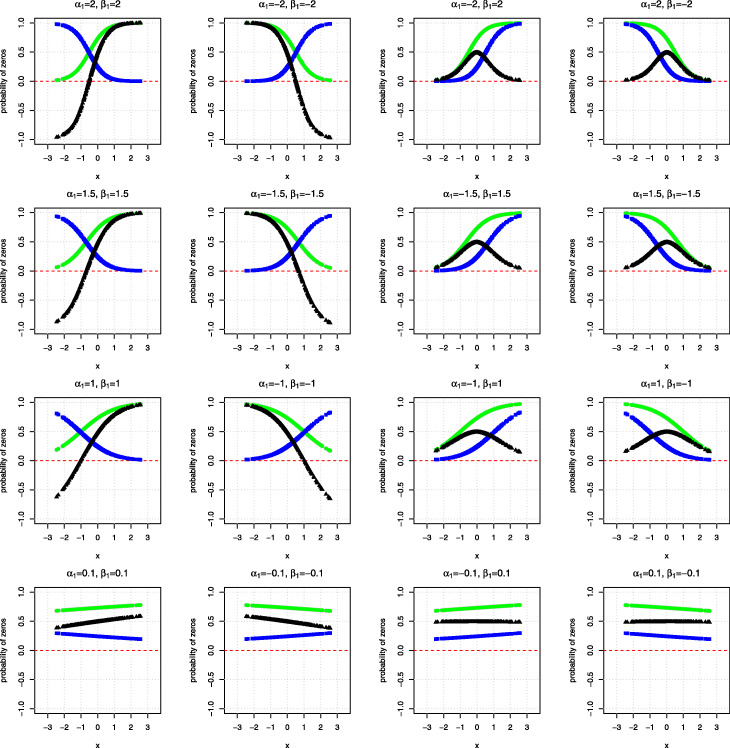
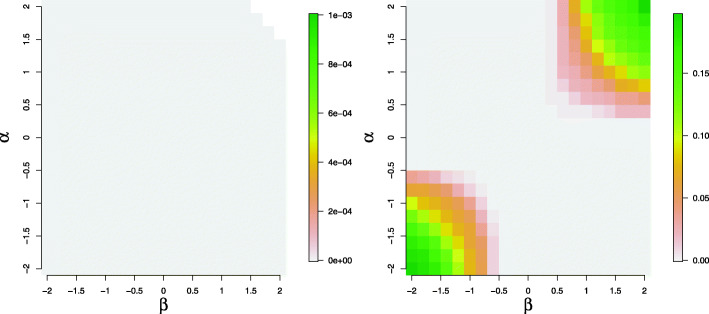
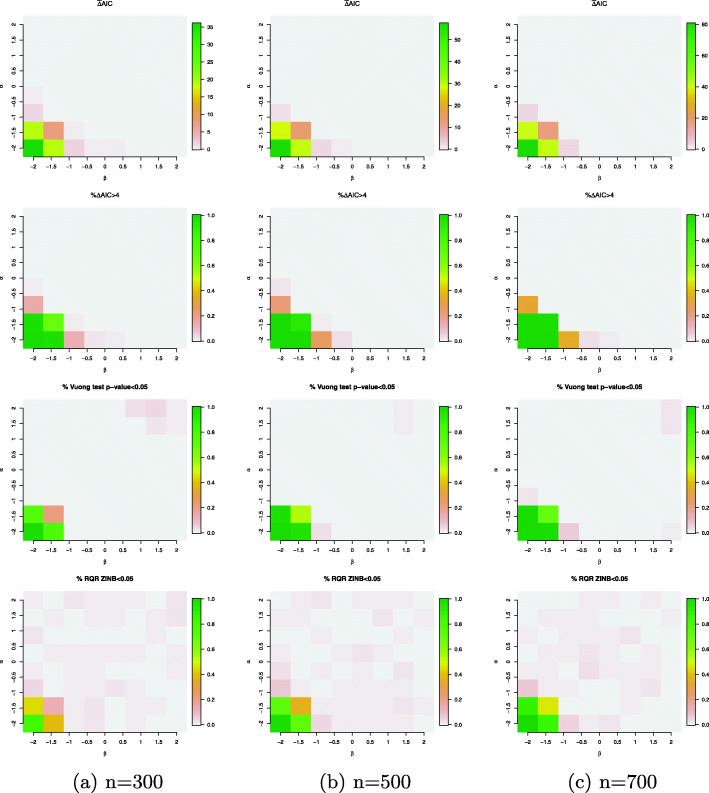
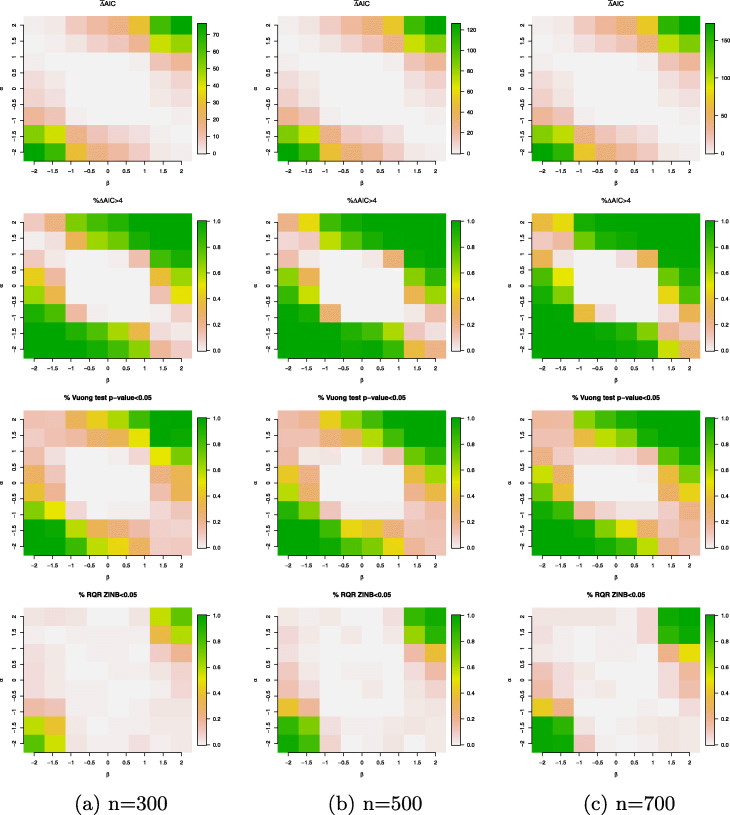
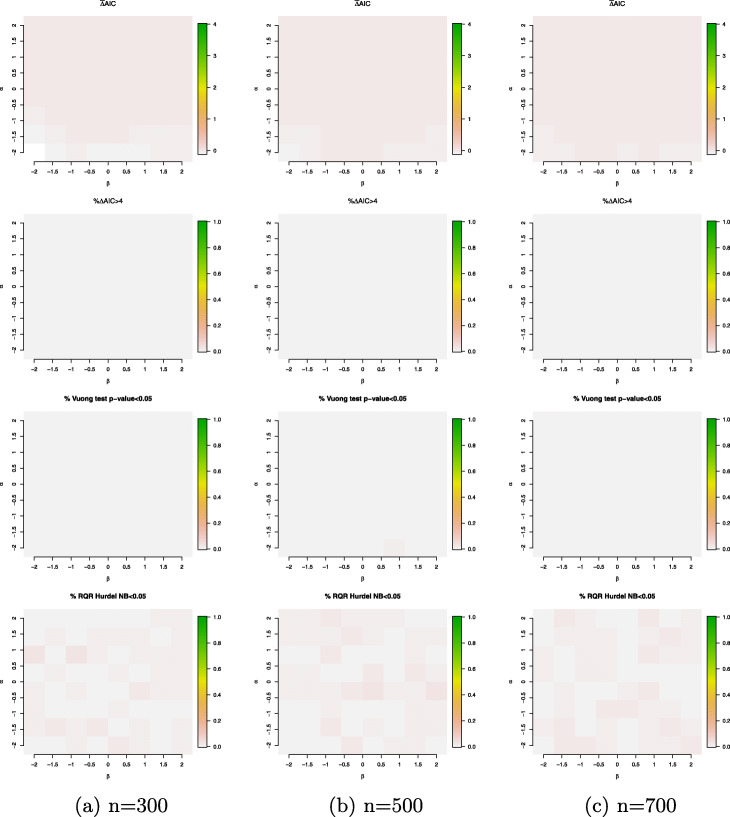
Counts data with excessive zeros are frequently encountered in practice. For example, the number of health services visits often includes many zeros representing the patients with no utilization during a follow-up time. A common feature of this type of data is that the count measure tends to have excessive zero beyond a common count distribution can accommodate, such as Poisson or negative binomial. Zero-inflated or hurdle models are often used to fit such data. Despite the increasing popularity of ZI and hurdle models, there is still a lack of investigation of the fundamental differences between these two types of models. In this article, we reviewed the zero-inflated and hurdle models and highlighted their differences in terms of their data generating processes. We also conducted simulation studies to evaluate the performances of both types of models. The final choice of regression model should be made after a careful assessment of goodness of fit and should be tailored to a particular data in question.
在实际应用中,经常会遇到含有大量零值的计数数据。例如,医疗服务就诊次数通常包含许多零值,这些零值代表在随访期间未使用医疗服务的患者。这类数据的一个共同特征是,计数指标往往有过多的零值,超出了泊松分布或负二项分布等常见计数分布所能容纳的范围。零膨胀模型或门槛模型通常用于拟合此类数据。尽管零膨胀模型和门槛模型越来越受欢迎,但对这两种模型之间的根本差异仍缺乏研究。在本文中,我们回顾了零膨胀模型和门槛模型,并强调了它们在数据生成过程方面的差异。我们还进行了模拟研究,以评估这两种模型的性能。回归模型的最终选择应在仔细评估拟合优度之后做出,并应根据具体的数据进行调整。