Lawson Daniel J, Solanki Vinesh, Yanovich Igor, Dellert Johannes, Ruck Damian, Endicott Phillip
Institute of Statistical Sciences, School of Mathematics, University of Bristol, Bristol, UK.
Integrative Epidemiology Unit, Population Health Sciences, University of Bristol, Bristol, UK.
R Soc Open Sci. 2021 Dec 8;8(12):202182. doi: 10.1098/rsos.202182. eCollection 2021 Dec.
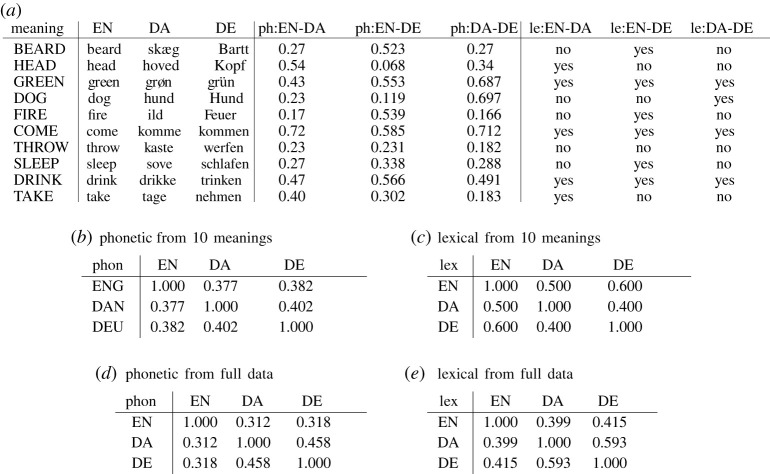
Integrating datasets from different disciplines is hard because the data are often qualitatively different in meaning, scale and reliability. When two datasets describe the same entities, many scientific questions can be phrased around whether the (dis)similarities between entities are conserved across such different data. Our method, CLARITY, quantifies consistency across datasets, identifies where inconsistencies arise and aids in their interpretation. We illustrate this using three diverse comparisons: gene methylation versus expression, evolution of language sounds versus word use, and country-level economic metrics versus cultural beliefs. The non-parametric approach is robust to noise and differences in scaling, and makes only weak assumptions about how the data were generated. It operates by decomposing similarities into two components: a 'structural' component analogous to a clustering, and an underlying 'relationship' between those structures. This allows a 'structural comparison' between two similarity matrices using their predictability from 'structure'. Significance is assessed with the help of re-sampling appropriate for each dataset. The software, CLARITY, is available as an R package from github.com/danjlawson/CLARITY.
整合来自不同学科的数据集并非易事,因为这些数据在含义、规模和可靠性方面往往存在质的差异。当两个数据集描述的是相同的实体时,许多科学问题可以围绕这些实体之间的(不)相似性在如此不同的数据中是否保持一致来提出。我们的方法CLARITY可以量化数据集之间的一致性,识别不一致出现的位置并帮助解释这些不一致。我们通过三个不同的比较来说明这一点:基因甲基化与基因表达、语音演变与词汇使用,以及国家层面的经济指标与文化信仰。这种非参数方法对噪声和尺度差异具有鲁棒性,并且对数据的生成方式仅做了较弱的假设。它通过将相似性分解为两个部分来运作:一个类似于聚类的“结构”部分,以及这些结构之间潜在的“关系”。这使得可以使用两个相似性矩阵从“结构”中的可预测性进行“结构比较”。借助针对每个数据集的重采样来评估显著性。软件CLARITY可作为R包从github.com/danjlawson/CLARITY获取。