Integrated Program in Quantitative Biology, University of California San Francisco, San Francisco, California, USA.
Bakar Computational Health Sciences Institute, University of California San Francisco, San Francisco, California, USA.
J Am Med Inform Assoc. 2022 Jan 29;29(3):424-434. doi: 10.1093/jamia/ocab270.
Early identification of chronic diseases is a pillar of precision medicine as it can lead to improved outcomes, reduction of disease burden, and lower healthcare costs. Predictions of a patient's health trajectory have been improved through the application of machine learning approaches to electronic health records (EHRs). However, these methods have traditionally relied on "black box" algorithms that can process large amounts of data but are unable to incorporate domain knowledge, thus limiting their predictive and explanatory power. Here, we present a method for incorporating domain knowledge into clinical classifications by embedding individual patient data into a biomedical knowledge graph.
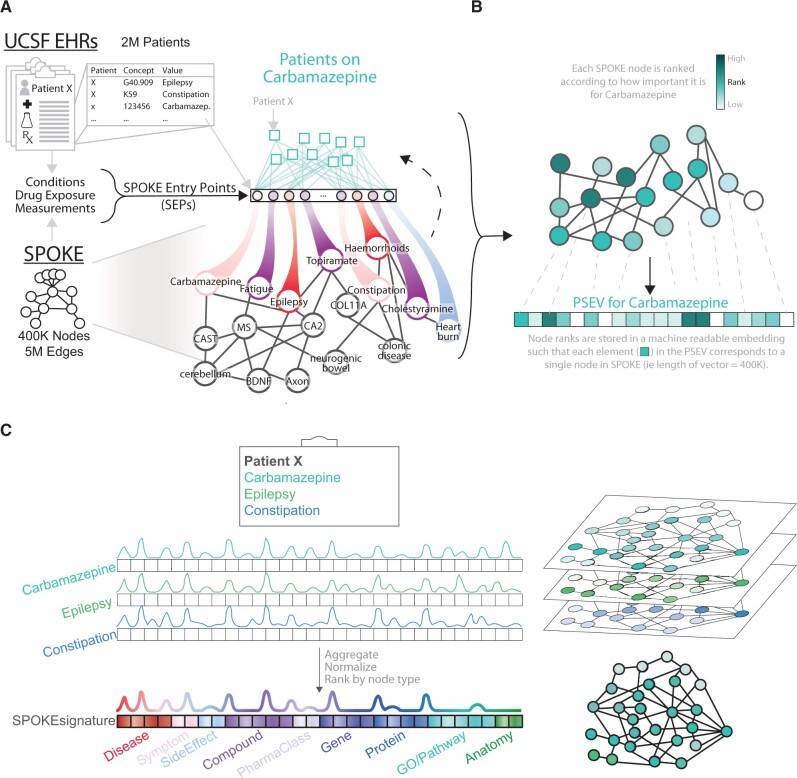
A modified version of the Page rank algorithm was implemented to embed millions of deidentified EHRs into a biomedical knowledge graph (SPOKE). This resulted in high-dimensional, knowledge-guided patient health signatures (ie, SPOKEsigs) that were subsequently used as features in a random forest environment to classify patients at risk of developing a chronic disease.
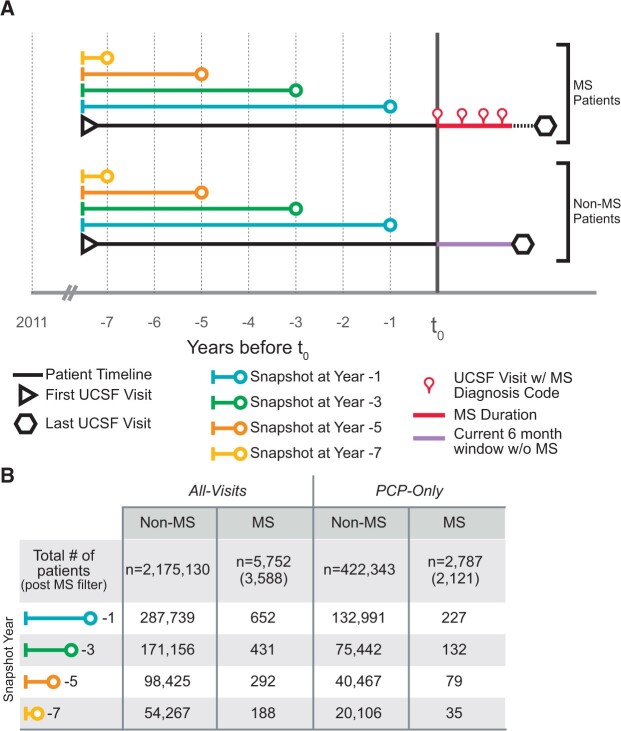
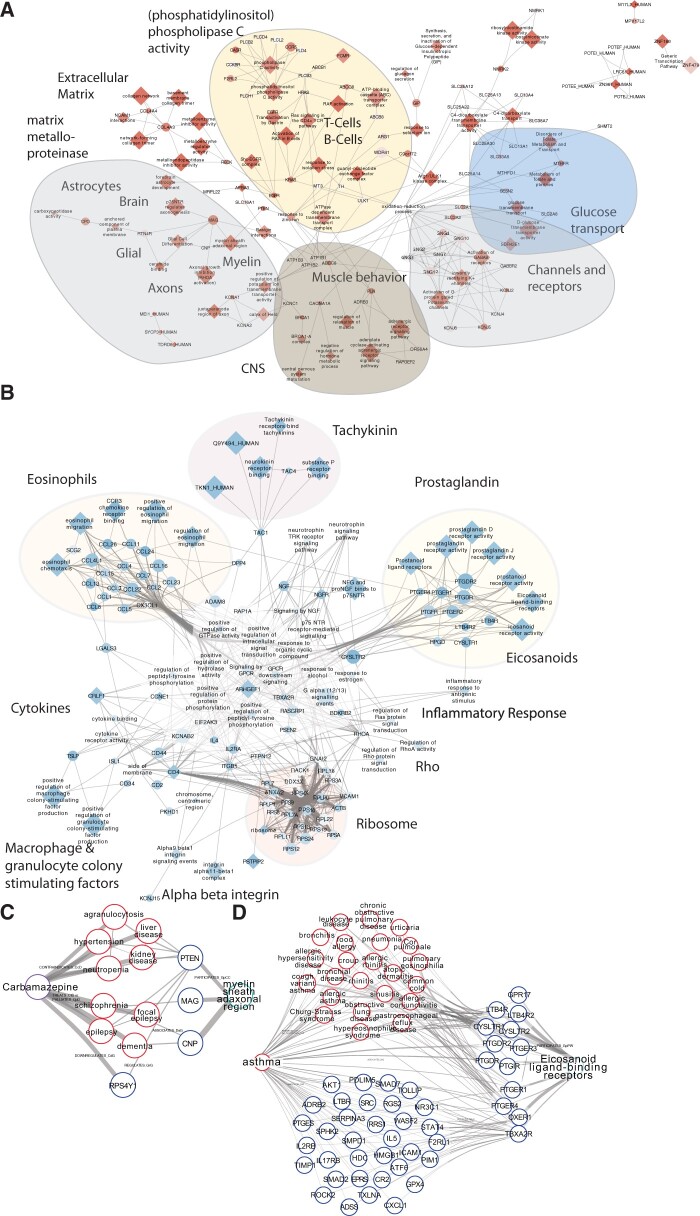
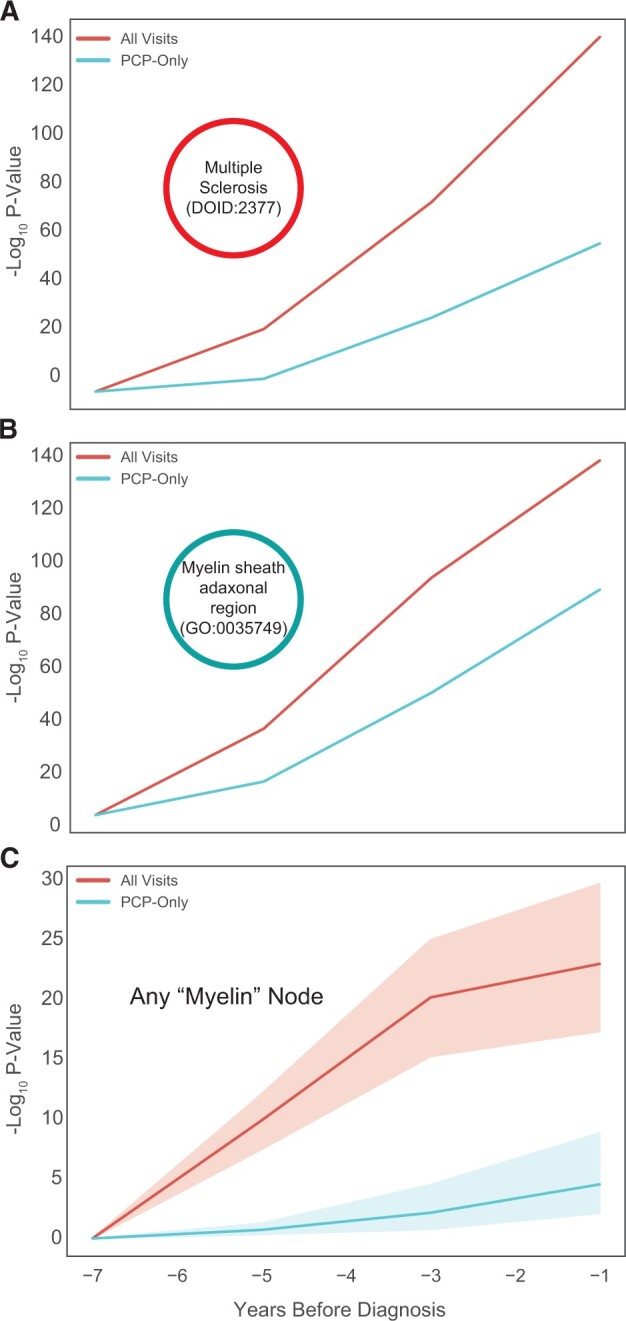
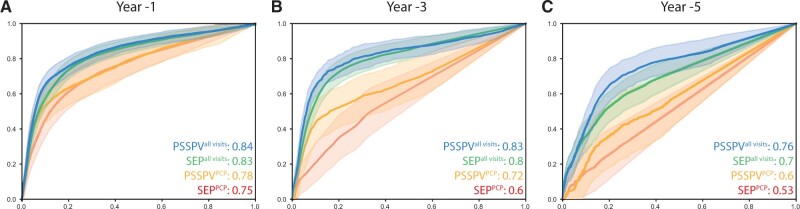
Our model predicted disease status of 5752 subjects 3 years before being diagnosed with multiple sclerosis (MS) (AUC = 0.83). SPOKEsigs outperformed predictions using EHRs alone, and the biological drivers of the classifiers provided insight into the underpinnings of prodromal MS.
Using data from EHR as input, SPOKEsigs describe patients at both the clinical and biological levels. We provide a clinical use case for detecting MS up to 5 years prior to their documented diagnosis in the clinic and illustrate the biological features that distinguish the prodromal MS state.
慢性病的早期识别是精准医学的一个支柱,因为它可以改善治疗效果、减轻疾病负担和降低医疗成本。通过将机器学习方法应用于电子健康记录(EHR),可以改善对患者健康轨迹的预测。然而,这些方法传统上依赖于“黑箱”算法,这些算法可以处理大量数据,但无法纳入领域知识,从而限制了其预测和解释能力。在这里,我们提出了一种通过将个体患者数据嵌入生物医学知识图来将领域知识纳入临床分类的方法。
我们实施了一种经过修改的 Page rank 算法,将数百万份去识别的 EHR 嵌入生物医学知识图(SPOKE)中。这导致了高维的、受知识指导的患者健康特征(即 SPOKEsigs),随后这些特征被用作随机森林环境中的特征来对有发展慢性病风险的患者进行分类。
我们的模型预测了 5752 名受试者在被诊断为多发性硬化症(MS)之前 3 年的疾病状况(AUC = 0.83)。SPOKE 特征优于仅使用 EHR 的预测,并且分类器的生物学驱动因素提供了对前驱 MS 潜在机制的深入了解。
使用 EHR 中的数据作为输入,SPOKE 特征可以描述患者的临床和生物学水平。我们提供了一个临床应用案例,用于在诊所记录的诊断前长达 5 年检测 MS,并说明了区分前驱 MS 状态的生物学特征。