College of Computer Science and Electronic Engineering, Hunan University, Changsha, Hunan, China.
Donnelly Centre for Cellular and Biomolecular Research, University of Toronto, Toronto, Ontario, Canada.
PLoS Comput Biol. 2022 Feb 24;18(2):e1009863. doi: 10.1371/journal.pcbi.1009863. eCollection 2022 Feb.
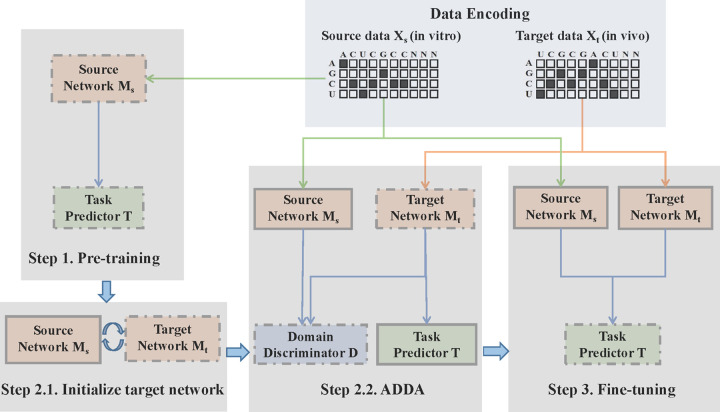
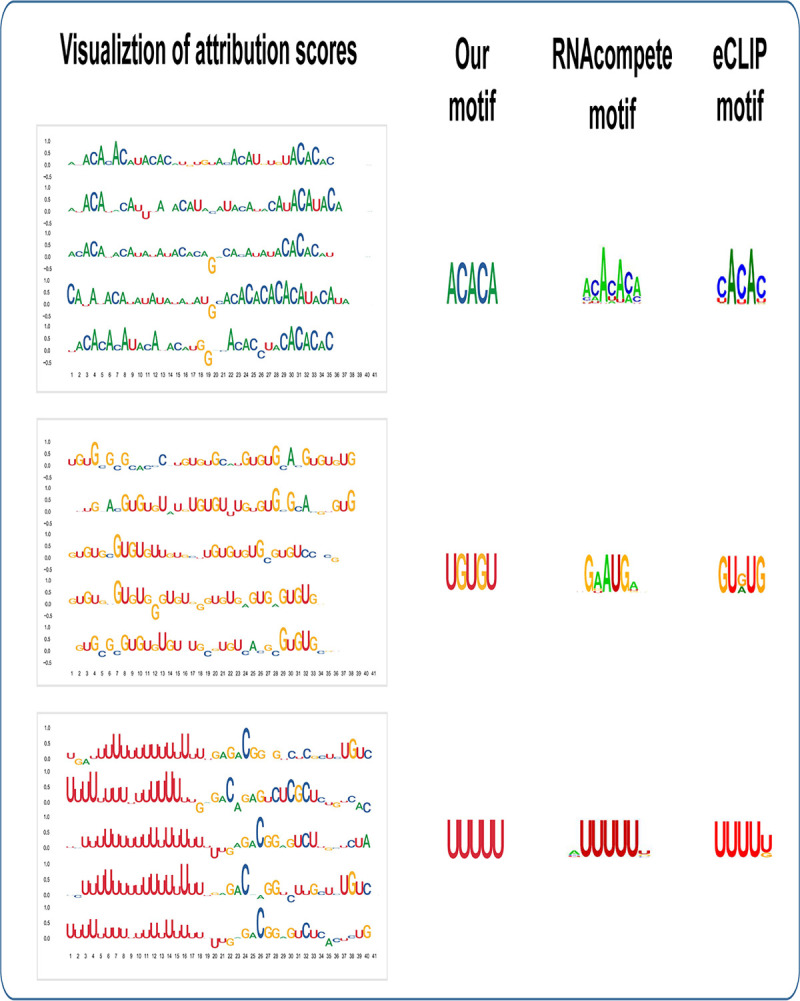
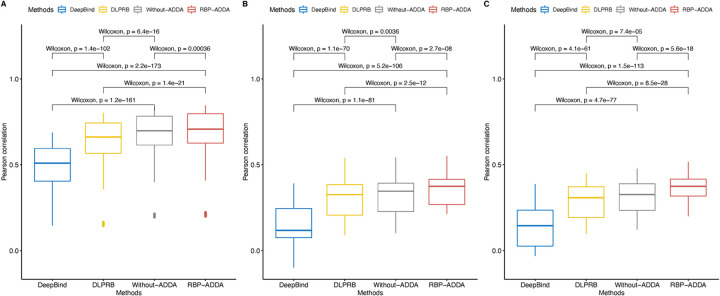
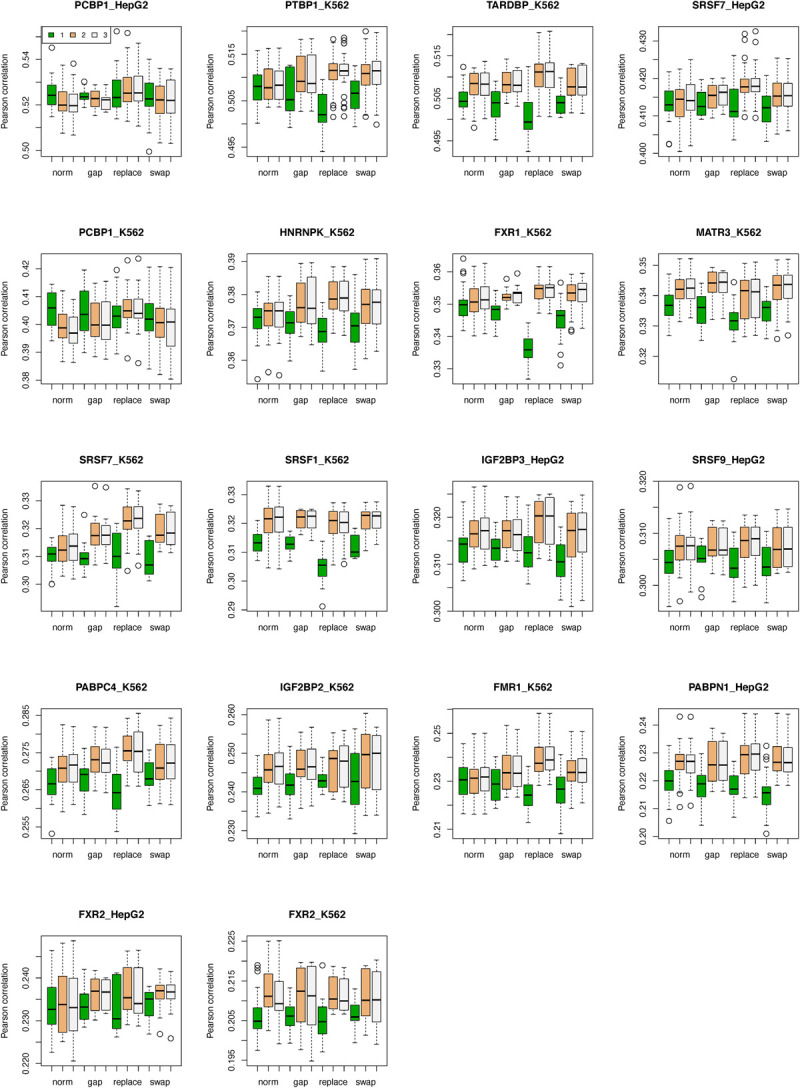
Precise identification of target sites of RNA-binding proteins (RBP) is important to understand their biochemical and cellular functions. A large amount of experimental data is generated by in vivo and in vitro approaches. The binding preferences determined from these platforms share similar patterns but there are discernable differences between these datasets. Computational methods trained on one dataset do not always work well on another dataset. To address this problem which resembles the classic "domain shift" in deep learning, we adopted the adversarial domain adaptation (ADDA) technique and developed a framework (RBP-ADDA) that can extract RBP binding preferences from an integration of in vivo and vitro datasets. Compared with conventional methods, ADDA has the advantage of working with two input datasets, as it trains the initial neural network for each dataset individually, projects the two datasets onto a feature space, and uses an adversarial framework to derive an optimal network that achieves an optimal discriminative predictive power. In the first step, for each RBP, we include only the in vitro data to pre-train a source network and a task predictor. Next, for the same RBP, we initiate the target network by using the source network and use adversarial domain adaptation to update the target network using both in vitro and in vivo data. These two steps help leverage the in vitro data to improve the prediction on in vivo data, which is typically challenging with a lower signal-to-noise ratio. Finally, to further take the advantage of the fused source and target data, we fine-tune the task predictor using both data. We showed that RBP-ADDA achieved better performance in modeling in vivo RBP binding data than other existing methods as judged by Pearson correlations. It also improved predictive performance on in vitro datasets. We further applied augmentation operations on RBPs with less in vivo data to expand the input data and showed that it can improve prediction performances. Lastly, we explored the predictive interpretability of RBP-ADDA, where we quantified the contribution of the input features by Integrated Gradients and identified nucleotide positions that are important for RBP recognition.
准确鉴定 RNA 结合蛋白 (RBP) 的靶标位点对于了解其生化和细胞功能非常重要。大量的实验数据是通过体内和体外方法产生的。从这些平台确定的结合偏好具有相似的模式,但这些数据集之间存在明显的差异。在一个数据集上训练的计算方法并不总是在另一个数据集上有效。为了解决这个类似于深度学习中的经典“域转移”问题,我们采用了对抗性域自适应 (ADDA) 技术,并开发了一个框架 (RBP-ADDA),可以从体内和体外数据集的整合中提取 RBP 结合偏好。与传统方法相比,ADDA 的优势在于可以使用两个输入数据集,因为它为每个数据集单独训练初始神经网络,将两个数据集投影到特征空间,并使用对抗框架得出一个最佳网络,以实现最佳的判别预测能力。在第一步中,对于每个 RBP,我们仅包括体外数据来预训练源网络和任务预测器。接下来,对于同一个 RBP,我们使用源网络启动目标网络,并使用对抗性域自适应来使用体内和体外数据更新目标网络。这两个步骤有助于利用体外数据来提高对体内数据的预测能力,这通常具有挑战性,因为信噪比较低。最后,为了进一步利用融合的源和目标数据的优势,我们使用两种数据来微调任务预测器。我们通过 Pearson 相关性来判断,与其他现有方法相比,RBP-ADDA 在模拟体内 RBP 结合数据方面的性能更好。它还提高了对体外数据集的预测性能。我们进一步对体内数据较少的 RBP 进行扩充操作,以扩大输入数据,并表明它可以提高预测性能。最后,我们探索了 RBP-ADDA 的预测可解释性,通过集成梯度来量化输入特征的贡献,并确定对 RBP 识别重要的核苷酸位置。