College of Culture and Art, Zhejiang Technical Institute of Economics, Hangzhou, Zhejiang, China.
College of Foreign Languages, Zhejiang University of Technology, Hangzhou, Zhejiang, China.
PLoS One. 2022 Feb 25;17(2):e0264552. doi: 10.1371/journal.pone.0264552. eCollection 2022.
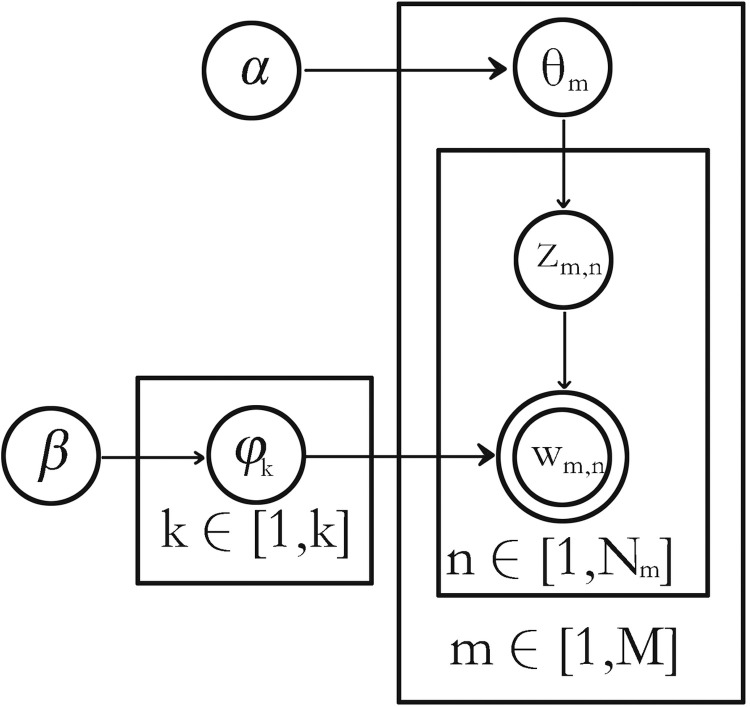
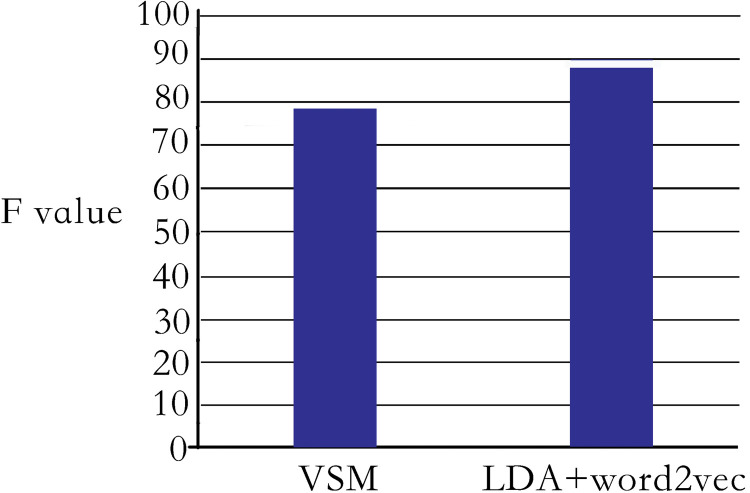
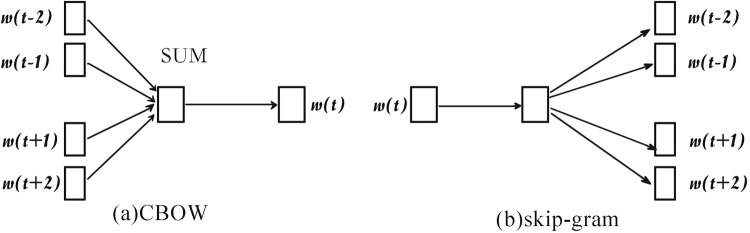
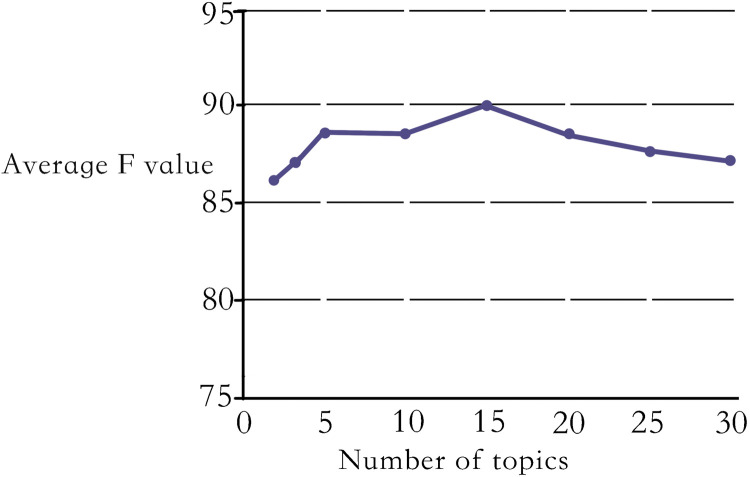
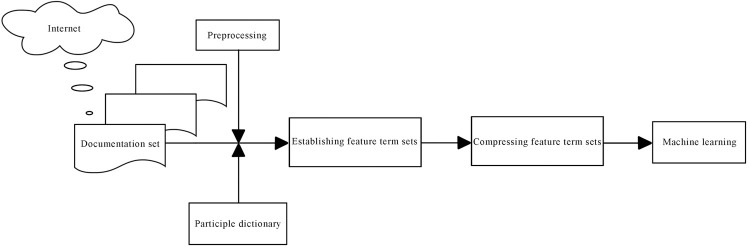
This paper presents an off-topic detection algorithm combining LDA and word2vec aiming at the problem of the lack of accurate and efficient off-topic detection algorithms in the English composition-assisted review system. The algorithm uses the LDA model to model the document and train the document through the word2vec, and uses the semantic relationship between the document’s topics and words to calculate the probability weighted sum for each topic and its feature words in the document, and finally selects the off-topic composition by setting a reasonable threshold. Different F values are obtained by changing the number of topics in the document, and the best number of topics is determined. Experimental results show that the proposed method is more effective than vector space model, can detect more off-topic compositions, and the accuracy is higher, the F value is more than 88%, which realizes the intelligent processing of off-topic detection of composition, and can be effectively applied in English composition teaching.
本文提出了一种结合 LDA 和 word2vec 的离题检测算法,旨在解决英语作文辅助评阅系统中缺乏准确高效的离题检测算法的问题。该算法使用 LDA 模型对文档进行建模,并通过 word2vec 对文档进行训练,利用文档主题和单词之间的语义关系,计算文档中每个主题及其特征词的概率加权和,最后通过设置合理的阈值选择离题作文。通过改变文档中的主题数量得到不同的 F 值,并确定最佳的主题数量。实验结果表明,该方法比向量空间模型更有效,可以检测到更多的离题作文,准确率更高,F 值超过 88%,实现了作文离题检测的智能化处理,可有效应用于英语作文教学中。