PPGI-Informatics Department, UNIRIO Universidade Federal do Estado do Rio de Janeiro, Rio de Janeiro 22290-240, Brazil.
Sensors (Basel). 2022 Mar 16;22(6):2310. doi: 10.3390/s22062310.
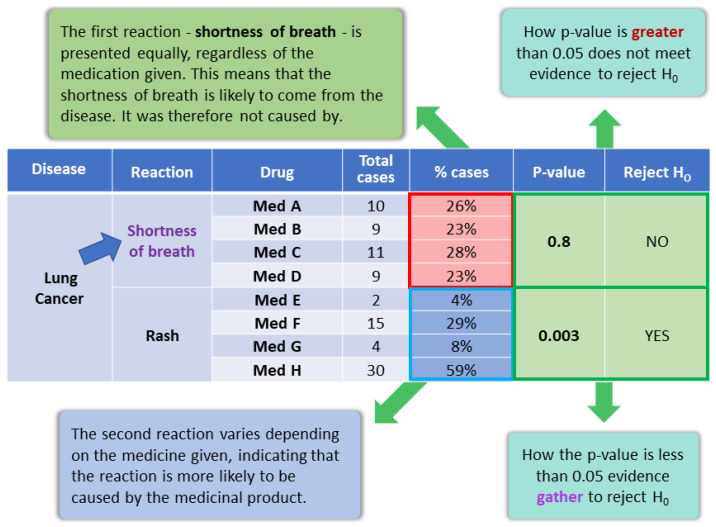
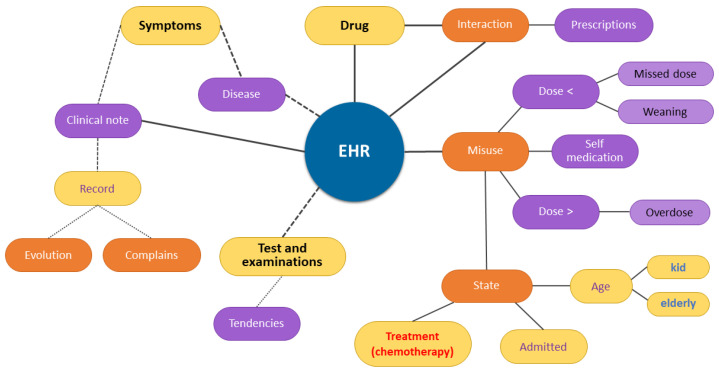
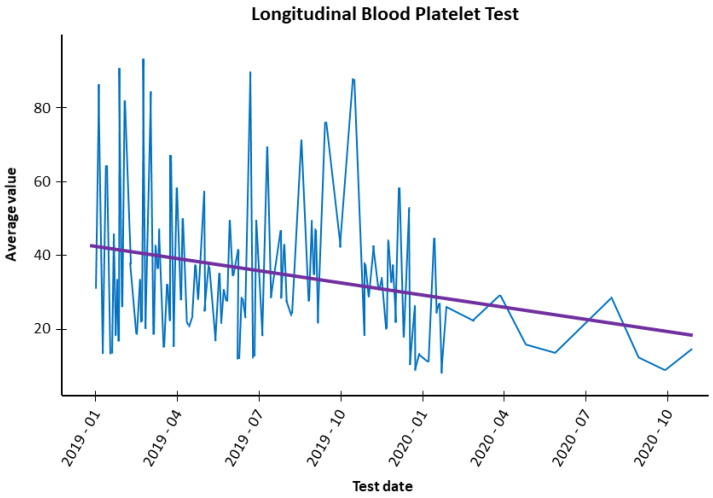
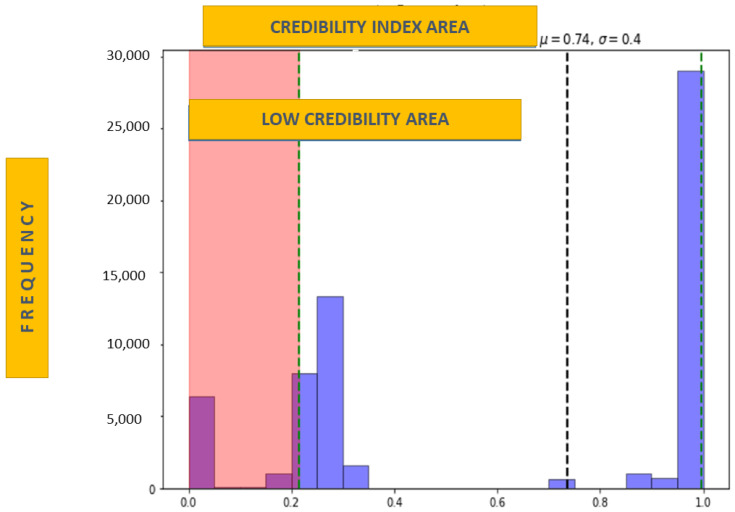
Multisensor information fusion brings challenges such as data heterogeneity, source precision, and the merger of uncertainties that impact the quality of classifiers. A widely used approach for classification problems in a multisensor context is the Dempster-Shafer Theory. This approach considers the beliefs attached to each source to consolidate the information concerning the hypotheses to come up with a classifier with higher precision. Nevertheless, the fundamental premise for using the approach is that sources are independent and that the classification hypotheses are mutually exclusive. Some approaches ignore this premise, which can lead to unreliable results. There are other approaches, based on statistics and machine learning techniques, that expurgate the dependencies or include a discount factor to mitigate the risk of dependencies. We propose a novel approach based on Bayesian net, Pearson's test, and linear regression to adjust the beliefs for more accurate data fusion, mitigating possible correlations or dependencies. We tested our approach by applying it in the domain of adverse drug reactions discovery. The experiment used nine databases containing data from 50,000 active patients of a Brazilian cancer hospital, including clinical exams, laboratory tests, physicians' anamnesis, medical prescriptions, clinical notes, medicine leaflets packages, international classification of disease, and sickness diagnosis models. This study had the hospital's ethical committee approval. A statistically significant improvement in the precision and recall of the results was obtained compared with existing approaches. The results obtained show that the credibility index proposed by the model significantly increases the quality of the evidence generated with the algorithm Random Forest. A benchmark was performed between three datasets, incremented gradually with attributes of a credibility index, obtaining a precision of 92%. Finally, we performed a benchmark with a public base of heart disease, achieving good results.
多传感器信息融合带来了数据异质性、源精度和不确定性合并等挑战,这些挑战会影响分类器的质量。在多传感器环境中,用于分类问题的一种广泛使用的方法是 Dempster-Shafer 理论。该方法考虑了每个源的置信度,以整合有关假设的信息,从而得出具有更高精度的分类器。然而,使用该方法的基本前提是源是独立的,并且分类假设是互斥的。一些方法忽略了这个前提,这可能导致不可靠的结果。还有其他一些基于统计和机器学习技术的方法,可以消除依赖性或包含折扣因素来降低依赖性的风险。我们提出了一种基于贝叶斯网络、皮尔逊检验和线性回归的新方法来调整置信度,以实现更准确的数据融合,减轻可能的相关性或依赖性。我们通过将其应用于药物不良反应发现领域来测试我们的方法。该实验使用了包含巴西癌症医院 50000 名活跃患者的九个数据库的数据,包括临床检查、实验室测试、医生病史、医学处方、临床记录、药品说明书包装、国际疾病分类和疾病诊断模型。本研究得到了医院伦理委员会的批准。与现有方法相比,该方法在精度和召回率方面都得到了显著提高。得到的结果表明,模型提出的可信度指数显著提高了算法随机森林生成的证据的质量。在三个数据集之间进行了基准测试,随着可信度指数的属性逐渐增加,获得了 92%的精度。最后,我们使用公开的心脏病数据库进行了基准测试,取得了良好的效果。