School of Economics and Management, Xi'an University of Technology, Xi'an 710054, China.
Comput Intell Neurosci. 2022 Apr 12;2022:1086945. doi: 10.1155/2022/1086945. eCollection 2022.
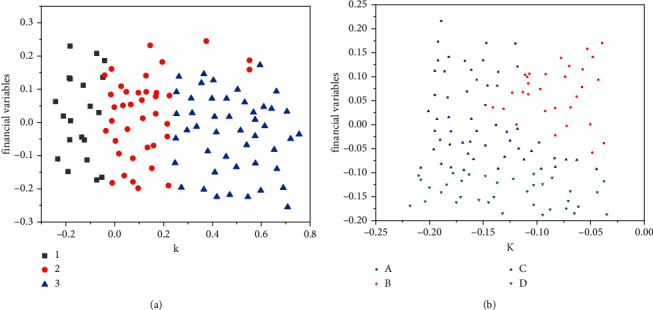
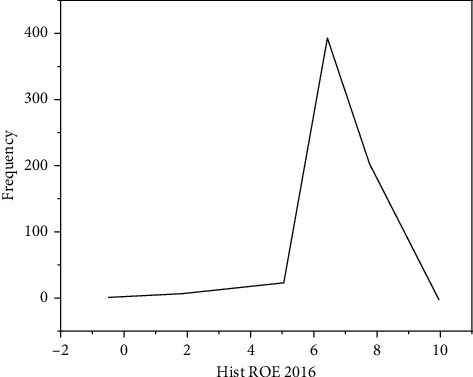
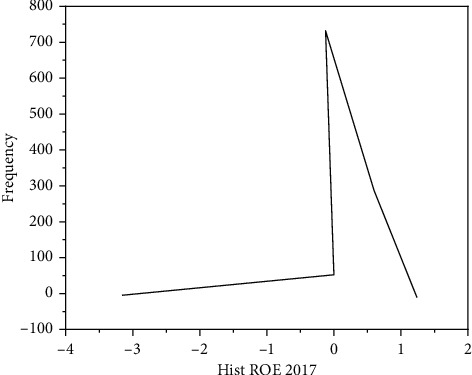
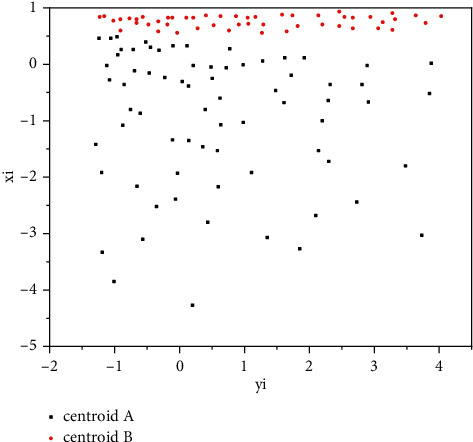
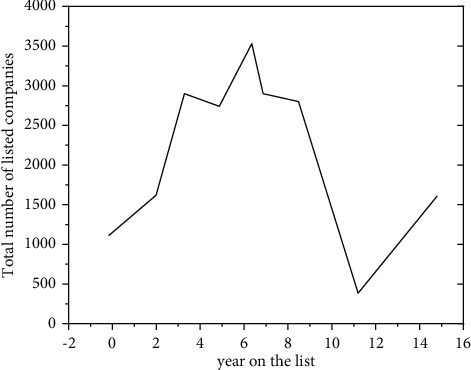
In order to solve the problem that corporate financial risks seriously affect the healthy development of enterprises, credit institutions, securities investors, and even the whole of China, the K-means clustering algorithm, the risk screening process, and the Gaussian mixture clustering algorithm, the risk screening process, are proposed; experiments have shown that although the number of high-risk companies selected by the K-means algorithm is small, only 9% of the full sample, the high-risk cluster can contain nearly 30% of the new "special treatment" companies. If the time period is extended to the next 5 years, this proportion will be higher. Finally we found that if the prediction of "special handling" events is used as the criterion for evaluating high-risk clusters, then K-means clustering can effectively screen out those risky companies that need to be treated with caution by investors. The validity of the experiment is verified.
为了解决企业财务风险严重影响企业健康发展、信用机构、证券投资者,甚至整个中国的问题,提出了 K 均值聚类算法、风险筛选过程和高斯混合聚类算法、风险筛选过程;实验表明,尽管 K 均值算法选择的高风险公司数量很少,仅占全样本的 9%,但高风险聚类可以包含近 30%的新“特别处理”公司。如果延长时间期限为接下来的 5 年,这个比例将会更高。最后我们发现,如果使用“特别处理”事件的预测作为评估高风险聚类的标准,那么 K 均值聚类可以有效地筛选出那些需要投资者谨慎对待的风险公司。实验的有效性得到了验证。