Department of Information Engineering, University of Pisa, Pisa 56122, Italy.
Comput Intell Neurosci. 2022 May 11;2022:9485933. doi: 10.1155/2022/9485933. eCollection 2022.
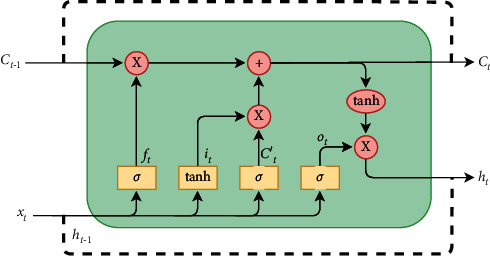
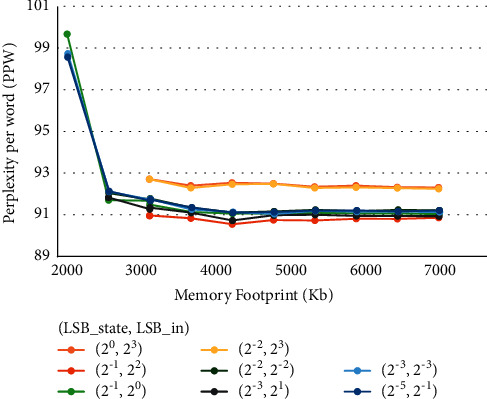
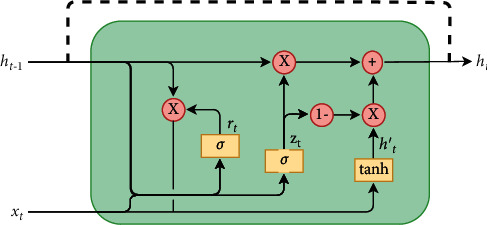
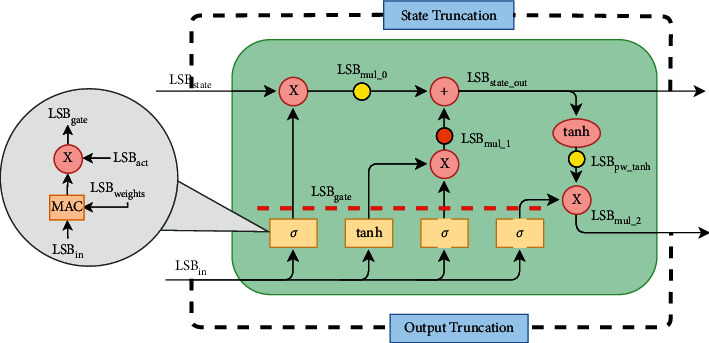
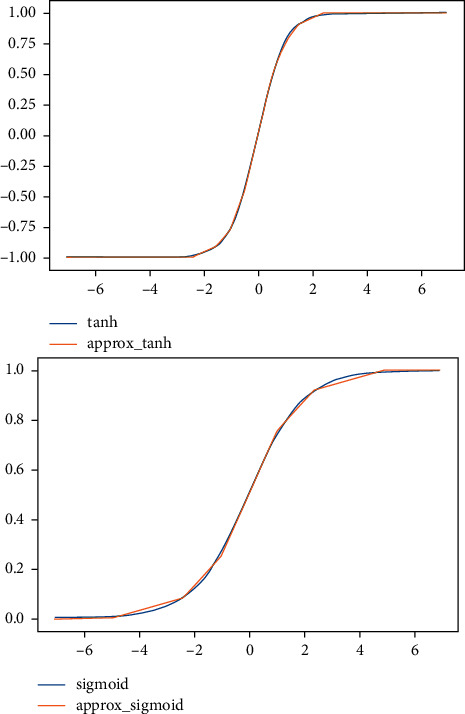
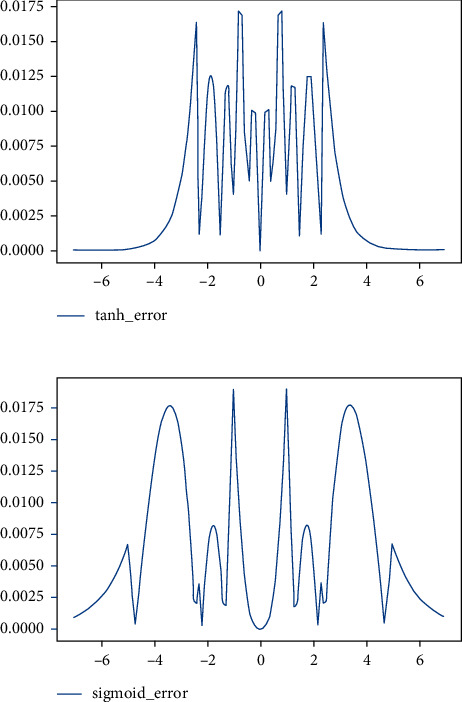
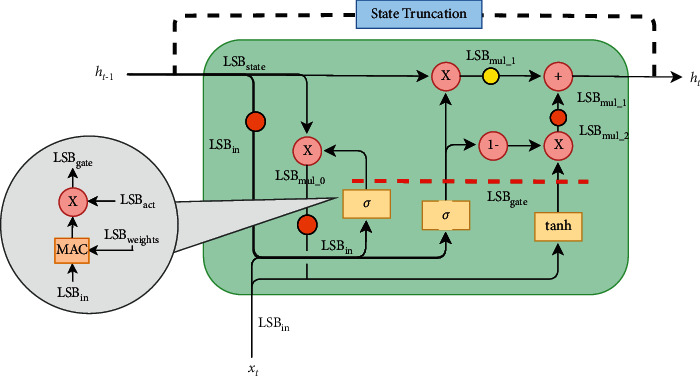
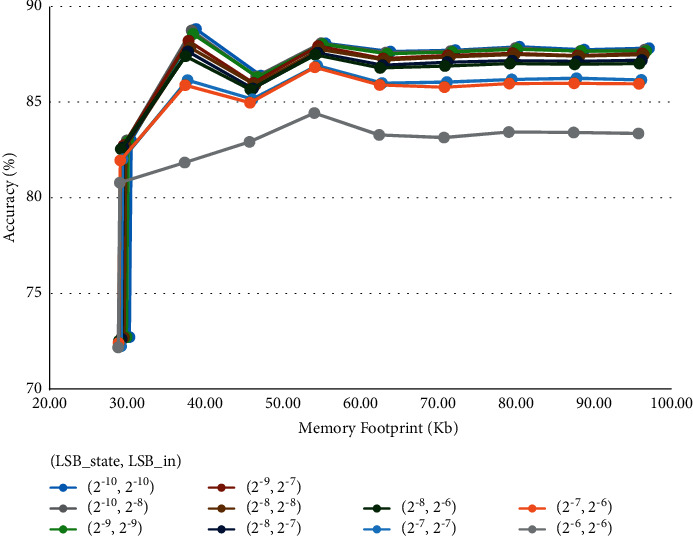
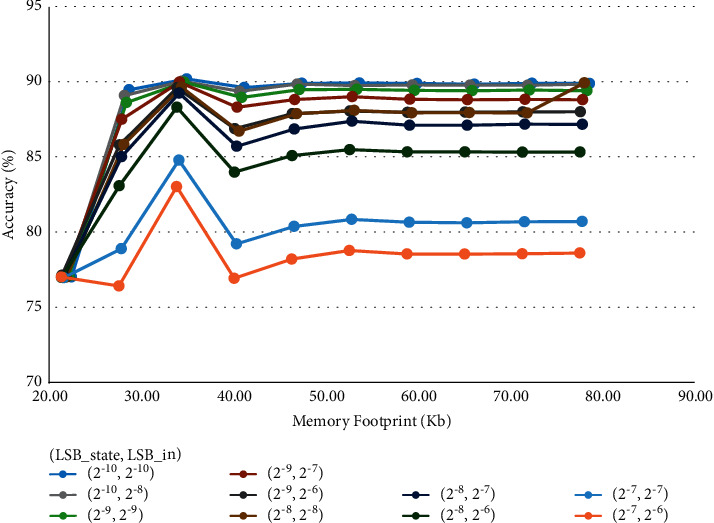
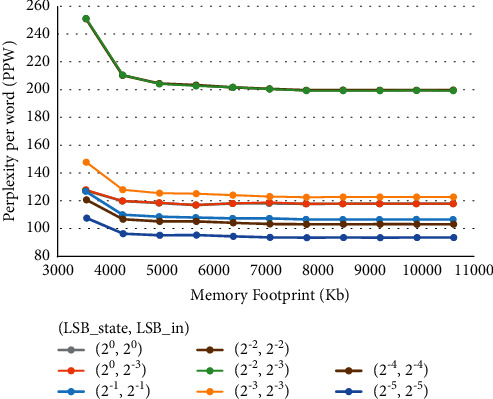
Recurrent Neural Networks (RNNs) have become important tools for tasks such as speech recognition, text generation, or natural language processing. However, their inference may involve up to billions of operations and their large number of parameters leads to large storage size and runtime memory usage. These reasons impede the adoption of these models in real-time, on-the-edge applications. Field-Programmable Gate Arrays (FPGAs) and Application-Specific Integrated Circuits (ASICs) have emerged as promising solutions for the hardware acceleration of these algorithms, thanks to their degree of customization of compute data paths and memory subsystems, which makes them take the maximum advantage from compression techniques for what concerns area, timing, and power consumption. In contrast to the extensive study in compression and quantization for plain feed forward neural networks in the literature, little attention has been paid to reducing the computational resource requirements of RNNs. This work proposes a new effective methodology for the post-training quantization of RNNs. In particular, we focus on the quantization of Long Short-Term Memory (LSTM) RNNs and Gated Recurrent Unit (GRU) RNNs. The proposed quantization strategy is meant to be a detailed guideline toward the design of custom hardware accelerators for LSTM/GRU-based algorithms to be implemented on FPGA or ASIC devices using fixed-point arithmetic only. We applied our methods to LSTM/GRU models pretrained on the IMDb sentiment classification dataset and Penn TreeBank language modelling dataset, thus comparing each quantized model to its floating-point counterpart. The results show the possibility to achieve up to 90% memory footprint reduction in both cases, obtaining less than 1% loss in accuracy and even a slight improvement in the Perplexity per word metric, respectively. The results are presented showing the various trade-offs between memory footprint reduction and accuracy changes, demonstrating the benefits of the proposed methodology even in comparison with other works from the literature.
递归神经网络 (RNN) 已成为语音识别、文本生成或自然语言处理等任务的重要工具。然而,它们的推理可能涉及多达数十亿次的操作,并且它们的大量参数导致了大的存储大小和运行时内存使用。这些原因阻碍了这些模型在实时、边缘应用中的采用。现场可编程门阵列 (FPGA) 和专用集成电路 (ASIC) 已成为这些算法硬件加速的有前途的解决方案,这要归功于它们对计算数据路径和存储子系统的高度定制化,这使得它们能够最大限度地利用压缩技术来节省面积、时间和功耗。与文献中对纯前馈神经网络的压缩和量化的广泛研究相比,对 RNN 的计算资源需求减少的关注较少。这项工作提出了一种新的 RNN 后训练量化的有效方法。特别是,我们专注于长短期记忆 (LSTM) RNN 和门控循环单元 (GRU) RNN 的量化。所提出的量化策略旨在为基于 LSTM/GRU 的算法的定制硬件加速器的设计提供详细的指导,这些算法将仅使用定点算术在 FPGA 或 ASIC 设备上实现。我们将我们的方法应用于在 IMDb 情感分类数据集和 Penn TreeBank 语言建模数据集上预训练的 LSTM/GRU 模型,从而将每个量化模型与浮点对应模型进行比较。结果表明,在两种情况下,都有可能将内存占用减少 90%,同时准确率损失不到 1%,甚至在每个单词的困惑度指标上略有提高。结果显示了在内存占用减少和准确性变化之间的各种权衡,即使与文献中的其他工作相比,也证明了所提出的方法的优势。