Department of Mathematics and Physics, Catholic University of the Sacred Heart, Faculty of Mathematical, Physical and Natural Sciences, via della Garzetta 48, Brescia 25133, Italy.
Department of Sciences, Roma Tre University, viale Marconi 446, Roma, Lazio 00146, Italy.
Database (Oxford). 2022 Jun 27;2022. doi: 10.1093/database/baac044.
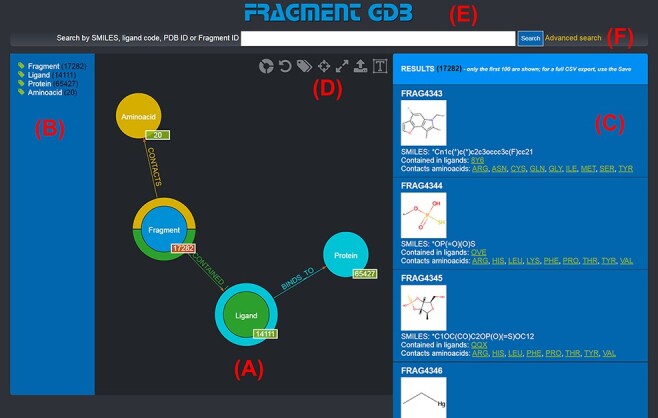
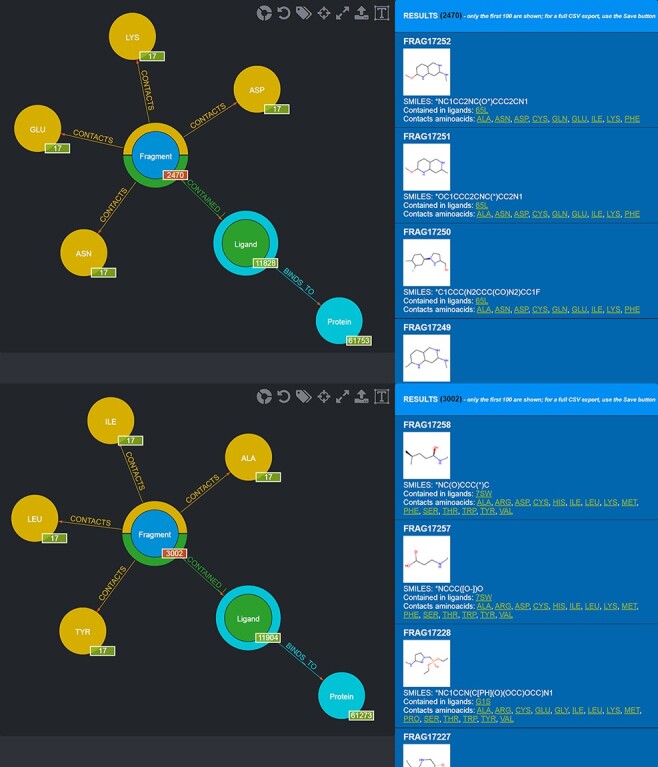
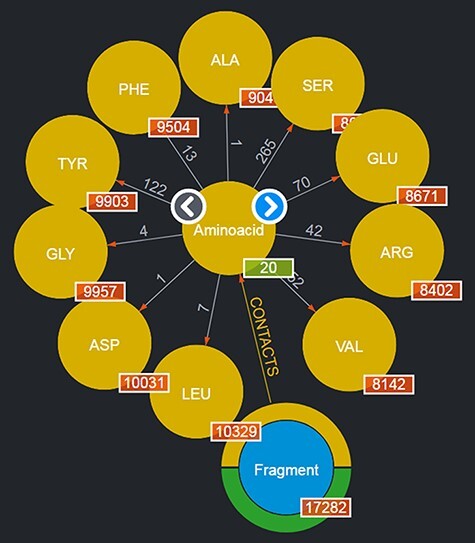
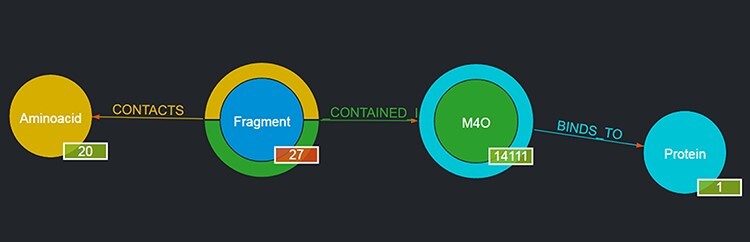
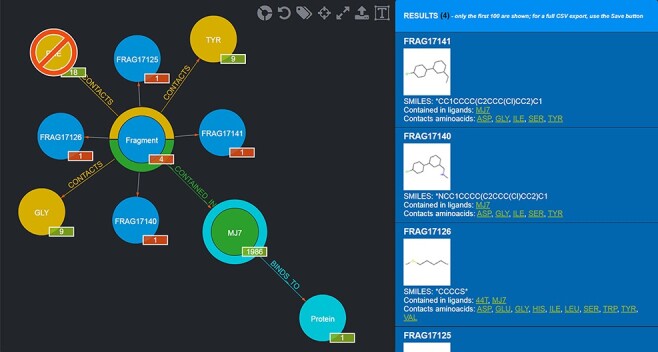
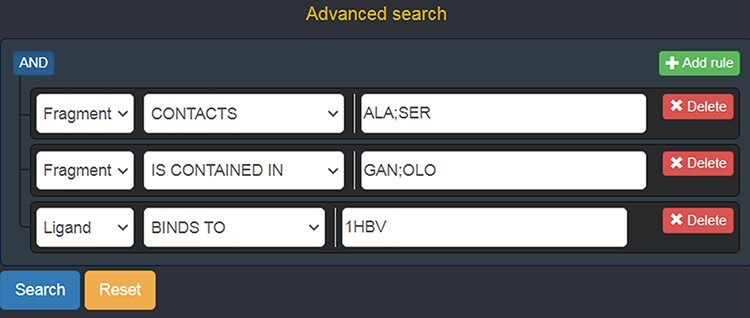
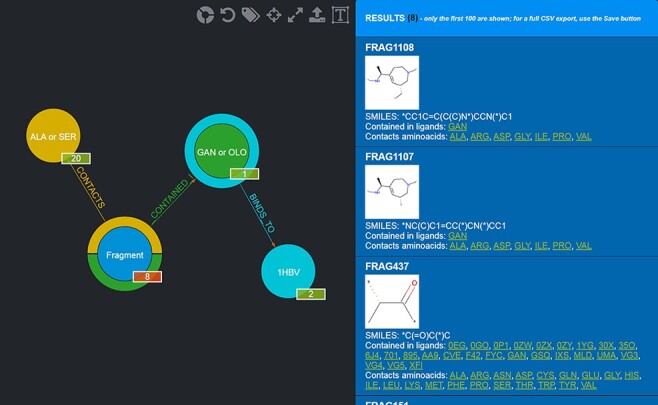
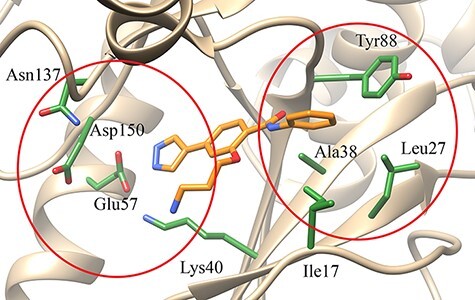
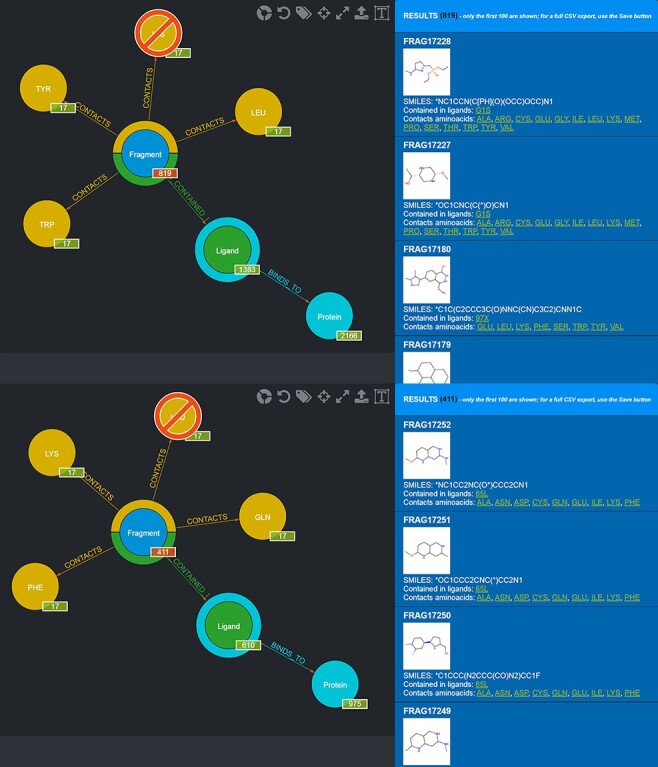
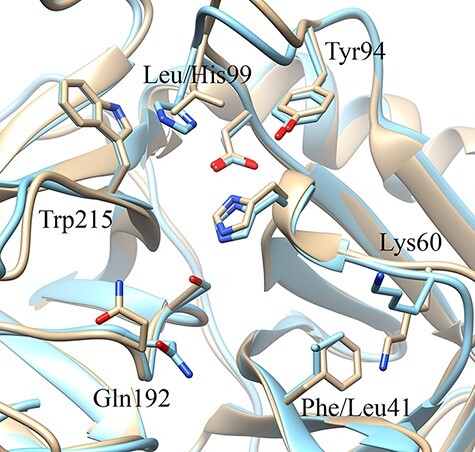
This work presents Fragment Graph DataBase (FGDB), a graph database of ligand fragments extracted and generated from the protein entries available in the Protein Data Bank (PDB). FGDB is meant to support and elicit campaigns of fragment-based drug design, by enabling users to query it in order to construct ad hoc, target-specific libraries. In this regard, the database features more than 17 000 fragments, typically small, highly soluble and chemically stable molecules expressed via their canonical Simplified Molecular Input Line Entry System (SMILES) representation. For these fragments, the database provides information related to their contact frequencies with the amino acids, the ligands they are contained in and the proteins the latter bind to. The graph database can be queried via standard web forms and textual searches by a number of identifiers (SMILES, ligand and protein PDB ids) as well as via graphical queries that can be performed against the graph itself, providing users with an intuitive and effective view upon the underlying biological entities. Further search mechanisms via advanced conjunctive/disjunctive/negated textual queries are also possible, in order to allow scientists to look for specific relationships and export their results for further studies. This work also presents two sample use cases where maternal embryonic leucine zipper kinase and mesotrypsin are used as a target, being proteins of high biomedical relevance for the development of cancer therapies. Database URL: http://biochimica3.bio.uniroma3.it/fragments-web/.
这项工作提出了 Fragment Graph DataBase(FGDB),这是一个从蛋白质数据库(PDB)中提取和生成的配体片段的图形数据库。FGDB 旨在支持和引发基于片段的药物设计活动,使用户能够查询它以构建特定于目标的库。在这方面,该数据库拥有超过 17000 个片段,这些片段通常是小的、高水溶性和化学稳定性的分子,通过它们的规范简化分子输入行输入系统(SMILES)表示法来表达。对于这些片段,数据库提供了与其与氨基酸的接触频率、包含它们的配体以及它们所结合的蛋白质有关的信息。图形数据库可以通过标准的 Web 表单和通过许多标识符(SMILES、配体和蛋白质 PDB id)进行的文本搜索进行查询,也可以通过针对图形本身执行的图形查询进行查询,为用户提供对底层生物实体的直观和有效的视图。还可以通过高级的联合/分离/否定文本查询来进行其他搜索机制,以便科学家可以寻找特定的关系并将结果导出用于进一步研究。这项工作还介绍了两个示例用例,即母体胚胎亮氨酸拉链激酶和 mesotrypsin,它们是癌症治疗开发中具有高生物医学相关性的蛋白质。数据库网址:http://biochimica3.bio.uniroma3.it/fragments-web/。