Efficient Algorithms for Omics Data, Max Planck Institute for Molecular Genetics, Berlin, Germany.
Algorithmic Bioinformatics, Institute for Bioinformatics, FU Berlin, 14195 Berlin, Germany.
Bioinformatics. 2022 Sep 2;38(17):4100-4108. doi: 10.1093/bioinformatics/btac492.
The ever-growing size of sequencing data is a major bottleneck in bioinformatics as the advances of hardware development cannot keep up with the data growth. Therefore, an enormous amount of data is collected but rarely ever reused, because it is nearly impossible to find meaningful experiments in the stream of raw data.
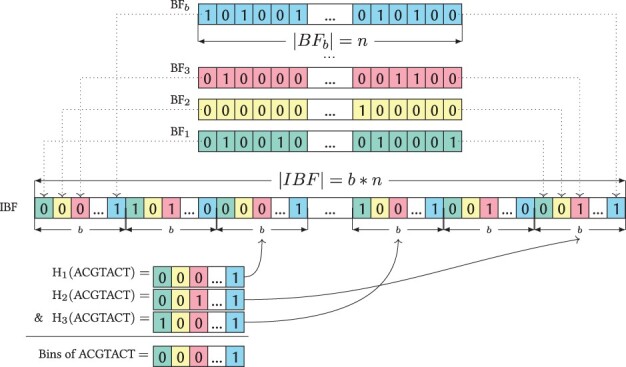
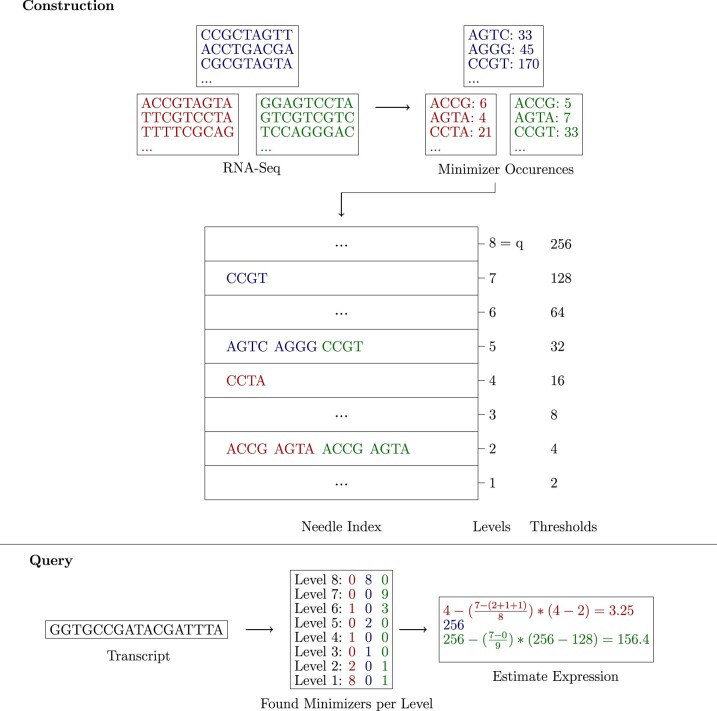
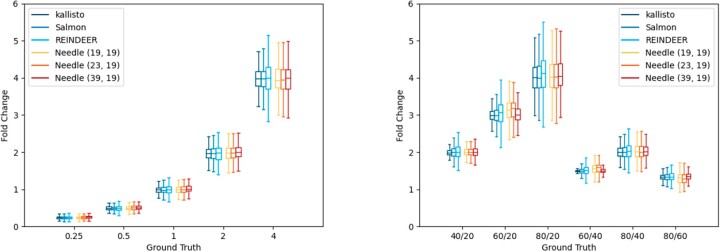
As a solution, we propose Needle, a fast and space-efficient index which can be built for thousands of experiments in <2 h and can estimate the quantification of a transcript in these experiments in seconds, thereby outperforming its competitors. The basic idea of the Needle index is to create multiple interleaved Bloom filters that each store a set of representative k-mers depending on their multiplicity in the raw data. This is then used to quantify the query.
https://github.com/seqan/needle.
Supplementary data are available at Bioinformatics online.
测序数据的规模不断增长,这是生物信息学中的一个主要瓶颈,因为硬件发展的进步跟不上数据的增长。因此,尽管收集了大量的数据,但由于几乎不可能从原始数据中找到有意义的实验,这些数据很少被重复使用。
作为解决方案,我们提出了 Needle,这是一种快速且节省空间的索引,可以在 <2 小时内为数千个实验构建,并可以在几秒钟内估计这些实验中转录本的定量,从而优于其竞争对手。Needle 索引的基本思想是创建多个交错的布隆过滤器,每个过滤器根据其在原始数据中的多重性存储一组代表 k-mer。然后,这用于量化查询。
https://github.com/seqan/needle。
补充数据可在 Bioinformatics 在线获得。