Gao Jinlong, He Jiale, Zhang Fangfei, Xiao Qi, Cai Xue, Yi Xiao, Zheng Siqi, Zhang Ying, Wang Donglian, Zhu Guangjun, Wang Jing, Shen Bo, Ralser Markus, Guo Tiannan, Zhu Yi
Westlake Laboratory of Life Sciences and Biomedicine, Key Laboratory of Structural Biology of Zhejiang Province, School of Life Sciences, Westlake University, Hangzhou, Zhejiang, China.
Institute of Basic Medical Sciences, Westlake Institute for Advanced Study, Hangzhou, Zhejiang, China.
Clin Proteomics. 2022 Aug 11;19(1):31. doi: 10.1186/s12014-022-09370-0.
Classification of disease severity is crucial for the management of COVID-19. Several studies have shown that individual proteins can be used to classify the severity of COVID-19. Here, we aimed to investigate whether integrating four types of protein context data, namely, protein complexes, stoichiometric ratios, pathways and network degrees will improve the severity classification of COVID-19.
We performed machine learning based on three previously published datasets. The first was a SWATH (sequential window acquisition of all theoretical fragment ion spectra) MS (mass spectrometry) based proteomic dataset. The second was a TMTpro 16plex labeled shotgun proteomics dataset. The third was a SWATH dataset of an independent patient cohort.
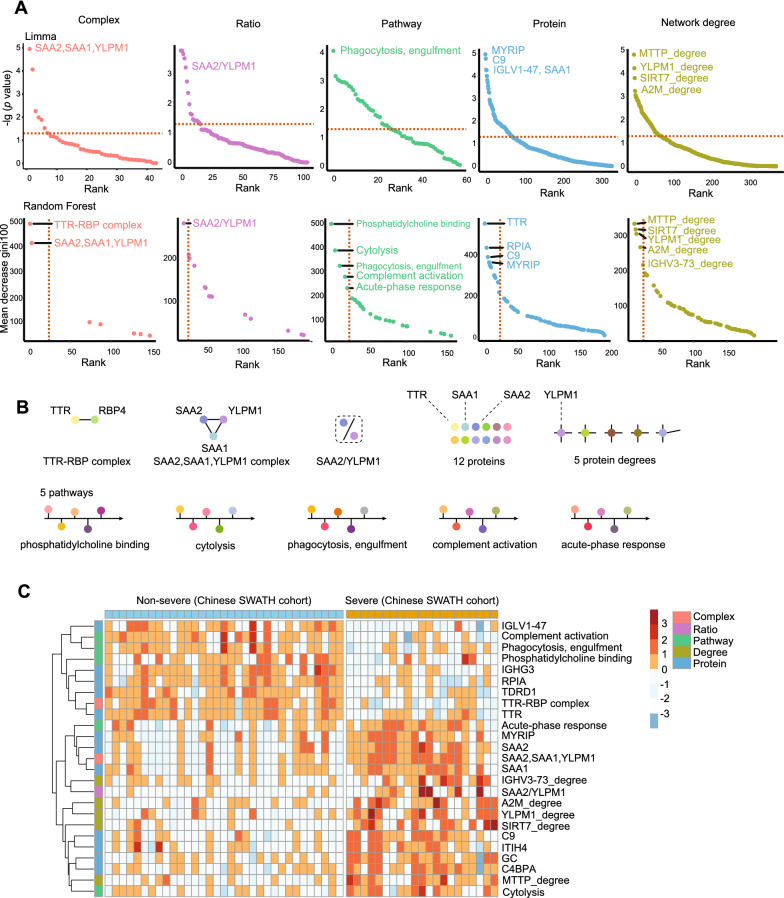
Besides twelve proteins, machine learning also prioritized two complexes, one stoichiometric ratio, five pathways, and five network degrees, resulting a 25-feature panel. As a result, a model based on the 25 features led to effective classification of severe cases with an AUC of 0.965, outperforming the models with proteins only. Complement component C9, transthyretin (TTR) and TTR-RBP (transthyretin-retinol binding protein) complex, the stoichiometric ratio of SAA2 (serum amyloid A proteins 2)/YLPM1 (YLP Motif Containing 1), and the network degree of SIRT7 (Sirtuin 7) and A2M (alpha-2-macroglobulin) were highlighted as potential markers by this classifier. This classifier was further validated with a TMT-based proteomic data set from the same cohort (test dataset 1) and an independent SWATH-based proteomic data set from Germany (test dataset 2), reaching an AUC of 0.900 and 0.908, respectively. Machine learning models integrating protein context information achieved higher AUCs than models with only one feature type.
Our results show that the integration of protein context including protein complexes, stoichiometric ratios, pathways, network degrees, and proteins improves phenotype prediction.
疾病严重程度分类对于新冠病毒病(COVID-19)的管理至关重要。多项研究表明,单个蛋白质可用于对COVID-19的严重程度进行分类。在此,我们旨在研究整合四种类型的蛋白质背景数据,即蛋白质复合物、化学计量比、信号通路和网络度,是否会改善COVID-19的严重程度分类。
我们基于三个先前发表的数据集进行机器学习。第一个是基于SWATH(所有理论碎片离子光谱的顺序窗口采集)质谱(MS)的蛋白质组学数据集。第二个是TMTpro 16plex标记的鸟枪法蛋白质组学数据集。第三个是一个独立患者队列的SWATH数据集。
除了12种蛋白质外,机器学习还对两种复合物、一种化学计量比、五条信号通路和五个网络度进行了优先级排序,从而形成了一个包含25个特征的组合。结果,基于这25个特征的模型能够有效分类重症病例,曲线下面积(AUC)为0.965,优于仅使用蛋白质的模型。补体成分C9、转甲状腺素蛋白(TTR)和TTR-RBP(转甲状腺素蛋白-视黄醇结合蛋白)复合物、血清淀粉样蛋白A2(SAA2)/含YLP基序1(YLPM1)的化学计量比,以及沉默调节蛋白7(SIRT7)和α-2-巨球蛋白(A2M)的网络度被该分类器突出显示为潜在标志物。该分类器在来自同一队列的基于TMT的蛋白质组学数据集(测试数据集1)和来自德国的独立的基于SWATH的蛋白质组学数据集(测试数据集2)中得到进一步验证,AUC分别达到0.900和0.908。整合蛋白质背景信息的机器学习模型比仅使用一种特征类型的模型具有更高的AUC。
我们的结果表明,整合包括蛋白质复合物、化学计量比、信号通路、网络度和蛋白质在内的蛋白质背景信息可改善表型预测。