College of Civil Aviation, Nanjing University of Aeronautics and Astronautics, Nanjing 210016, China.
Institute of Computer Application, China Academy of Engineering Physics, Mianyang 621900, China.
Comput Intell Neurosci. 2022 Jul 31;2022:4987639. doi: 10.1155/2022/4987639. eCollection 2022.
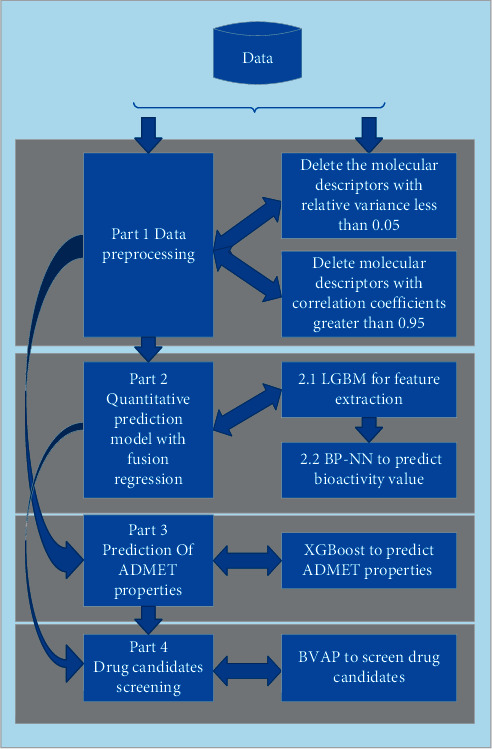
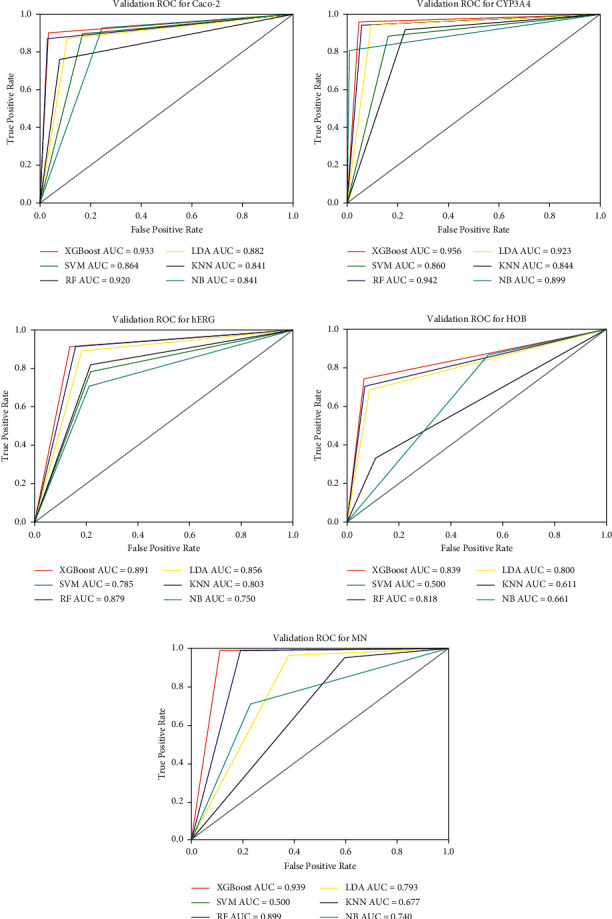
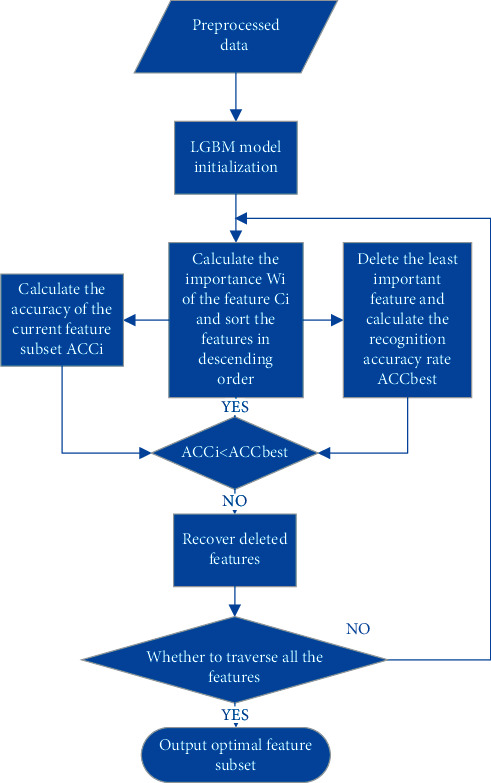
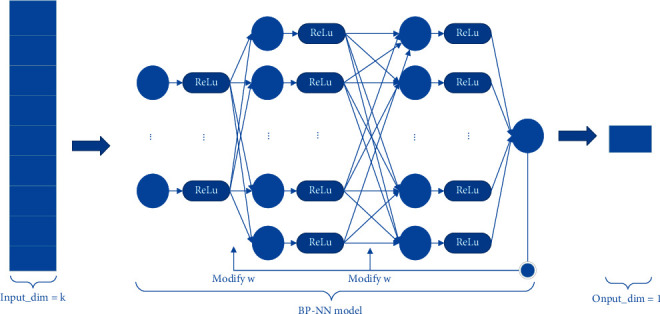
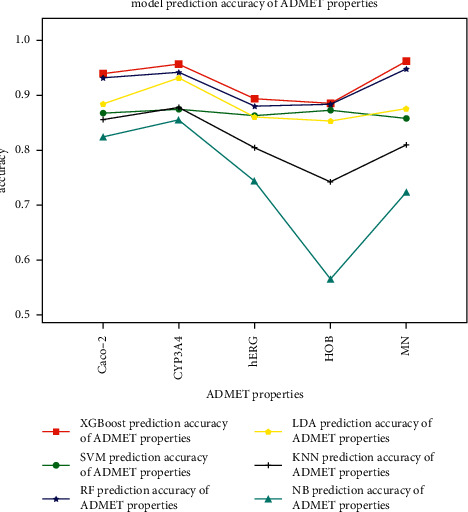
Performance prediction based on candidates and screening based on predicted performance value are the core of product development. For example, the performance prediction and screening of equipment components and parts are an important guarantee for the reliability of equipment products. The prediction and screening of drug bioactivity value and performance are the keys to pharmaceutical product development. The main reasons for the failure of pharmaceutical discovery are the low bioactivity of the candidate compounds and the deficiencies in their efficacy and safety, which are related to the absorption, distribution, metabolism, excretion, and toxicity (ADMET) of the compounds. Therefore, it is very necessary to quickly and effectively perform systematic bioactivity value prediction and ADMET property evaluation for candidate compounds in the early stage of drug discovery. In this paper, a data-driven pharmaceutical products screening prediction model is proposed to screen drug candidates with higher bioactivity value and better ADMET properties. First, a quantitative prediction method for bioactivity value is proposed using the fusion regression of LGBM and neural network based on backpropagation (BP-NN). Then, the ADMET properties prediction method is proposed using XGBoost. According to the predicted bioactivity value and ADMET properties, the BVAP method is defined to screen the drug candidates. And the screening model is validated on the dataset of antagonized Er active compounds, in which the mean square error (MSE) of fusion regression is 1.1496, the XGBoost prediction accuracy of ADMET properties are 94.0% for Caco-2, 95.7% for CYP3A4, 89.4% for HERG, 88.6% for hob, and 96.2% for Mn. Compared with the commonly used methods for ADMET properties such as SVM, RF, KNN, LDA, and NB, the XGBoost in this paper has the highest prediction accuracy and AUC value, which has better guiding significance and can help screen pharmaceutical product candidates with good bioactivity, pharmacokinetic properties, and safety.
基于候选物的性能预测和基于预测性能值的筛选是产品开发的核心。例如,设备部件和零件的性能预测和筛选是设备产品可靠性的重要保证。药物生物活性值和性能的预测和筛选是药物产品开发的关键。药物发现失败的主要原因是候选化合物的生物活性低,以及其功效和安全性的不足,这与化合物的吸收、分布、代谢、排泄和毒性(ADMET)有关。因此,在药物发现的早期阶段,非常有必要快速有效地对候选化合物进行系统的生物活性值预测和 ADMET 性质评估。本文提出了一种基于数据驱动的药物产品筛选预测模型,以筛选具有更高生物活性值和更好 ADMET 性质的药物候选物。首先,提出了一种基于 LGBM 和基于反向传播(BP-NN)的神经网络融合回归的生物活性值定量预测方法。然后,提出了一种基于 XGBoost 的 ADMET 性质预测方法。根据预测的生物活性值和 ADMET 性质,定义了 BVAP 方法来筛选药物候选物。并在拮抗 Er 活性化合物数据集上对筛选模型进行了验证,其中融合回归的均方误差(MSE)为 1.1496,XGBoost 对 ADMET 性质的预测准确率分别为 Caco-2 94.0%、CYP3A4 95.7%、HERG 89.4%、HOB 88.6%和 Mn 96.2%。与常用于 ADMET 性质预测的方法(如 SVM、RF、KNN、LDA 和 NB)相比,本文中的 XGBoost 具有最高的预测准确性和 AUC 值,具有更好的指导意义,可以帮助筛选具有良好生物活性、药代动力学性质和安全性的药物产品候选物。