Sung Sheng-Feng, Sung Kuan-Lin, Pan Ru-Chiou, Lee Pei-Ju, Hu Ya-Han
Division of Neurology, Department of Internal Medicine, Ditmanson Medical Foundation Chiayi Christian Hospital, Chiayi City, Taiwan.
Department of Nursing, Min-Hwei Junior College of Health Care Management, Tainan, Taiwan.
Front Cardiovasc Med. 2022 Jul 29;9:941237. doi: 10.3389/fcvm.2022.941237. eCollection 2022.
Timely detection of atrial fibrillation (AF) after stroke is highly clinically relevant, aiding decisions on the optimal strategies for secondary prevention of stroke. In the context of limited medical resources, it is crucial to set the right priorities of extended heart rhythm monitoring by stratifying patients into different risk groups likely to have newly detected AF (NDAF). This study aimed to develop an electronic health record (EHR)-based machine learning model to assess the risk of NDAF in an early stage after stroke.
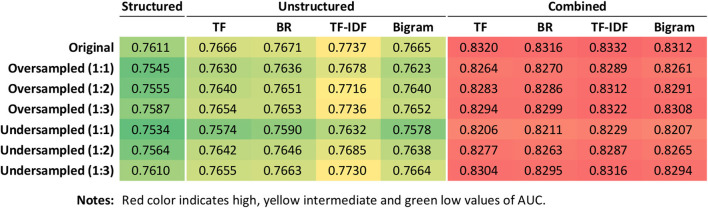
Linked data between a hospital stroke registry and a deidentified research-based database including EHRs and administrative claims data was used. Demographic features, physiological measurements, routine laboratory results, and clinical free text were extracted from EHRs. The extreme gradient boosting algorithm was used to build the prediction model. The prediction performance was evaluated by the C-index and was compared to that of the AS5F and CHASE-LESS scores.
The study population consisted of a training set of 4,064 and a temporal test set of 1,492 patients. During a median follow-up of 10.2 months, the incidence rate of NDAF was 87.0 per 1,000 person-year in the test set. On the test set, the model based on both structured and unstructured data achieved a C-index of 0.840, which was significantly higher than those of the AS5F (0.779, = 0.023) and CHASE-LESS (0.768, = 0.005) scores.
It is feasible to build a machine learning model to assess the risk of NDAF based on EHR data available at the time of hospital admission. Inclusion of information derived from clinical free text can significantly improve the model performance and may outperform risk scores developed using traditional statistical methods. Further studies are needed to assess the clinical usefulness of the prediction model.
卒中后及时检测心房颤动(AF)具有高度临床相关性,有助于决定卒中二级预防的最佳策略。在医疗资源有限的情况下,通过将患者分层为可能新检测出AF(NDAF)的不同风险组来确定延长心律监测的正确优先级至关重要。本研究旨在开发一种基于电子健康记录(EHR)的机器学习模型,以在卒中后早期评估NDAF风险。
使用医院卒中登记处与一个包含EHR和行政索赔数据的去识别化研究型数据库之间的关联数据。从EHR中提取人口统计学特征、生理测量值、常规实验室结果和临床自由文本。采用极端梯度提升算法构建预测模型。通过C指数评估预测性能,并与AS5F和CHASE-LESS评分的预测性能进行比较。
研究人群包括4064例患者的训练集和1492例患者的时间性测试集。在中位随访10.2个月期间,测试集中NDAF的发病率为每1000人年87.0例。在测试集上,基于结构化和非结构化数据的模型C指数为0.840,显著高于AS5F评分(0.779,P = 0.023)和CHASE-LESS评分(0.768,P = 0.005)。
基于入院时可用的EHR数据构建机器学习模型来评估NDAF风险是可行的。纳入临床自由文本衍生的信息可显著提高模型性能,且可能优于使用传统统计方法开发的风险评分。需要进一步研究来评估预测模型的临床实用性。