Department of Library and Information Science, Yonsei University, Seoul, South Korea.
Department of Digital Analytics, Yonsei University, Seoul, South Korea.
BMC Med Inform Decis Mak. 2022 Sep 6;22(1):234. doi: 10.1186/s12911-022-01977-5.
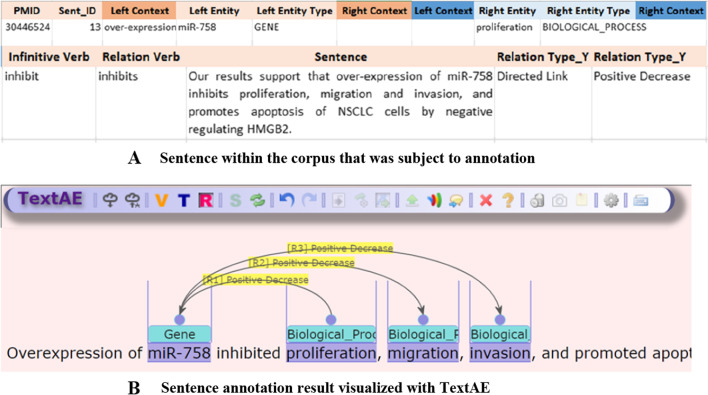
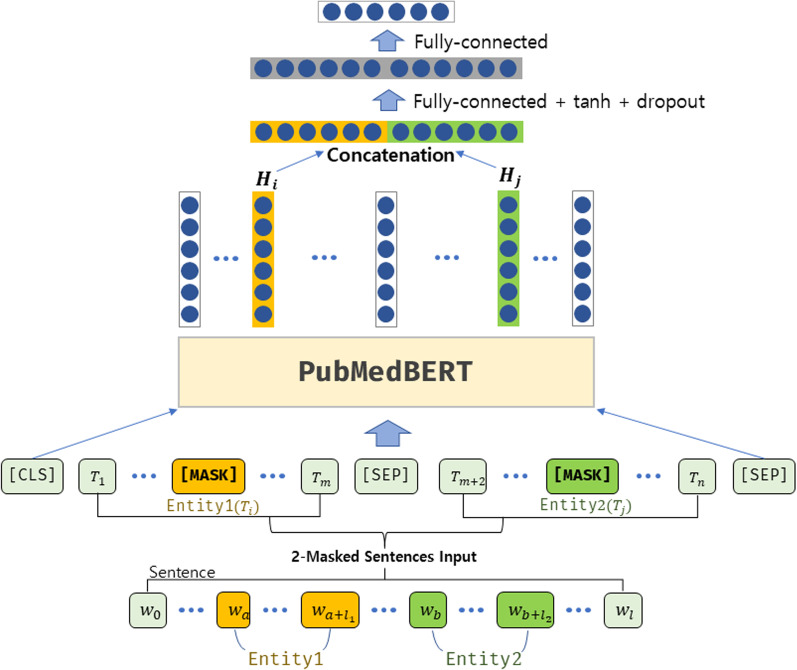
The relationship between biomedical entities is complex, and many of them have not yet been identified. For many biomedical research areas including drug discovery, it is of paramount importance to identify the relationships that have already been established through a comprehensive literature survey. However, manually searching through literature is difficult as the amount of biomedical publications continues to increase. Therefore, the relation classification task, which automatically mines meaningful relations from the literature, is spotlighted in the field of biomedical text mining. By applying relation classification techniques to the accumulated biomedical literature, existing semantic relations between biomedical entities that can help to infer previously unknown relationships are efficiently grasped. To develop semantic relation classification models, which is a type of supervised machine learning, it is essential to construct a training dataset that is manually annotated by biomedical experts with semantic relations among biomedical entities. Any advanced model must be trained on a dataset with reliable quality and meaningful scale to be deployed in the real world and can assist biologists in their research. In addition, as the number of such public datasets increases, the performance of machine learning algorithms can be accurately revealed and compared by using those datasets as a benchmark for model development and improvement. In this paper, we aim to build such a dataset. Along with that, to validate the usability of the dataset as training data for relation classification models and to improve the performance of the relation extraction task, we built a relation classification model based on Bidirectional Encoder Representations from Transformers (BERT) trained on our dataset, applying our newly proposed fine-tuning methodology. In experiments comparing performance among several models based on different deep learning algorithms, our model with the proposed fine-tuning methodology showed the best performance. The experimental results show that the constructed training dataset is an important information resource for the development and evaluation of semantic relation extraction models. Furthermore, relation extraction performance can be improved by integrating our proposed fine-tuning methodology. Therefore, this can lead to the promotion of future text mining research in the biomedical field.
生物医学实体之间的关系复杂,其中许多关系尚未被确定。对于许多包括药物发现在内的生物医学研究领域,通过全面的文献调查来确定已经建立的关系至关重要。然而,由于生物医学出版物的数量不断增加,手动搜索文献非常困难。因此,关系分类任务(即自动从文献中挖掘有意义的关系)成为生物医学文本挖掘领域的焦点。通过将关系分类技术应用于积累的生物医学文献,可以有效地掌握生物医学实体之间有助于推断未知关系的现有语义关系。为了开发语义关系分类模型,这是一种监督机器学习,必须构建一个由生物医学专家手动注释的训练数据集,其中包含生物医学实体之间的语义关系。任何先进的模型都必须在具有可靠质量和有意义规模的数据集上进行训练,以便在现实世界中部署,并帮助生物学家进行研究。此外,随着此类公共数据集数量的增加,可以使用这些数据集作为模型开发和改进的基准,准确揭示和比较机器学习算法的性能。在本文中,我们旨在构建这样的数据集。与此同时,为了验证数据集作为关系分类模型训练数据的可用性,并提高关系提取任务的性能,我们基于我们的数据集构建了一个基于转换器的双向编码器表示(BERT)的关系分类模型,并应用了我们新提出的微调方法。在基于不同深度学习算法的几个模型的性能比较实验中,我们的模型和所提出的微调方法表现出了最佳的性能。实验结果表明,构建的训练数据集是开发和评估语义关系提取模型的重要信息资源。此外,通过集成我们提出的微调方法可以提高关系提取性能。因此,这可以促进未来生物医学领域的文本挖掘研究。