Faculty of Computer Science and Engineering, Ss Cyril and Methodius, University- Skopje, Skopje, the Former Yugoslav Republic of Macedonia.
Computer Systems Department, Jožef Stefan Institute, Ljubljana, Slovenia.
J Med Internet Res. 2021 Aug 9;23(8):e28229. doi: 10.2196/28229.
Recently, food science has been garnering a lot of attention. There are many open research questions on food interactions, as one of the main environmental factors, with other health-related entities such as diseases, treatments, and drugs. In the last 2 decades, a large amount of work has been done in natural language processing and machine learning to enable biomedical information extraction. However, machine learning in food science domains remains inadequately resourced, which brings to attention the problem of developing methods for food information extraction. There are only few food semantic resources and few rule-based methods for food information extraction, which often depend on some external resources. However, an annotated corpus with food entities along with their normalization was published in 2019 by using several food semantic resources.
In this study, we investigated how the recently published bidirectional encoder representations from transformers (BERT) model, which provides state-of-the-art results in information extraction, can be fine-tuned for food information extraction.
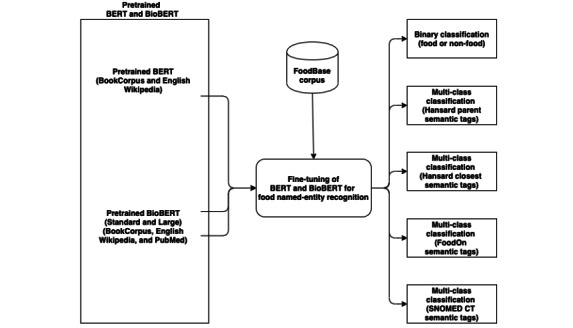
We introduce FoodNER, which is a collection of corpus-based food named-entity recognition methods. It consists of 15 different models obtained by fine-tuning 3 pretrained BERT models on 5 groups of semantic resources: food versus nonfood entity, 2 subsets of Hansard food semantic tags, FoodOn semantic tags, and Systematized Nomenclature of Medicine Clinical Terms food semantic tags.
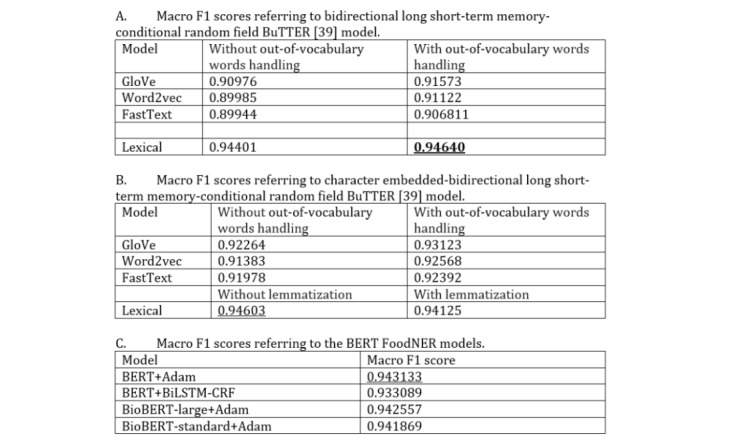
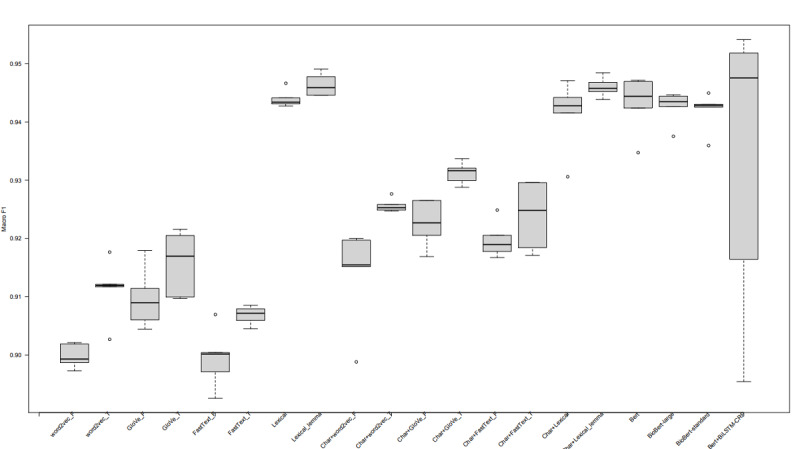
All BERT models provided very promising results with 93.30% to 94.31% macro F1 scores in the task of distinguishing food versus nonfood entity, which represents the new state-of-the-art technology in food information extraction. Considering the tasks where semantic tags are predicted, all BERT models obtained very promising results once again, with their macro F1 scores ranging from 73.39% to 78.96%.
FoodNER can be used to extract and annotate food entities in 5 different tasks: food versus nonfood entities and distinguishing food entities on the level of food groups by using the closest Hansard semantic tags, the parent Hansard semantic tags, the FoodOn semantic tags, or the Systematized Nomenclature of Medicine Clinical Terms semantic tags.
最近,食品科学受到了广泛关注。作为主要环境因素之一,食物与其他与健康相关的实体(如疾病、治疗方法和药物)之间存在许多开放性的研究问题。在过去的 20 年中,大量的工作已经在自然语言处理和机器学习中完成,以实现生物医学信息提取。然而,食品科学领域的机器学习仍然资源不足,这引起了开发食品信息提取方法的问题。目前仅有少量的食品语义资源和基于规则的食品信息提取方法,这些方法往往依赖于一些外部资源。然而,2019 年使用了几种食品语义资源发布了一个带有食物实体及其规范化的标注语料库。
在这项研究中,我们研究了最近发表的基于转换器的双向编码器表示(BERT)模型,该模型在信息提取方面提供了最新的结果,如何对其进行微调以进行食品信息提取。
我们引入了 FoodNER,这是一个基于语料库的食品命名实体识别方法的集合。它由通过在 5 组语义资源上微调 3 个预训练的 BERT 模型得到的 15 个不同模型组成:食物与非食物实体、Hansard 食物语义标签的 2 个子集、FoodOn 语义标签和 Systematized Nomenclature of Medicine Clinical Terms 食物语义标签。
所有的 BERT 模型在区分食物与非食物实体的任务中都提供了非常有希望的结果,其宏 F1 分数在 93.30%至 94.31%之间,这代表了食品信息提取的最新技术。考虑到需要预测语义标签的任务,所有的 BERT 模型再次获得了非常有希望的结果,其宏 F1 分数在 73.39%至 78.96%之间。
FoodNER 可用于在 5 个不同任务中提取和标注食物实体:食物与非食物实体,以及使用最接近的 Hansard 语义标签、父级 Hansard 语义标签、FoodOn 语义标签或 Systematized Nomenclature of Medicine Clinical Terms 语义标签区分食物实体的食物组水平。