Sima Ana Claudia, Mendes de Farias Tarcisio, Anisimova Maria, Dessimoz Christophe, Robinson-Rechavi Marc, Zbinden Erich, Stockinger Kurt
SIB Swiss Institute of Bioinformatics, Lausanne, Switzerland.
Department of Computational Biology, University of Lausanne, Lausanne, Switzerland.
Distrib Parallel Databases. 2022;40(2-3):409-440. doi: 10.1007/s10619-022-07414-w. Epub 2022 Jul 16.
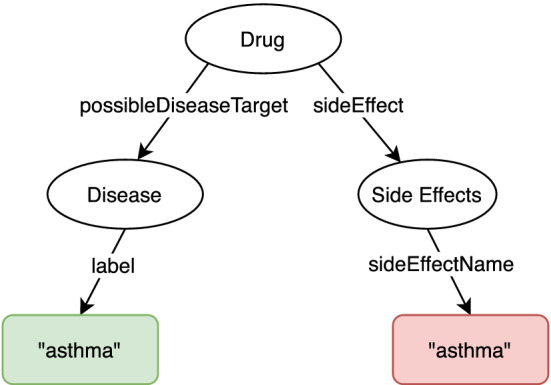
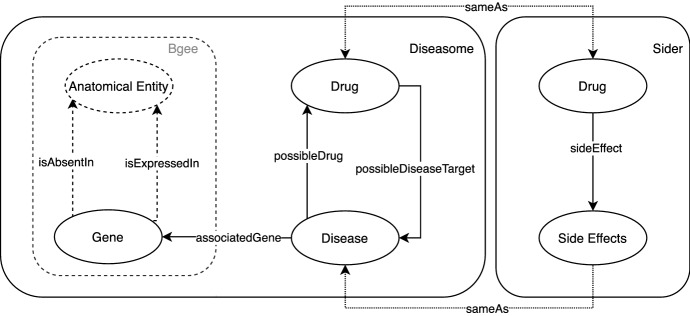
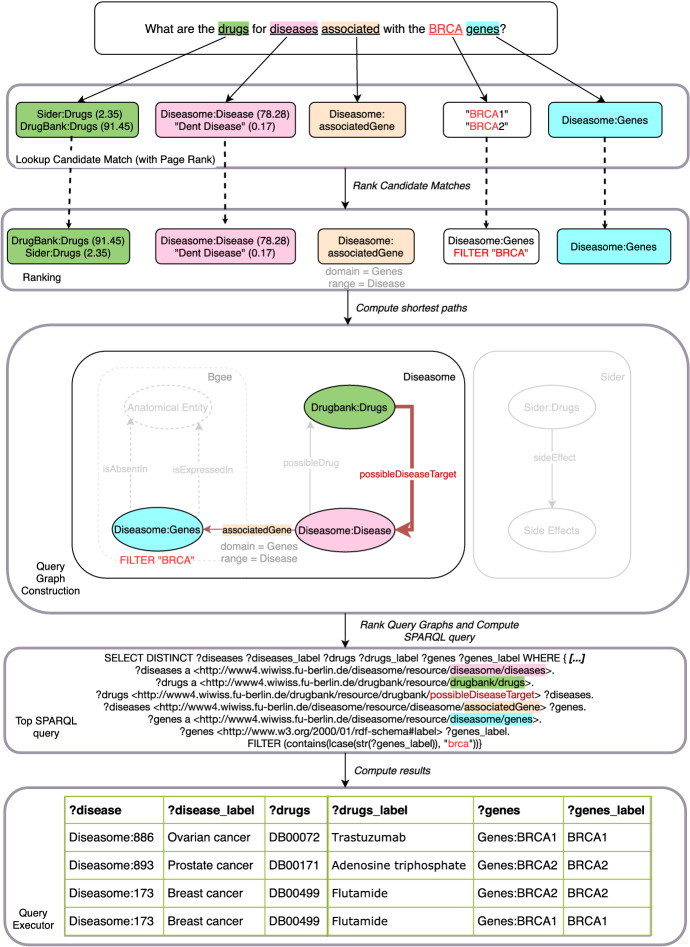
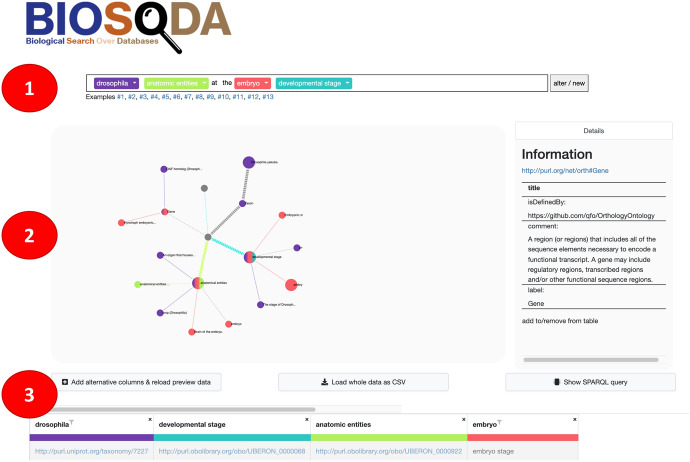
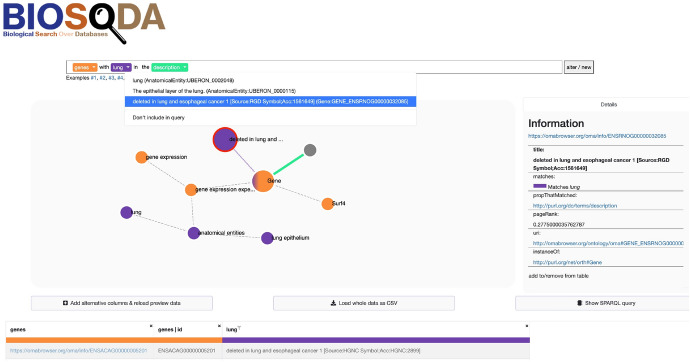
The problem of natural language processing over structured data has become a growing research field, both within the relational database and the Semantic Web community, with significant efforts involved in question answering over knowledge graphs (KGQA). However, many of these approaches are either specifically targeted at question answering using DBpedia, or require to translate a natural language question to SPARQL in order to query the knowledge graph. Hence, these approaches often cannot be applied directly to complex where no prior training data is available. In this paper, we focus on the challenges of natural language processing over knowledge graphs of scientific datasets. In particular, we introduce Bio-SODA, a natural language processing engine that does not require training data in the form of question-answer pairs for generating SPARQL queries. Bio-SODA uses a generic graph-based approach for translating user questions to a ranked list of SPARQL candidate queries. Furthermore, Bio-SODA uses a novel ranking algorithm that includes node centrality as a measure of relevance for selecting the best SPARQL candidate query. Our experiments with real-world datasets across several scientific domains, including the official Question Answering over Linked Data (QALD) challenge, as well as the CORDIS dataset of European projects, show that Bio-SODA outperforms publicly available KGQA systems by an F1-score of least 20% and by an even higher factor on more complex bioinformatics datasets. Finally, we introduce Bio-SODA UX, a graphical user interface designed to assist users in the exploration of large knowledge graphs and in dynamically disambiguating natural language questions that target the data available in these graphs.
在关系数据库和语义网社区中,针对结构化数据的自然语言处理问题已成为一个不断发展的研究领域,人们在知识图谱问答(KGQA)方面投入了大量精力。然而,这些方法中的许多要么专门针对使用DBpedia进行问答,要么需要将自然语言问题翻译成SPARQL以便查询知识图谱。因此,这些方法通常不能直接应用于没有可用先验训练数据的复杂情况。在本文中,我们关注科学数据集知识图谱上自然语言处理的挑战。具体来说,我们引入了Bio-SODA,这是一种自然语言处理引擎,它在生成SPARQL查询时不需要问答对形式的训练数据。Bio-SODA使用一种基于通用图的方法将用户问题翻译成SPARQL候选查询的排序列表。此外,Bio-SODA使用一种新颖的排序算法,该算法将节点中心性作为相关性度量来选择最佳的SPARQL候选查询。我们对多个科学领域的真实世界数据集进行的实验,包括官方的链接数据问答(QALD)挑战以及欧洲项目的CORDIS数据集,表明Bio-SODA在F1分数上比公开可用的KGQA系统至少高出20%,在更复杂的生物信息学数据集上优势更大。最后,我们引入了Bio-SODA UX,这是一个图形用户界面,旨在帮助用户探索大型知识图谱,并动态消除针对这些图谱中可用数据的自然语言问题的歧义。