Big Data Institute, Li Ka Shing Centre for Health Information and Discovery, Nuffield Department of Population Health, University of Oxford, Oxford, UK.
Big Data Institute, Li Ka Shing Centre for Health Information and Discovery, Nuffield Department of Population Health, University of Oxford, Oxford, UK; Wellcome Centre for Integrative Neuroimaging, FMRIB, Nuffield Department of Clinical Neurosciences, University of Oxford, Oxford, UK.
Neuroimage. 2022 Dec 1;264:119729. doi: 10.1016/j.neuroimage.2022.119729. Epub 2022 Nov 4.
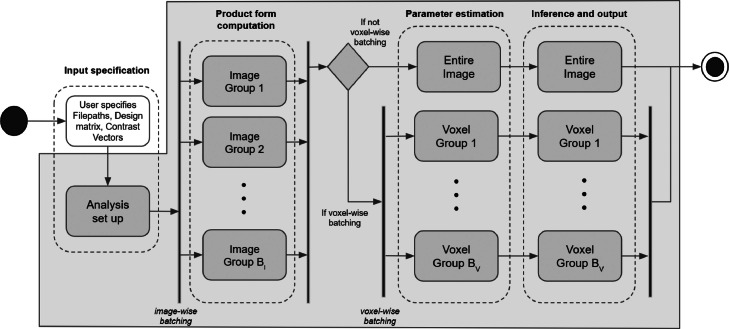
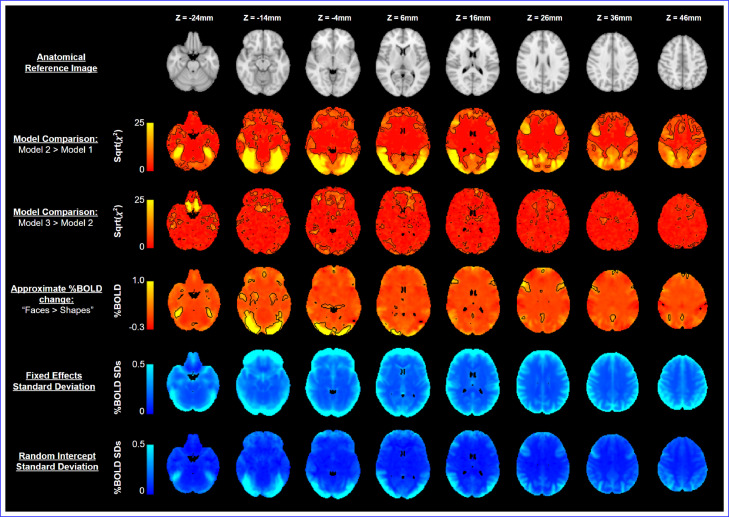
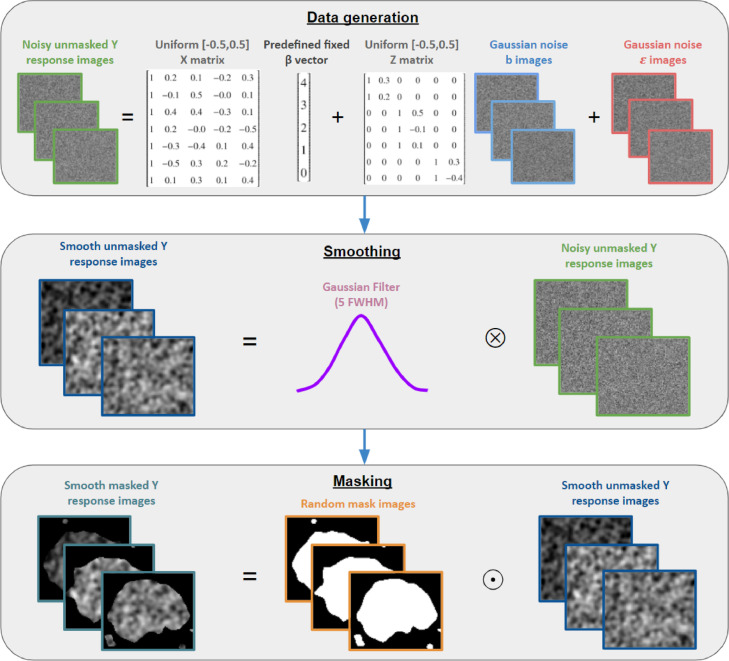
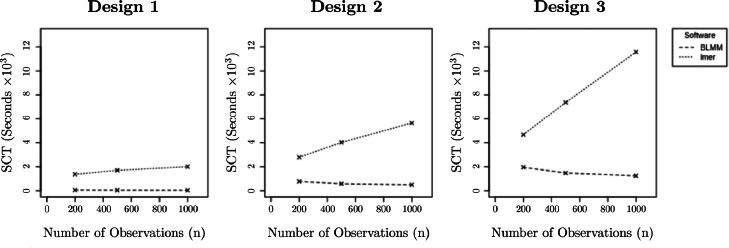
Within neuroimaging large-scale, shared datasets are becoming increasingly commonplace, challenging existing tools both in terms of overall scale and complexity of the study designs. As sample sizes grow, researchers are presented with new opportunities to detect and account for grouping factors and covariance structure present in large experimental designs. In particular, standard linear model methods cannot account for the covariance and grouping structures present in large datasets, and the existing linear mixed models (LMM) tools are neither scalable nor exploit the computational speed-ups afforded by vectorisation of computations over voxels. Further, nearly all existing tools for imaging (fixed or mixed effect) do not account for variability in the patterns of missing data near cortical boundaries and the edge of the brain, and instead omit any voxels with any missing data. Yet in the large-n setting, such a voxel-wise deletion missing data strategy leads to severe shrinkage of the final analysis mask. To counter these issues, we describe the "Big" Linear Mixed Models (BLMM) toolbox, an efficient Python package for large-scale fMRI LMM analyses. BLMM is designed for use on high performance computing clusters and utilizes a Fisher Scoring procedure made possible by derivations for the LMM Fisher information matrix and score vectors derived in our previous work, Maullin-Sapey and Nichols (2021).
在神经影像学中,大规模的共享数据集变得越来越普遍,这对现有的工具提出了挑战,无论是在整体规模还是研究设计的复杂性方面。随着样本量的增加,研究人员有了新的机会来检测和考虑大实验设计中存在的分组因素和协方差结构。特别是,标准线性模型方法无法解释大型数据集中的协方差和分组结构,而现有的线性混合模型(LMM)工具既不可扩展,也无法利用通过向量化计算在体素上实现的计算速度提升。此外,几乎所有现有的成像工具(固定或混合效应)都无法解释皮质边界和大脑边缘处缺失数据模式的可变性,而是忽略了任何具有缺失数据的体素。然而,在大样本量的情况下,这种体素级别的删除缺失数据策略会导致最终分析掩模严重收缩。为了解决这些问题,我们描述了“Big”线性混合模型(BLMM)工具包,这是一个用于大规模 fMRI LMM 分析的高效 Python 包。BLMM 专为高性能计算集群设计,并利用我们之前的工作 Maullin-Sapey 和 Nichols(2021)中推导的 LMM 费雪信息矩阵和得分向量的费雪评分过程。