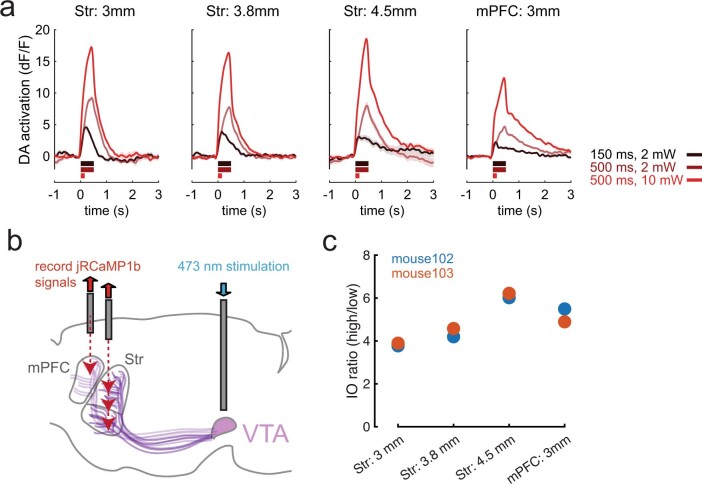
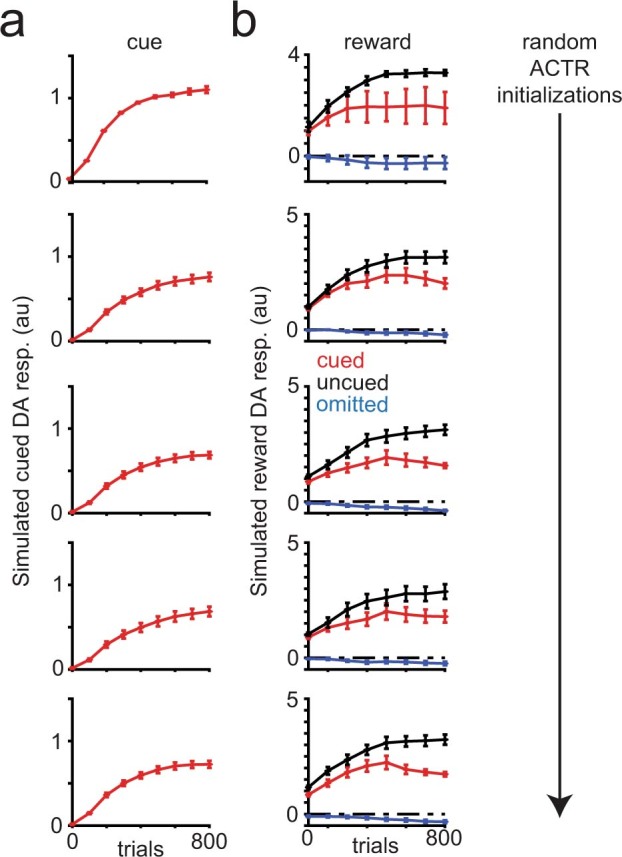
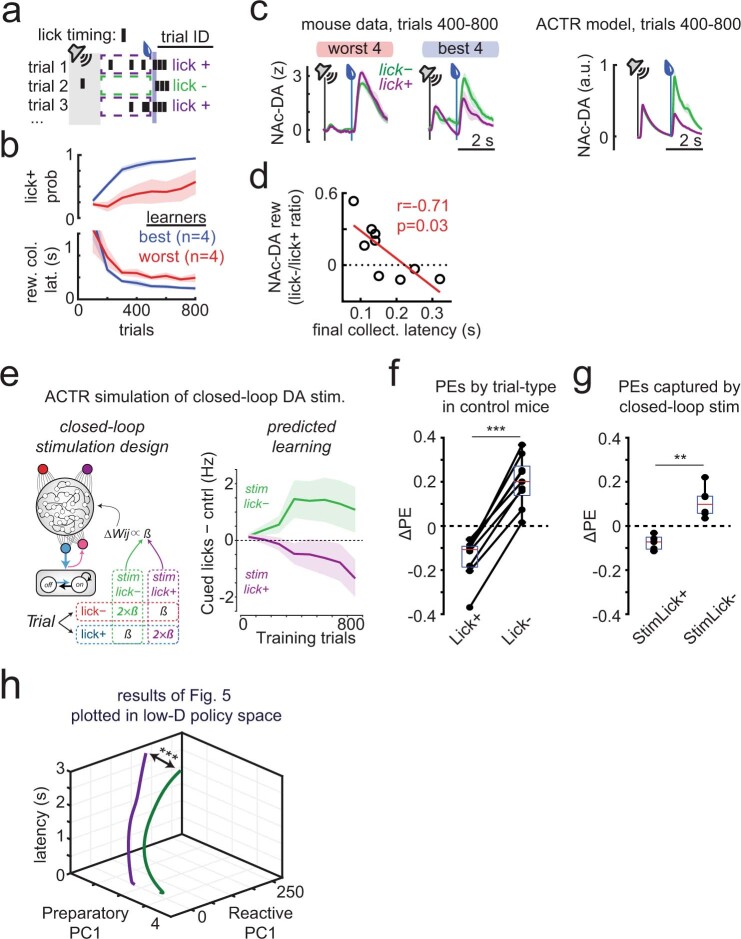
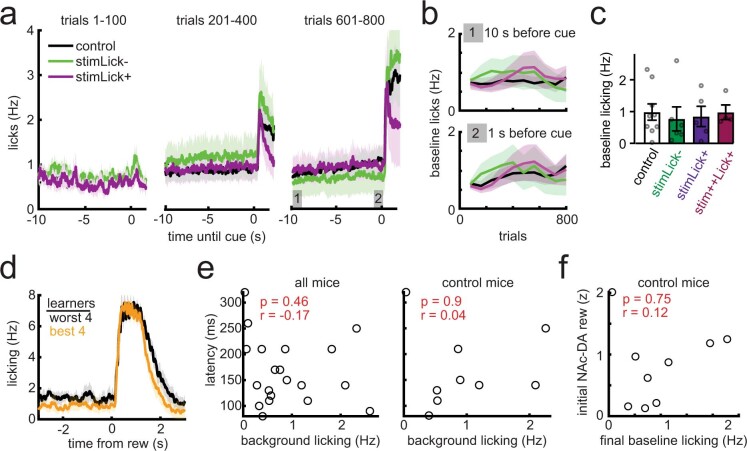
Howard Hughes Medical Institute, Janelia Research Campus, Ashburn, VA, USA.
Nature. 2023 Feb;614(7947):294-302. doi: 10.1038/s41586-022-05614-z. Epub 2023 Jan 18.
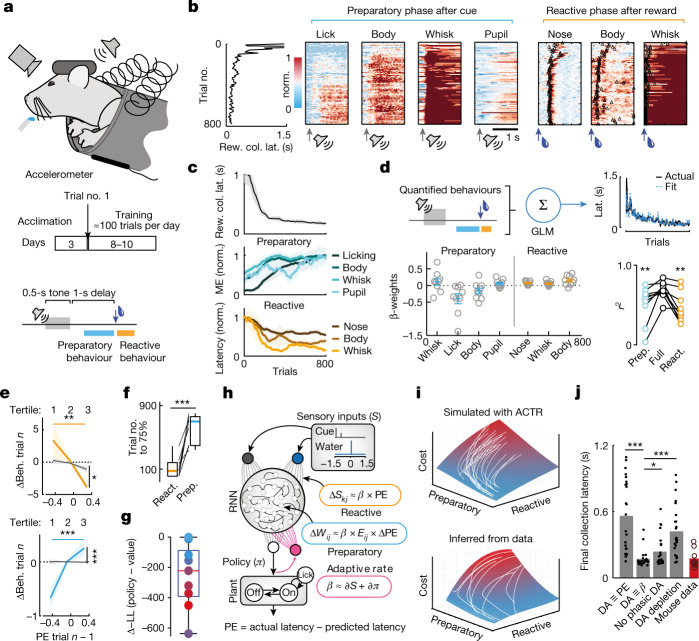
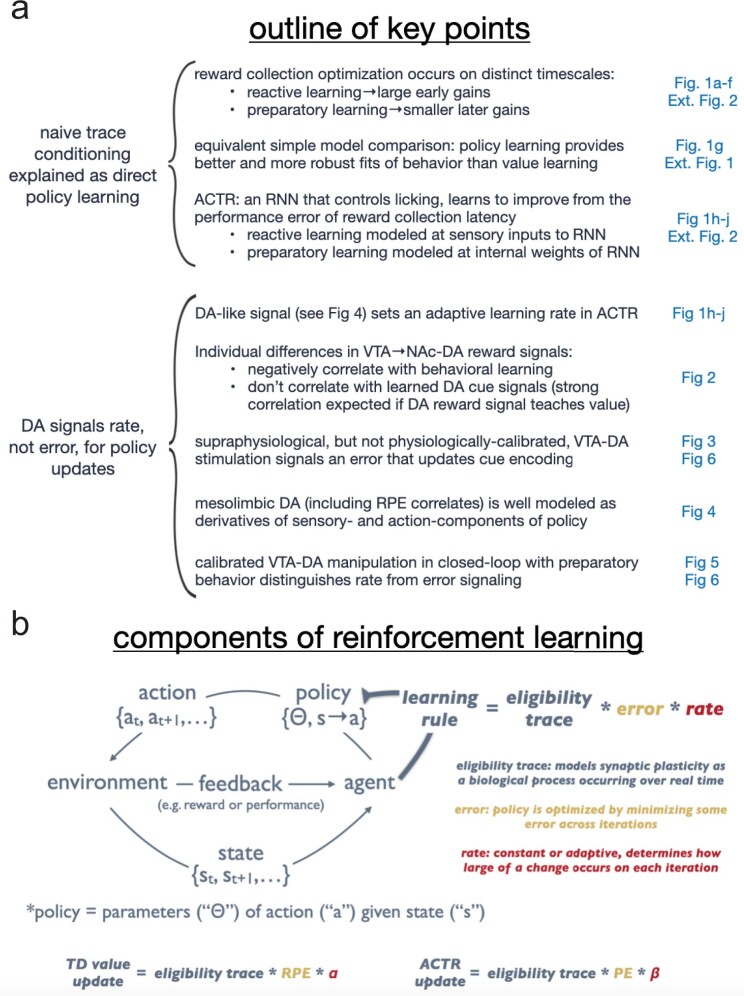
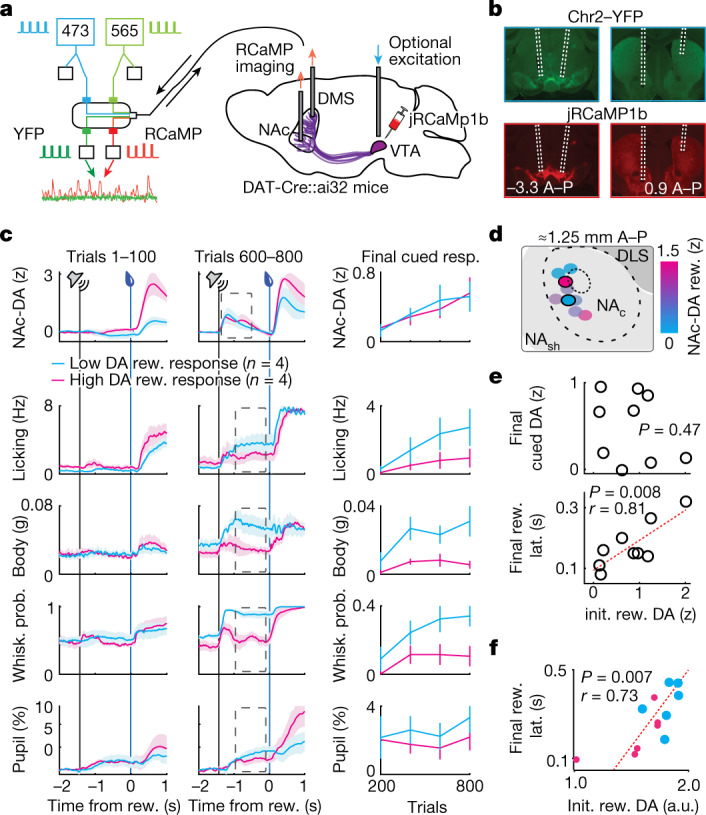
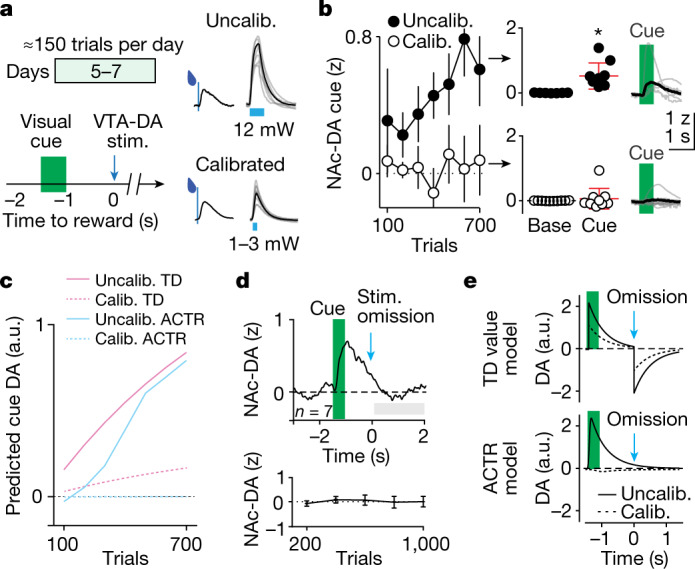
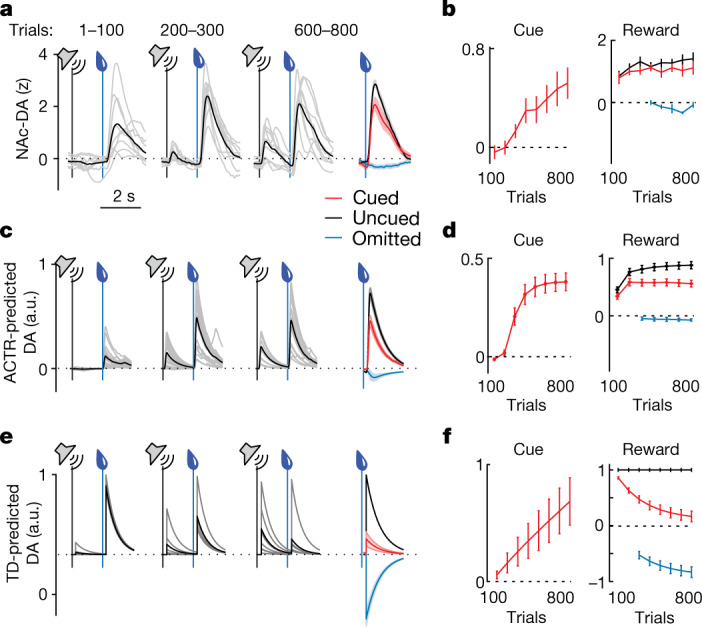
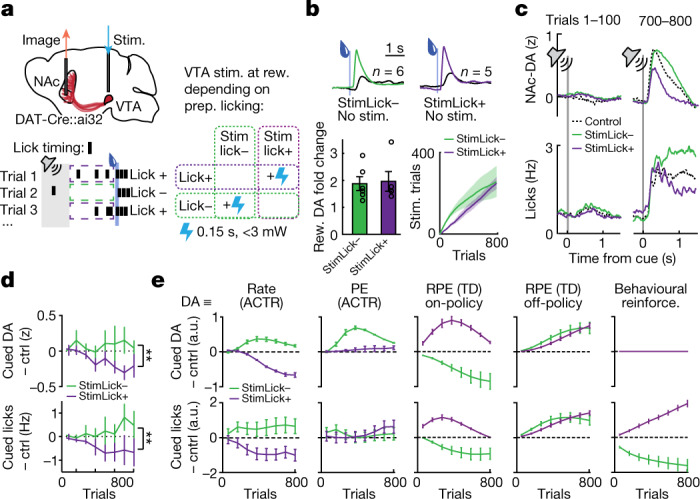
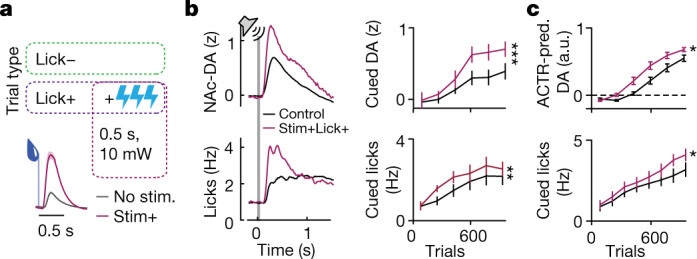
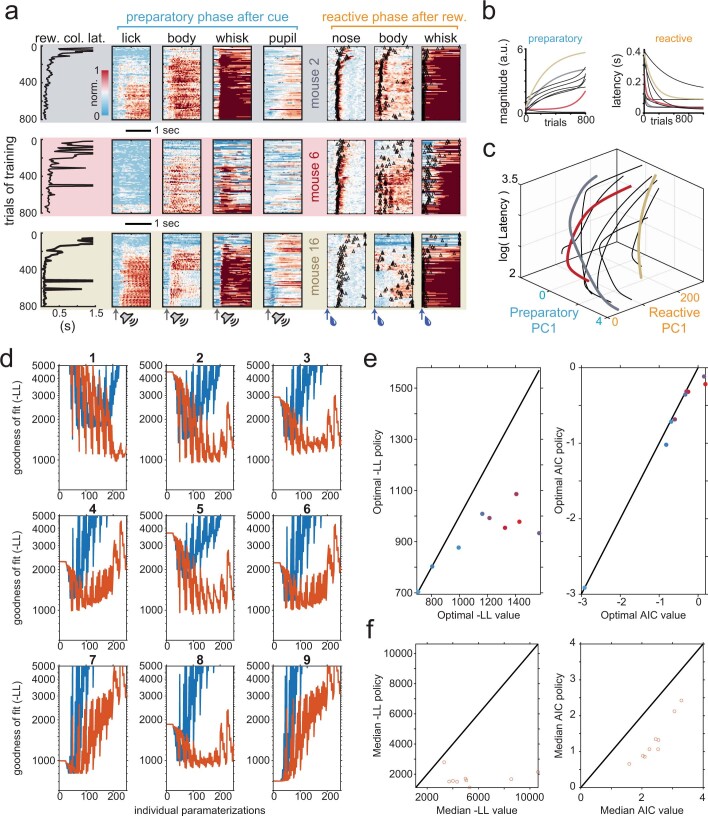
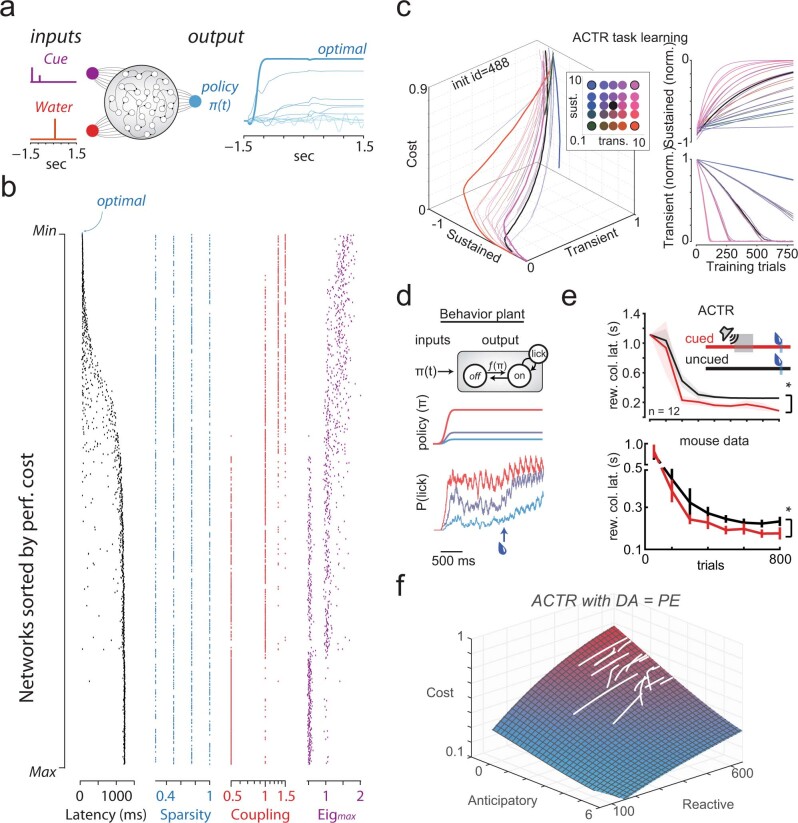
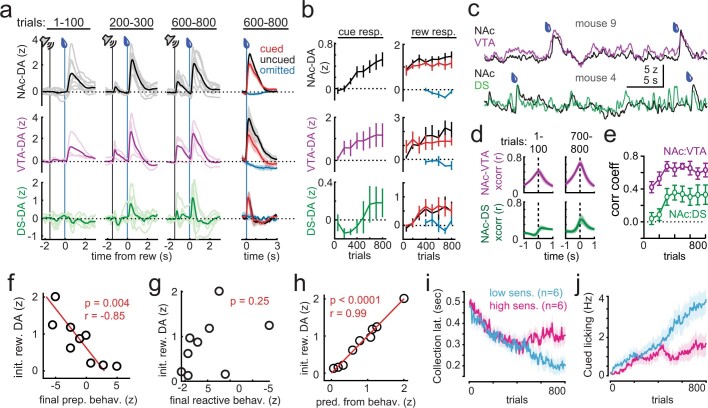
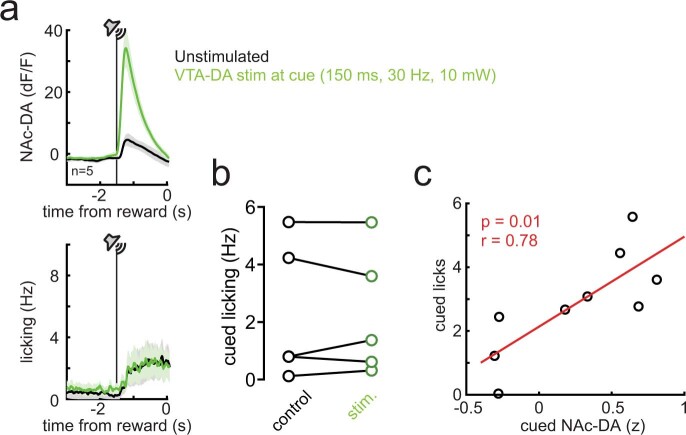
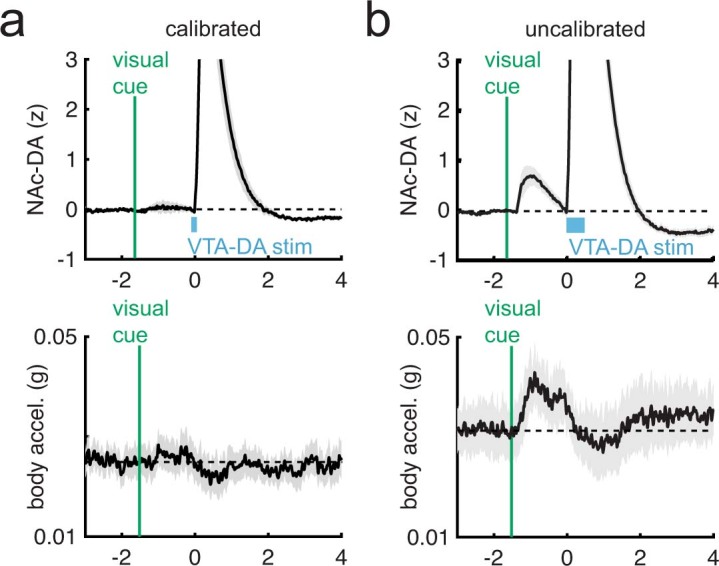
Recent success in training artificial agents and robots derives from a combination of direct learning of behavioural policies and indirect learning through value functions. Policy learning and value learning use distinct algorithms that optimize behavioural performance and reward prediction, respectively. In animals, behavioural learning and the role of mesolimbic dopamine signalling have been extensively evaluated with respect to reward prediction; however, so far there has been little consideration of how direct policy learning might inform our understanding. Here we used a comprehensive dataset of orofacial and body movements to understand how behavioural policies evolved as naive, head-restrained mice learned a trace conditioning paradigm. Individual differences in initial dopaminergic reward responses correlated with the emergence of learned behavioural policy, but not the emergence of putative value encoding for a predictive cue. Likewise, physiologically calibrated manipulations of mesolimbic dopamine produced several effects inconsistent with value learning but predicted by a neural-network-based model that used dopamine signals to set an adaptive rate, not an error signal, for behavioural policy learning. This work provides strong evidence that phasic dopamine activity can regulate direct learning of behavioural policies, expanding the explanatory power of reinforcement learning models for animal learning.
最近,人工智能代理和机器人的训练取得了成功,这得益于行为策略的直接学习和通过价值函数的间接学习的结合。策略学习和价值学习使用不同的算法,分别优化行为表现和奖励预测。在动物中,行为学习和中脑边缘多巴胺信号的作用已经在很大程度上针对奖励预测进行了评估;然而,到目前为止,对于直接策略学习如何为我们的理解提供信息,还没有太多的考虑。在这里,我们使用了一个全面的口腔和身体运动数据集,来了解在无经验、头部受限的老鼠学习痕迹条件反射范式时,行为策略是如何演变的。初始多巴胺奖赏反应的个体差异与习得的行为策略的出现相关,但与预测线索的价值编码的出现无关。同样,中脑边缘多巴胺的生理校准操纵产生了几种与价值学习不一致的效果,但被基于神经网络的模型所预测,该模型使用多巴胺信号为行为策略学习设置自适应率,而不是错误信号。这项工作为多巴胺活动可以调节行为策略的直接学习提供了有力的证据,扩展了强化学习模型对动物学习的解释能力。