School of Information Science and Technology, East China University of Science and Technology, Shanghai, 200237, China.
BMC Med Inform Decis Mak. 2023 Feb 14;23(1):34. doi: 10.1186/s12911-023-02127-1.
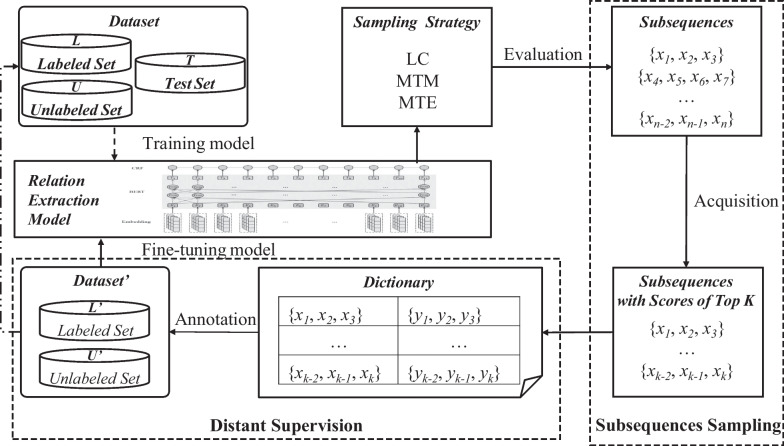
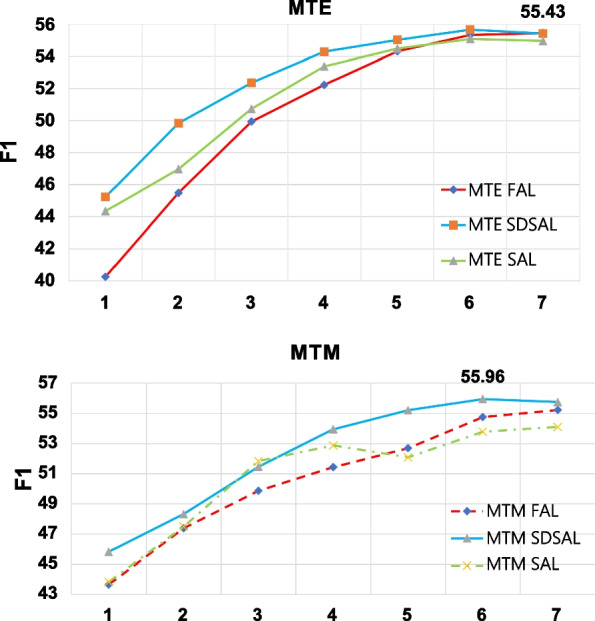
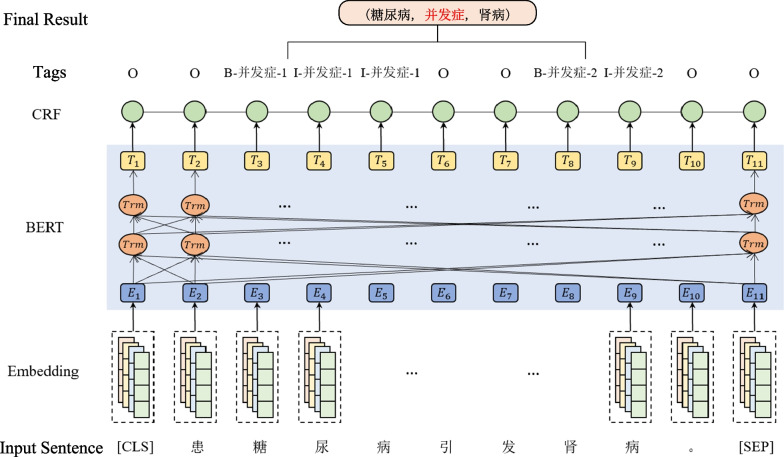
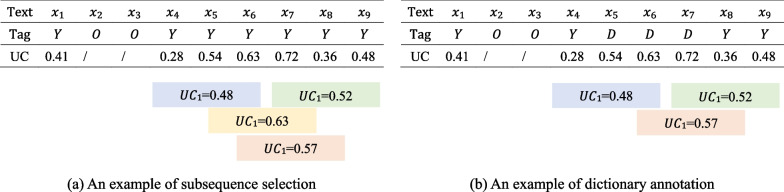
In recent years, relation extraction on unstructured texts has become an important task in medical research. However, relation extraction requires a large amount of labeled corpus, manually annotating sequences is time consuming and expensive. Therefore, efficient and economical methods for annotating sequences are required to ensure the performance of relational extraction. This paper proposes a method of subsequence and distant supervision based active learning. The method is annotated by selecting information-rich subsequences as a sampling unit instead of the full sentences in traditional active learning. Additionally, the method saves the labeled subsequence texts and their corresponding labels in a dictionary which is continuously updated and maintained, and pre-labels the unlabeled set through text matching based on the idea of distant supervision. Finally, the method combines a Chinese-RoBERTa-CRF model for relation extraction in Chinese medical texts. Experimental results test on the CMeIE dataset achieves the best performance compared to existing methods. And the best F1 value obtained between different sampling strategies is 55.96%.
近年来,非结构化文本上的关系抽取已成为医学研究中的一项重要任务。然而,关系抽取需要大量带标签的语料库,手动标注序列既耗时又昂贵。因此,需要高效且经济的序列标注方法来确保关系抽取的性能。本文提出了一种基于子序列和远程监督的主动学习方法。该方法通过选择信息丰富的子序列作为采样单元,而不是传统主动学习中的完整句子来进行标注。此外,该方法将标记的子序列文本及其对应的标签存储在字典中,并不断更新和维护,然后基于远程监督的思想通过文本匹配对未标记的集合进行预标记。最后,该方法结合了一种基于中文 RoBERTa-CRF 的模型,用于中文医学文本的关系抽取。在 CMeIE 数据集上的实验结果表明,该方法相较于现有方法取得了最佳性能。并且,在不同的采样策略之间获得的最佳 F1 值为 55.96%。