Rahman Protiva, Ye Cheng, Mittendorf Kathleen F, Lenoue-Newton Michele, Micheel Christine, Wolber Jan, Osterman Travis, Fabbri Daniel
Biomedical Informatics, Vanderbilt University Medical Center, Nashville, Tennessee, USA.
Vanderbilt Ingram Cancer Center, Vanderbilt University Medical Center, Nashville, Tennessee, USA.
JAMIA Open. 2023 Apr 1;6(1):ooad017. doi: 10.1093/jamiaopen/ooad017. eCollection 2023 Apr.
Automatically identifying patients at risk of immune checkpoint inhibitor (ICI)-induced colitis allows physicians to improve patientcare. However, predictive models require training data curated from electronic health records (EHR). Our objective is to automatically identify notes documenting ICI-colitis cases to accelerate data curation.
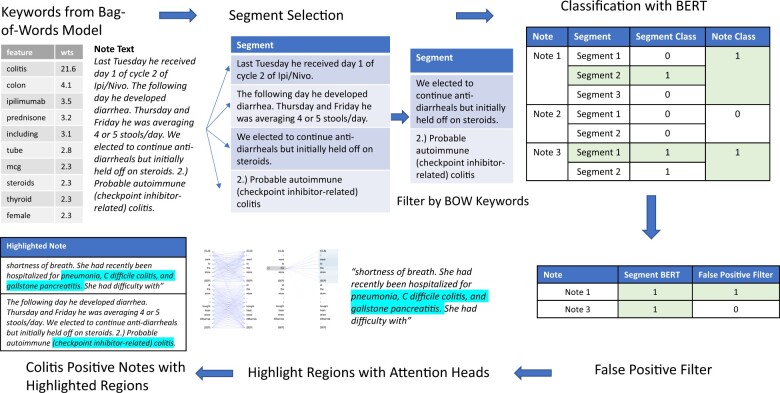
We present a data pipeline to automatically identify ICI-colitis from EHR notes, accelerating chart review. The pipeline relies on BERT, a state-of-the-art natural language processing (NLP) model. The first stage of the pipeline segments long notes using keywords identified through a logistic classifier and applies BERT to identify ICI-colitis notes. The next stage uses a second BERT model tuned to identify false positive notes and remove notes that were likely positive for mentioning colitis as a side-effect. The final stage further accelerates curation by highlighting the colitis-relevant portions of notes. Specifically, we use BERT's attention scores to find high-density regions describing colitis.
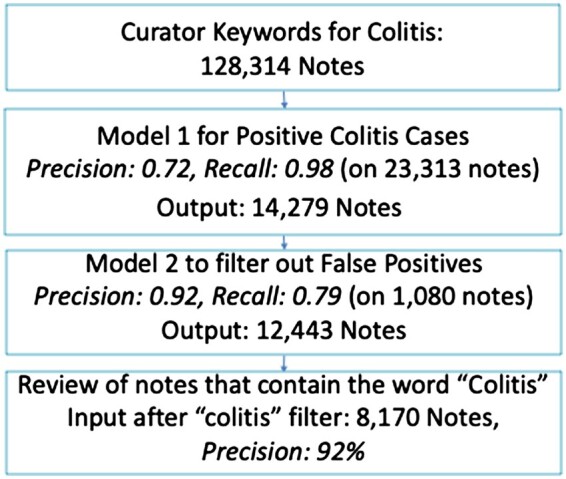
The overall pipeline identified colitis notes with 84% precision and reduced the curator note review load by 75%. The segment BERT classifier had a high recall of 0.98, which is crucial to identify the low incidence (<10%) of colitis.
Curation from EHR notes is a burdensome task, especially when the curation topic is complicated. Methods described in this work are not only useful for ICI colitis but can also be adapted for other domains.
Our extraction pipeline reduces manual note review load and makes EHR data more accessible for research.
自动识别有免疫检查点抑制剂(ICI)诱导性结肠炎风险的患者,有助于医生改善患者护理。然而,预测模型需要从电子健康记录(EHR)中整理出的训练数据。我们的目标是自动识别记录ICI结肠炎病例的笔记,以加速数据整理。
我们提出了一种数据管道,用于从EHR笔记中自动识别ICI结肠炎,从而加速病历审查。该管道依赖于BERT,这是一种先进的自然语言处理(NLP)模型。管道的第一阶段使用通过逻辑分类器识别的关键词对长笔记进行分段,并应用BERT来识别ICI结肠炎笔记。下一阶段使用第二个经过调整的BERT模型来识别假阳性笔记,并删除那些可能因提及结肠炎作为副作用而呈阳性的笔记。最后阶段通过突出显示笔记中与结肠炎相关的部分,进一步加速整理过程。具体而言,我们使用BERT的注意力分数来找到描述结肠炎的高密度区域。
整个管道识别结肠炎笔记的精度为84%,并将整理人员的笔记审查工作量减少了75%。分段BERT分类器的召回率高达0.98,这对于识别低发病率(<10%)的结肠炎至关重要。
从EHR笔记中进行整理是一项繁重的任务,尤其是当整理主题复杂时。这项工作中描述的方法不仅对ICI结肠炎有用,也可适用于其他领域。
我们的提取管道减少了人工笔记审查工作量,并使EHR数据更便于用于研究。