Lattice Automation, 709 E 5th St. #3, Boston, MA, 02127, USA.
Harvard Medical School, 25 Shattuck St, Boston, MA, 02115, USA.
BMC Bioinformatics. 2023 Apr 4;24(1):132. doi: 10.1186/s12859-023-05246-8.
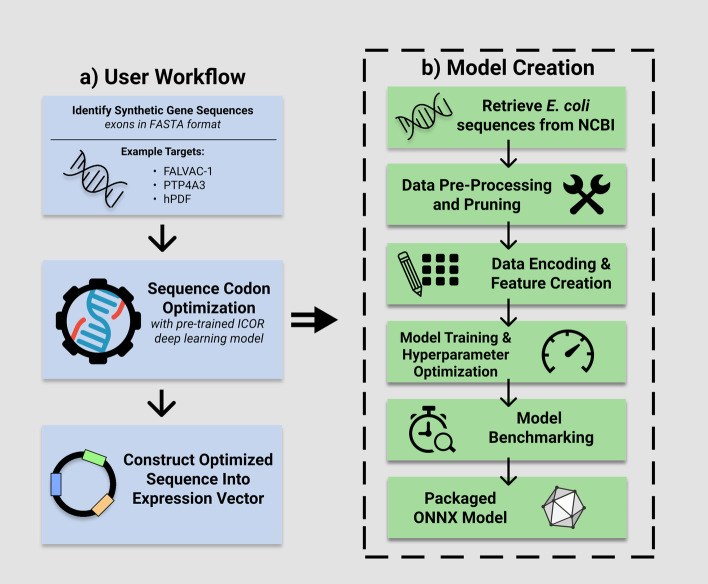
In protein sequences-as there are 61 sense codons but only 20 standard amino acids-most amino acids are encoded by more than one codon. Although such synonymous codons do not alter the encoded amino acid sequence, their selection can dramatically affect the expression of the resulting protein. Codon optimization of synthetic DNA sequences is important for heterologous expression. However, existing solutions are primarily based on choosing high-frequency codons only, neglecting the important effects of rare codons. In this paper, we propose a novel recurrent-neural-network based codon optimization tool, ICOR, that aims to learn codon usage bias on a genomic dataset of Escherichia coli. We compile a dataset of over 7,000 non-redundant, high-expression, robust genes which are used for deep learning. The model uses a bidirectional long short-term memory-based architecture, allowing for the sequential context of codon usage in genes to be learned. Our tool can predict synonymous codons for synthetic genes toward optimal expression in Escherichia coli.
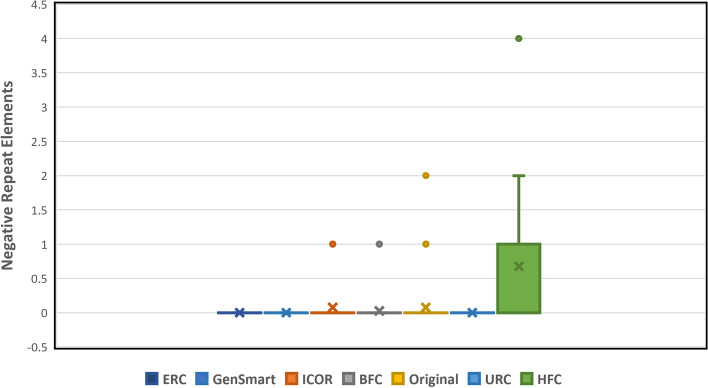
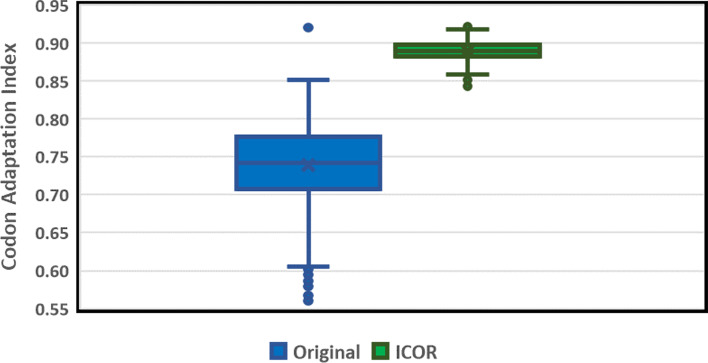
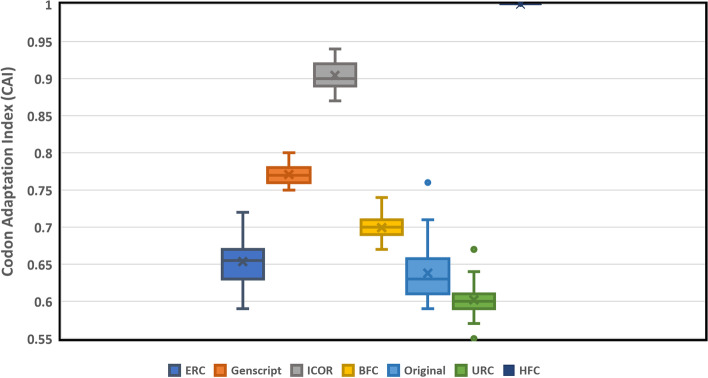
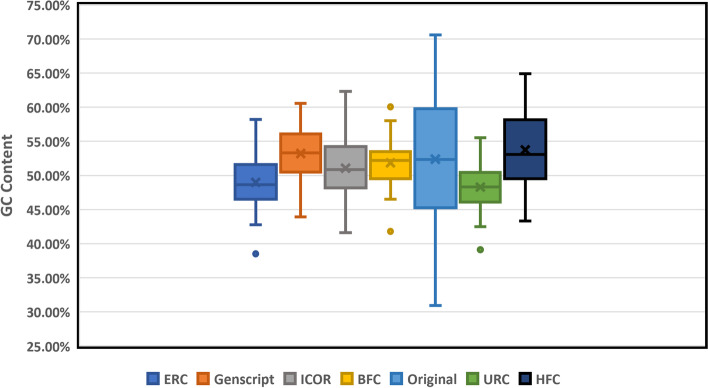
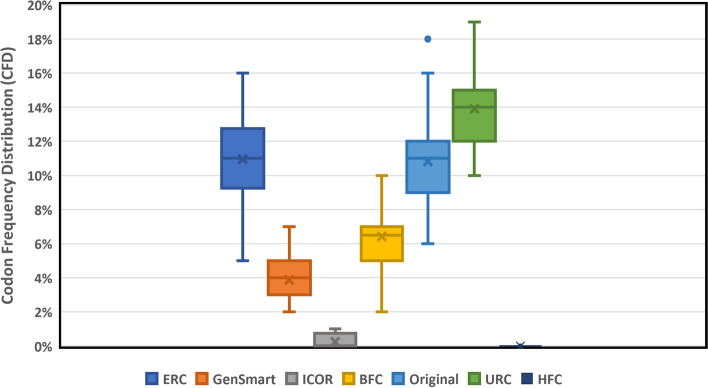
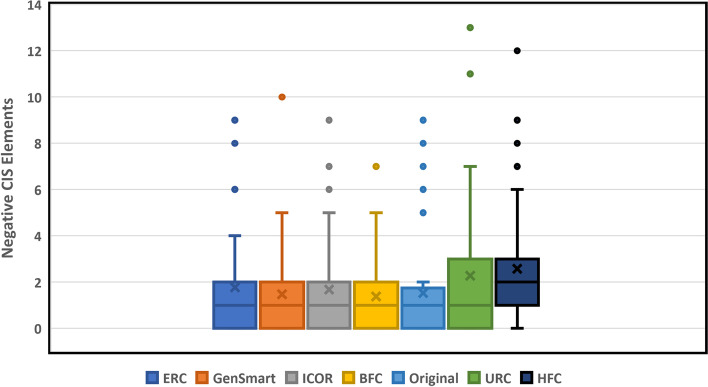
We demonstrate that sequential context achieved via RNN may yield codon selection that is more similar to the host genome. Based on computational metrics that predict protein expression, ICOR theoretically optimizes protein expression more than frequency-based approaches. ICOR is evaluated on 1,481 Escherichia coli genes as well as a benchmark set of 40 select DNA sequences whose heterologous expression has been previously characterized. ICOR's performance is measured across five metrics: the Codon Adaptation Index, GC-content, negative repeat elements, negative cis-regulatory elements, and codon frequency distribution.
The results, based on in silico metrics, indicate that ICOR codon optimization is theoretically more effective in enhancing recombinant expression of proteins over other established codon optimization techniques. Our tool is provided as an open-source software package that includes the benchmark set of sequences used in this study.
在蛋白质序列中,由于有 61 个有意义密码子,但只有 20 种标准氨基酸,因此大多数氨基酸都由不止一个密码子编码。虽然这些同义密码子不会改变编码的氨基酸序列,但它们的选择会极大地影响产生的蛋白质的表达。合成 DNA 序列的密码子优化对于异源表达非常重要。然而,现有的解决方案主要基于只选择高频密码子,而忽略了稀有密码子的重要影响。在本文中,我们提出了一种新的基于递归神经网络的密码子优化工具 ICOR,旨在学习大肠杆菌基因组数据集中的密码子使用偏好。我们编译了一个超过 7000 个非冗余、高表达、稳健基因的数据集,用于深度学习。该模型使用基于双向长短时记忆的架构,允许学习基因中密码子使用的顺序上下文。我们的工具可以预测合成基因的同义密码子,以实现大肠杆菌中的最佳表达。
我们证明,通过 RNN 实现的序列上下文可以产生更类似于宿主基因组的密码子选择。基于预测蛋白质表达的计算指标,ICOR 在理论上比基于频率的方法更能优化蛋白质表达。ICOR 在 1481 个大肠杆菌基因以及之前已对其异源表达进行了特征描述的 40 个选择 DNA 序列的基准集中进行了评估。ICOR 的性能通过五个指标进行衡量:密码子适应指数、GC 含量、负重复元件、负顺式调控元件和密码子频率分布。
基于计算机指标的结果表明,与其他已建立的密码子优化技术相比,ICOR 密码子优化在理论上更能有效地增强蛋白质的重组表达。我们的工具作为一个开源软件包提供,其中包括本研究中使用的基准序列集。