Departamento de Ciências Econômicas, Faculdade de Ciências Econômicas, Universidade Federal de Minas Gerais, Belo Horizonte, Minas Gerais, Brasil.
Departamento de Física, Instituto de Ciências Exatas e Biológicas, Universidade Federal de Ouro Preto, Ouro Preto, Minas Gerais, Brasil.
PLoS One. 2023 May 18;18(5):e0285630. doi: 10.1371/journal.pone.0285630. eCollection 2023.
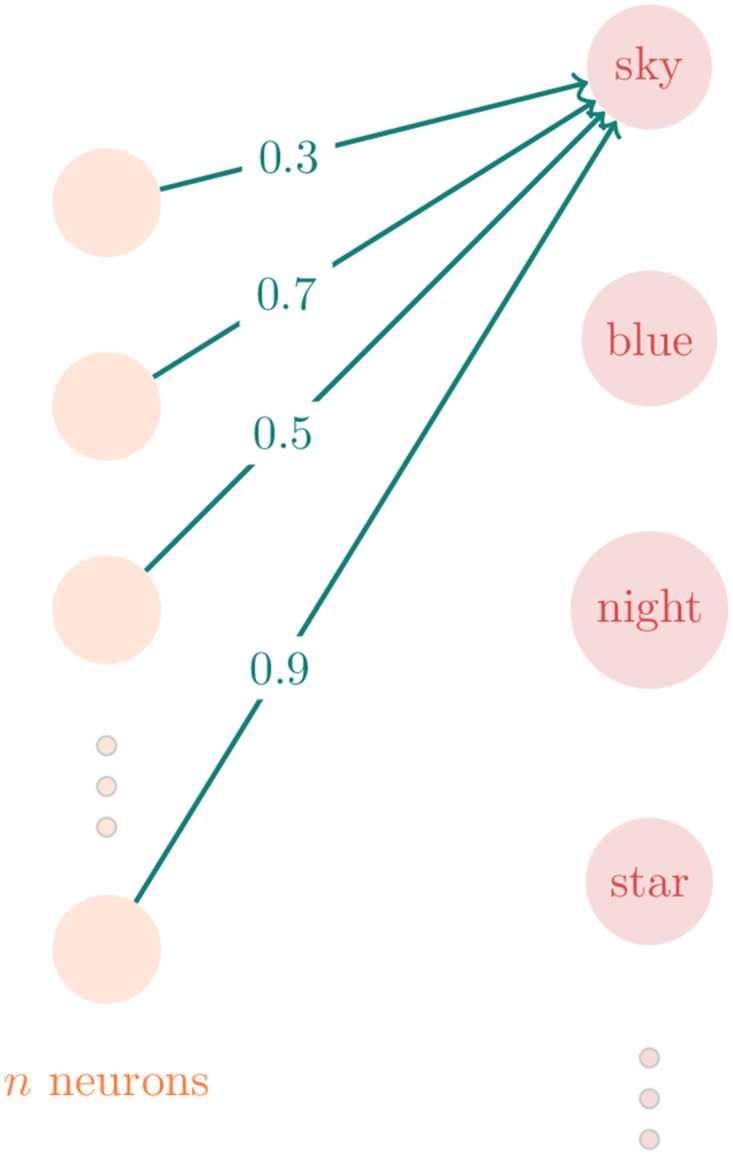
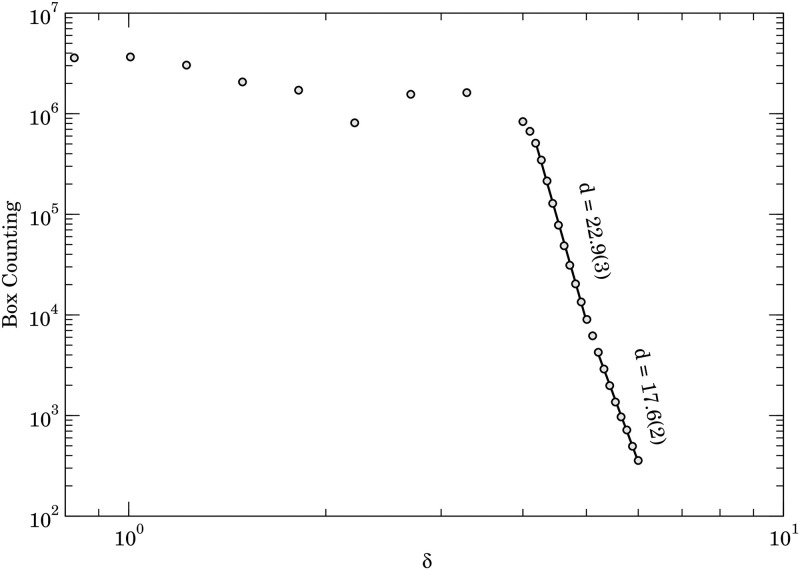
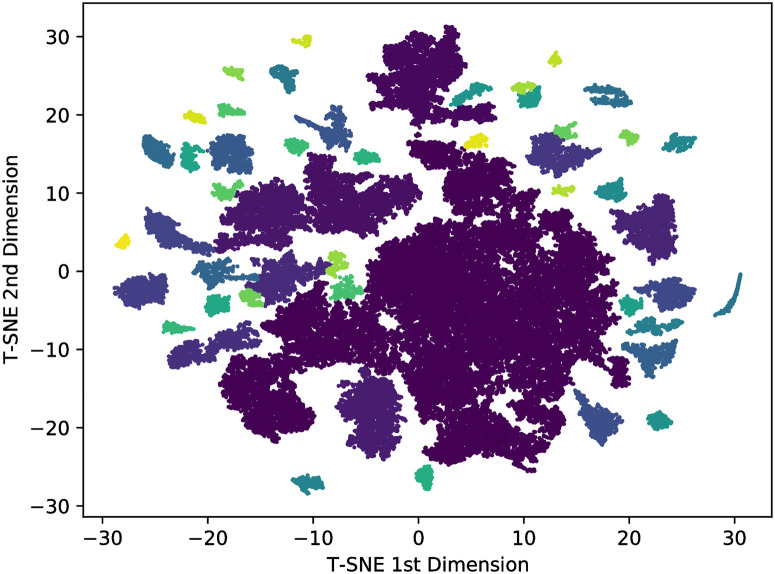
Natural Language Processing (NLP) makes use of Artificial Intelligence algorithms to extract meaningful information from unstructured texts, i.e., content that lacks metadata and cannot easily be indexed or mapped onto standard database fields. It has several applications, from sentiment analysis and text summary to automatic language translation. In this work, we use NLP to figure out similar structural linguistic patterns among several different languages. We apply the word2vec algorithm that creates a vector representation for the words in a multidimensional space that maintains the meaning relationship between the words. From a large corpus we built this vectorial representation in a 100-dimensional space for English, Portuguese, German, Spanish, Russian, French, Chinese, Japanese, Korean, Italian, Arabic, Hebrew, Basque, Dutch, Swedish, Finnish, and Estonian. Then, we calculated the fractal dimensions of the structure that represents each language. The structures are multi-fractals with two different dimensions that we use, in addition to the token-dictionary size rate of the languages, to represent the languages in a three-dimensional space. Finally, analyzing the distance among languages in this space, we conclude that the closeness there is tendentially related to the distance in the Phylogenetic tree that depicts the lines of evolutionary descent of the languages from a common ancestor.
自然语言处理(NLP)利用人工智能算法从非结构化文本中提取有意义的信息,即缺乏元数据且难以索引或映射到标准数据库字段的内容。它有多种应用,从情感分析和文本摘要到自动语言翻译。在这项工作中,我们使用 NLP 来找出几种不同语言之间类似的结构语言模式。我们应用 word2vec 算法,该算法为多维空间中的单词创建向量表示,保持单词之间的意义关系。从一个大型语料库中,我们在 100 维空间中为英语、葡萄牙语、德语、西班牙语、俄语、法语、中文、日语、韩语、意大利语、阿拉伯语、希伯来语、巴斯克语、荷兰语、瑞典语、芬兰语和爱沙尼亚语构建了这种向量表示。然后,我们计算了代表每种语言的结构的分形维数。这些结构是具有两个不同维度的多重分形,我们除了使用语言的令牌-词典大小率之外,还将其用于在三维空间中表示语言。最后,通过分析这些空间中语言之间的距离,我们得出结论,语言之间的接近程度与描述语言从共同祖先进化而来的谱系树中的距离有趋势相关性。