Department of Medicine, Stanford Center for Biomedical Informatics, Stanford University, 1265 Welch Rd, Palo Alto, CA, 94305, USA.
Department of Biomedical Data Science, Stanford University, Palo Alto, CA, USA.
Sci Rep. 2023 Jul 7;13(1):11005. doi: 10.1038/s41598-023-38257-9.
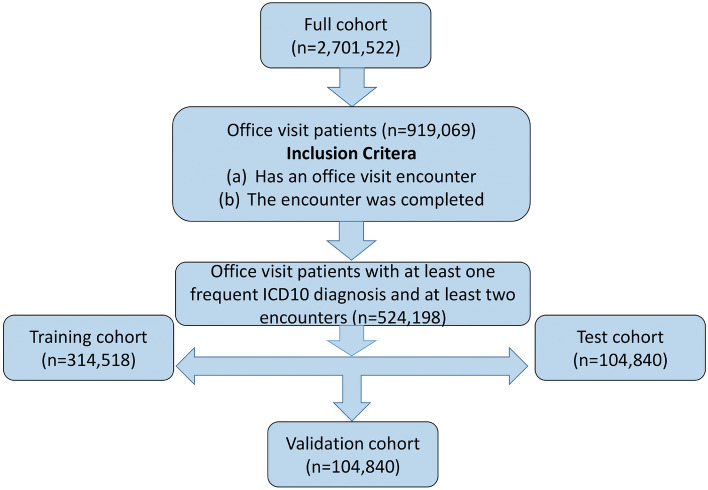
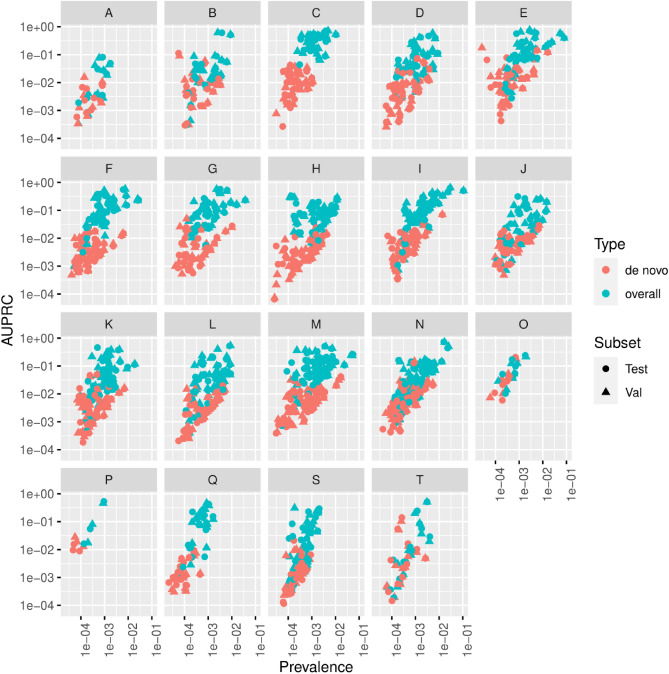
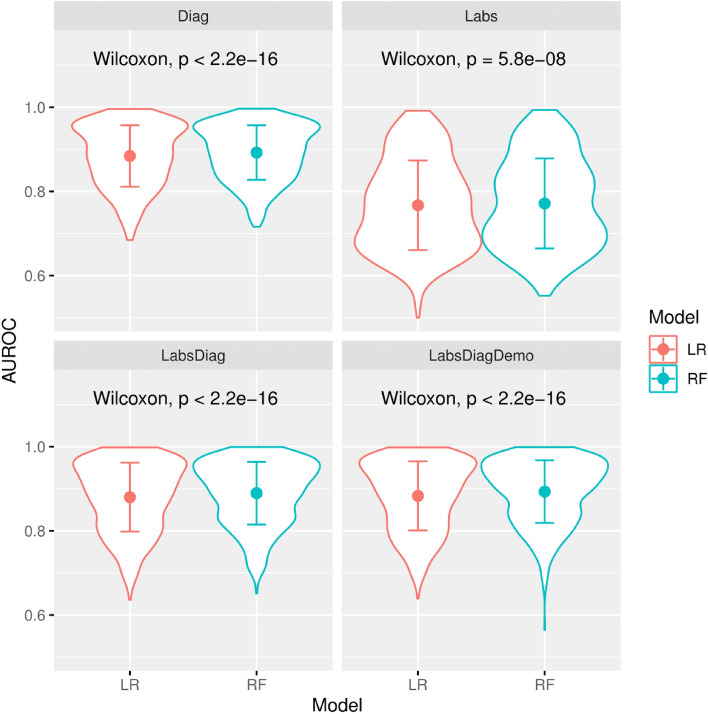
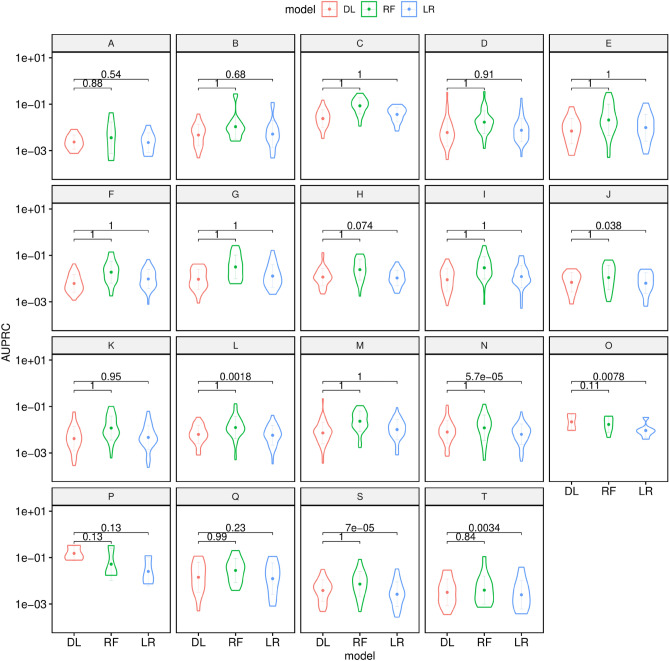
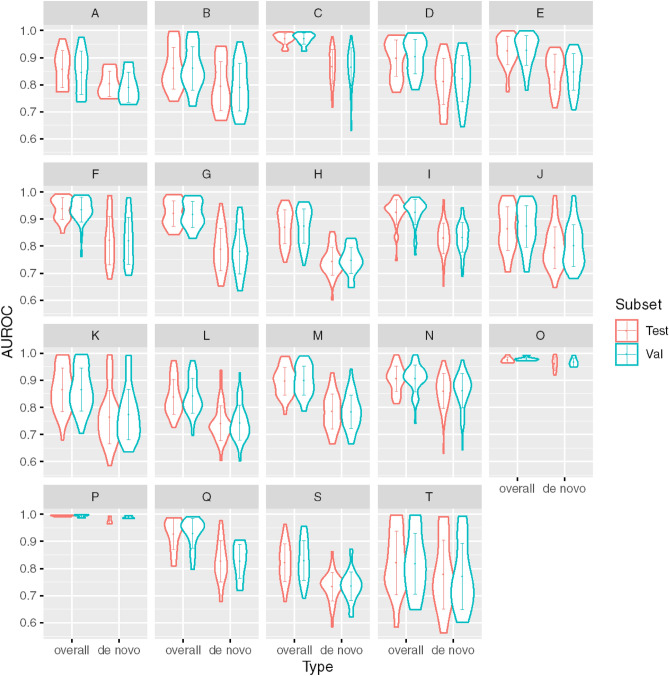
We propose an interpretable and scalable model to predict likely diagnoses at an encounter based on past diagnoses and lab results. This model is intended to aid physicians in their interaction with the electronic health records (EHR). To accomplish this, we retrospectively collected and de-identified EHR data of 2,701,522 patients at Stanford Healthcare over a time period from January 2008 to December 2016. A population-based sample of patients comprising 524,198 individuals (44% M, 56% F) with multiple encounters with at least one frequently occurring diagnosis codes were chosen. A calibrated model was developed to predict ICD-10 diagnosis codes at an encounter based on the past diagnoses and lab results, using a binary relevance based multi-label modeling strategy. Logistic regression and random forests were tested as the base classifier, and several time windows were tested for aggregating the past diagnoses and labs. This modeling approach was compared to a recurrent neural network based deep learning method. The best model used random forest as the base classifier and integrated demographic features, diagnosis codes, and lab results. The best model was calibrated and its performance was comparable or better than existing methods in terms of various metrics, including a median AUROC of 0.904 (IQR [0.838, 0.954]) over 583 diseases. When predicting the first occurrence of a disease label for a patient, the median AUROC with the best model was 0.796 (IQR [0.737, 0.868]). Our modeling approach performed comparably as the tested deep learning method, outperforming it in terms of AUROC (p < 0.001) but underperforming in terms of AUPRC (p < 0.001). Interpreting the model showed that the model uses meaningful features and highlights many interesting associations among diagnoses and lab results. We conclude that the multi-label model performs comparably with RNN based deep learning model while offering simplicity and potentially superior interpretability. While the model was trained and validated on data obtained from a single institution, its simplicity, interpretability and performance makes it a promising candidate for deployment.
我们提出了一种可解释且可扩展的模型,用于根据过去的诊断和实验室结果预测就诊时的可能诊断。该模型旨在帮助医生与电子健康记录 (EHR) 进行交互。为此,我们回顾性地收集了斯坦福医疗保健中心 2701522 名患者的 EHR 数据,时间跨度为 2008 年 1 月至 2016 年 12 月。选择了一个基于人群的患者样本,包含 524198 名个体(44%为男性,56%为女性),他们有多次就诊经历,至少有一次经常出现的诊断代码。使用基于二元相关性的多标签建模策略,开发了一种基于过去诊断和实验室结果预测就诊时 ICD-10 诊断代码的校准模型。测试了逻辑回归和随机森林作为基础分类器,并测试了几个时间窗口来聚合过去的诊断和实验室结果。将这种建模方法与基于递归神经网络的深度学习方法进行了比较。最佳模型使用随机森林作为基础分类器,并集成了人口统计学特征、诊断代码和实验室结果。最佳模型经过校准,其性能在各种指标方面与现有方法相当或更好,包括 583 种疾病的中位数 AUROC 为 0.904(IQR [0.838,0.954])。当预测患者疾病标签的首次出现时,最佳模型的中位数 AUROC 为 0.796(IQR [0.737,0.868])。我们的建模方法与测试的深度学习方法性能相当,在 AUROC 方面优于后者(p < 0.001),但在 AUPRC 方面劣于后者(p < 0.001)。对模型进行解释表明,该模型使用了有意义的特征,并突出了诊断和实验室结果之间的许多有趣关联。我们得出结论,多标签模型与基于 RNN 的深度学习模型性能相当,同时提供了简单性和潜在的更高可解释性。虽然该模型是在从单一机构获得的数据上进行训练和验证的,但它的简单性、可解释性和性能使其成为部署的有前途的候选者。