Yoon Hyunsoo, Schwedt Todd J, Chong Catherine D, Olatunde Oyekanmi, Wu Teresa
Yonsei University; Department of Industrial Engineering.
Mayo Clinic; Department of Neurology.
medRxiv. 2023 Jun 28:2023.06.26.23291909. doi: 10.1101/2023.06.26.23291909.
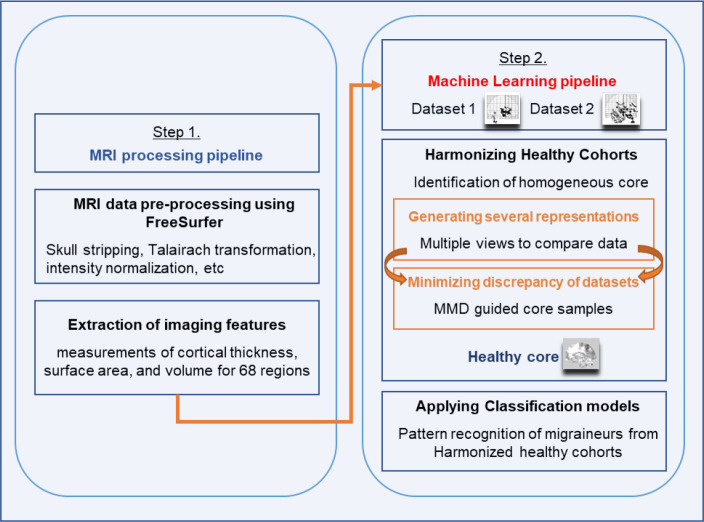
Multicenter and multi-scanner imaging studies might be needed to provide sample sizes large enough for developing accurate predictive models. However, multicenter studies, which likely include confounding factors due to subtle differences in research participant characteristics, MRI scanners, and imaging acquisition protocols, might not yield generalizable machine learning models, that is, models developed using one dataset may not be applicable to a different dataset. The generalizability of classification models is key for multi-scanner and multicenter studies, and for providing reproducible results. This study developed a data harmonization strategy to identify healthy controls with similar (homogenous) characteristics from multicenter studies to validate the generalization of machine-learning techniques for classifying individual migraine patients and healthy controls using brain MRI data. The Maximum Mean Discrepancy (MMD) was used to compare the two datasets represented in Geodesic Flow Kernel (GFK) space, capturing the data variabilities for identifying a "healthy core". A set of homogeneous healthy controls can assist in overcoming some of the unwanted heterogeneity and allow for the development of classification models that have high accuracy when applied to new datasets. Extensive experimental results show the utilization of a healthy core. One dataset consists of 120 individuals (66 with migraine and 54 healthy controls) and another dataset consists of 76 (34 with migraine and 42 healthy controls) individuals. A homogeneous dataset derived from a cohort of healthy controls improves the performance of classification models by about 25% accuracy improvements for both episodic and chronic migraineurs.
可能需要进行多中心和多扫描仪成像研究,以提供足够大的样本量来开发准确的预测模型。然而,多中心研究可能会因研究参与者特征、MRI扫描仪和成像采集协议的细微差异而包含混杂因素,可能无法产生可推广的机器学习模型,也就是说,使用一个数据集开发的模型可能不适用于另一个数据集。分类模型的可推广性是多扫描仪和多中心研究的关键,也是提供可重复结果的关键。本研究制定了一种数据协调策略,以从多中心研究中识别具有相似(同质)特征的健康对照,从而验证使用脑MRI数据对个体偏头痛患者和健康对照进行分类的机器学习技术的通用性。最大均值差异(MMD)用于比较测地线流核(GFK)空间中表示的两个数据集,捕捉数据变异性以识别“健康核心”。一组同质的健康对照有助于克服一些不必要的异质性,并允许开发在应用于新数据集时具有高精度的分类模型。大量实验结果表明了健康核心的作用。一个数据集由120名个体组成(66名偏头痛患者和54名健康对照),另一个数据集由76名个体组成(34名偏头痛患者和42名健康对照)。从一组健康对照中得出的同质数据集可将发作性和慢性偏头痛患者的分类模型性能提高约25%的准确率。