Callahan Alison, Ashley Euan, Datta Somalee, Desai Priyamvada, Ferris Todd A, Fries Jason A, Halaas Michael, Langlotz Curtis P, Mackey Sean, Posada José D, Pfeffer Michael A, Shah Nigam H
Stanford Center for Biomedical Informatics Research, Stanford University, Stanford, California, USA.
Department of Medicine, School of Medicine, Stanford University, Stanford, California, USA.
JAMIA Open. 2023 Aug 2;6(3):ooad054. doi: 10.1093/jamiaopen/ooad054. eCollection 2023 Oct.
To describe the infrastructure, tools, and services developed at Stanford Medicine to maintain its data science ecosystem and research patient data repository for clinical and translational research.
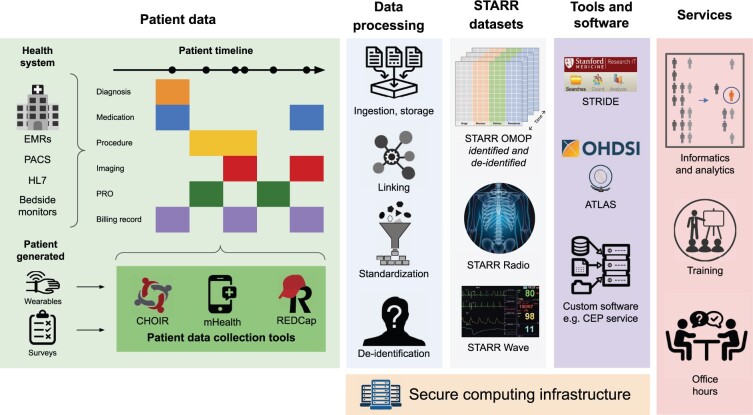
The data science ecosystem, dubbed the Stanford Data Science Resources (SDSR), includes infrastructure and tools to create, search, retrieve, and analyze patient data, as well as services for data deidentification, linkage, and processing to extract high-value information from healthcare IT systems. Data are made available via self-service and concierge access, on HIPAA compliant secure computing infrastructure supported by in-depth user training.
The Stanford Medicine Research Data Repository (STARR) functions as the SDSR data integration point, and includes electronic medical records, clinical images, text, bedside monitoring data and HL7 messages. SDSR tools include tools for electronic phenotyping, cohort building, and a search engine for patient timelines. The SDSR supports patient data collection, reproducible research, and teaching using healthcare data, and facilitates industry collaborations and large-scale observational studies.
Research patient data repositories and their underlying data science infrastructure are essential to realizing a learning health system and advancing the mission of academic medical centers. Challenges to maintaining the SDSR include ensuring sufficient financial support while providing researchers and clinicians with maximal access to data and digital infrastructure, balancing tool development with user training, and supporting the diverse needs of users.
Our experience maintaining the SDSR offers a case study for academic medical centers developing data science and research informatics infrastructure.
描述斯坦福医学中心开发的基础设施、工具和服务,以维护其用于临床和转化研究的数据科学生态系统及研究患者数据存储库。
被称为斯坦福数据科学资源(SDSR)的数据科学生态系统包括用于创建、搜索、检索和分析患者数据的基础设施和工具,以及用于数据去识别、链接和处理以从医疗信息技术系统中提取高价值信息的服务。数据通过自助服务和礼宾服务访问,在符合健康保险流通与责任法案(HIPAA)的安全计算基础设施上提供,并辅以深入的用户培训。
斯坦福医学研究数据存储库(STARR)作为SDSR的数据集成点,包括电子病历、临床图像、文本、床边监测数据和HL7消息。SDSR工具包括用于电子表型分析、队列构建的工具以及患者时间线搜索引擎。SDSR支持使用医疗数据进行患者数据收集、可重复研究和教学,并促进行业合作和大规模观察性研究。
研究患者数据存储库及其基础数据科学基础设施对于实现学习型健康系统和推进学术医疗中心的使命至关重要。维护SDSR面临的挑战包括确保足够的资金支持,同时为研究人员和临床医生提供最大程度的数据和数字基础设施访问权限,平衡工具开发与用户培训,并满足用户的多样化需求。
我们维护SDSR的经验为学术医疗中心开发数据科学和研究信息学基础设施提供了一个案例研究。