Gulsoy Mert, Yalcin Emre, Bilge Alper
Distance Education Research Center, Alaaddin Keykubat University, Antalya, Turkey.
Computer Engineering Department, Akdeniz University, Antalya, Turkey.
PeerJ Comput Sci. 2023 Jul 6;9:e1438. doi: 10.7717/peerj-cs.1438. eCollection 2023.
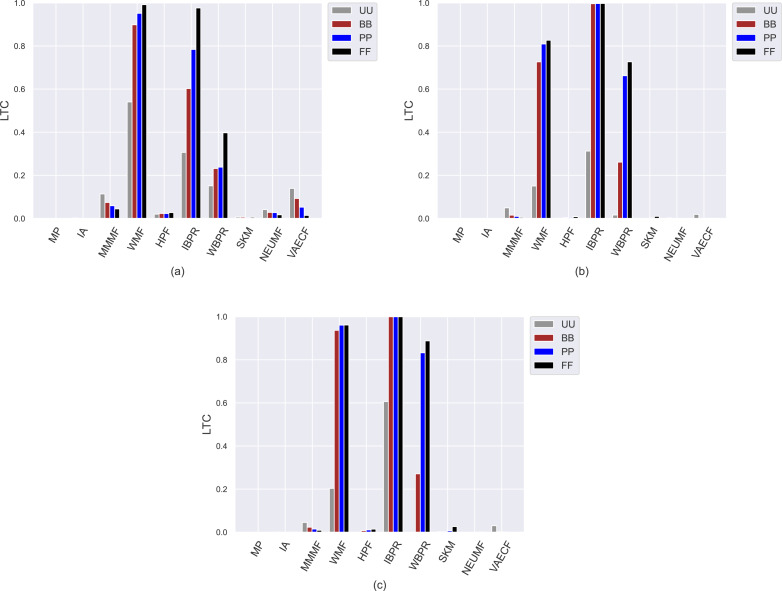
Recommender systems have become increasingly important in today's digital age, but they are not without their challenges. One of the most significant challenges is that users are not always willing to share their preferences due to privacy concerns, yet they still require decent recommendations. Privacy-preserving collaborative recommenders remedy such concerns by letting users set their privacy preferences before submitting to the recommendation provider. Another recently discussed challenge is the problem of popularity bias, where the system tends to recommend popular items more often than less popular ones, limiting the diversity of recommendations and preventing users from discovering new and interesting items. In this article, we comprehensively analyze the randomized perturbation-based data disguising procedure of privacy-preserving collaborative recommender algorithms against the popularity bias problem. For this purpose, we construct user personas of varying privacy protection levels and scrutinize the performance of ten recommendation algorithms on these user personas regarding the accuracy and beyond-accuracy perspectives. We also investigate how well-known popularity-debiasing strategies combat the issue in privacy-preserving environments. In experiments, we employ three well-known real-world datasets. The key findings of our analysis reveal that privacy-sensitive users receive unbiased and fairer recommendations that are qualified in diversity, novelty, and catalogue coverage perspectives in exchange for tolerable sacrifice from accuracy. Also, prominent popularity-debiasing strategies fall considerably short as provided privacy level improves.
在当今数字时代,推荐系统变得越来越重要,但它们并非没有挑战。最显著的挑战之一是,由于隐私问题,用户并不总是愿意分享他们的偏好,但他们仍然需要合适的推荐。隐私保护协作推荐器通过让用户在向推荐提供商提交之前设置他们的隐私偏好来解决此类问题。另一个最近讨论的挑战是流行度偏差问题,即系统倾向于更频繁地推荐流行项目而不是不太流行的项目,这限制了推荐的多样性,并阻止用户发现新的和有趣的项目。在本文中,我们针对流行度偏差问题,全面分析了基于随机扰动的数据伪装过程的隐私保护协作推荐算法。为此,我们构建了不同隐私保护级别的用户角色,并从准确性和准确性之外的角度仔细研究了十种推荐算法在这些用户角色上的性能。我们还研究了著名的流行度去偏策略在隐私保护环境中如何应对这个问题。在实验中,我们使用了三个著名的真实世界数据集。我们分析的主要发现表明,对隐私敏感的用户会收到无偏差且更公平的推荐,这些推荐在多样性、新颖性和目录覆盖方面都符合要求,不过在准确性方面会有可容忍的牺牲。此外,随着所提供的隐私级别提高,著名的流行度去偏策略的效果会大幅下降。