Bayat Nasrin, Kim Jong-Hwan, Choudhury Renoa, Kadhim Ibrahim F, Al-Mashhadani Zubaidah, Aldritz Dela Virgen Mark, Latorre Reuben, De La Paz Ricardo, Park Joon-Hyuk
Department of Electrical and Computer Engineering, University of Central Florida, Orlando, FL 32816, USA.
AI R&D Center, Korea Military Academy, Seoul 01805, Republic of Korea.
J Imaging. 2023 Aug 15;9(8):161. doi: 10.3390/jimaging9080161.
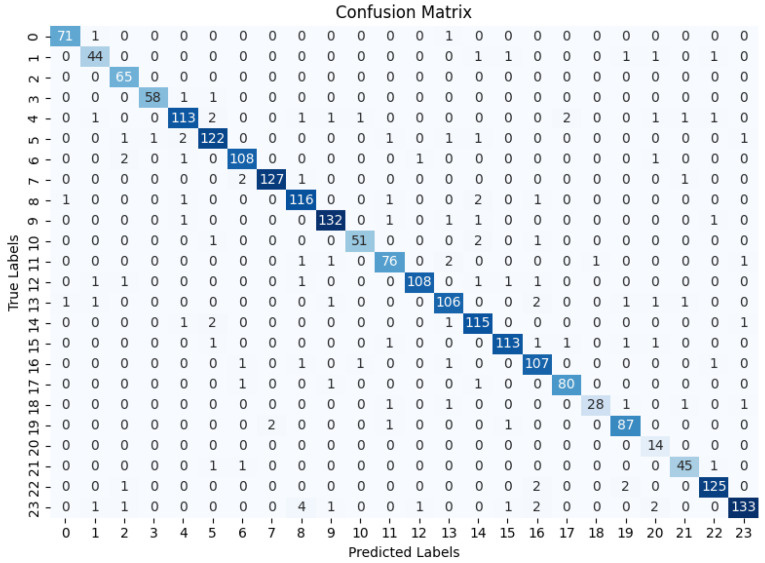
This paper presents a system that utilizes vision transformers and multimodal feedback modules to facilitate navigation and collision avoidance for the visually impaired. By implementing vision transformers, the system achieves accurate object detection, enabling the real-time identification of objects in front of the user. Semantic segmentation and the algorithms developed in this work provide a means to generate a trajectory vector of all identified objects from the vision transformer and to detect objects that are likely to intersect with the user's walking path. Audio and vibrotactile feedback modules are integrated to convey collision warning through multimodal feedback. The dataset used to create the model was captured from both indoor and outdoor settings under different weather conditions at different times across multiple days, resulting in 27,867 photos consisting of 24 different classes. Classification results showed good performance (95% accuracy), supporting the efficacy and reliability of the proposed model. The design and control methods of the multimodal feedback modules for collision warning are also presented, while the experimental validation concerning their usability and efficiency stands as an upcoming endeavor. The demonstrated performance of the vision transformer and the presented algorithms in conjunction with the multimodal feedback modules show promising prospects of its feasibility and applicability for the navigation assistance of individuals with vision impairment.
本文提出了一种利用视觉变换器和多模态反馈模块来辅助视障人士导航和避免碰撞的系统。通过实现视觉变换器,该系统实现了精确的目标检测,能够实时识别用户前方的物体。语义分割以及本研究中开发的算法提供了一种方法,可从视觉变换器生成所有已识别物体的轨迹向量,并检测可能与用户行走路径相交的物体。集成了音频和振动触觉反馈模块,以通过多模态反馈传达碰撞警告。用于创建模型的数据集是在多天的不同时间、不同天气条件下,从室内和室外场景中采集的,共得到27867张照片,包含24个不同类别。分类结果显示出良好的性能(准确率95%),支持了所提出模型的有效性和可靠性。还介绍了用于碰撞警告的多模态反馈模块的设计和控制方法,而关于其可用性和效率的实验验证是即将开展的工作。视觉变换器和所提出算法与多模态反馈模块相结合所展示的性能,显示出其在为视障人士提供导航辅助方面的可行性和适用性的广阔前景。