School of Industrial and Management Engineering, Korea University, Seoul, Republic of Korea.
PLoS One. 2023 Sep 14;18(9):e0291545. doi: 10.1371/journal.pone.0291545. eCollection 2023.
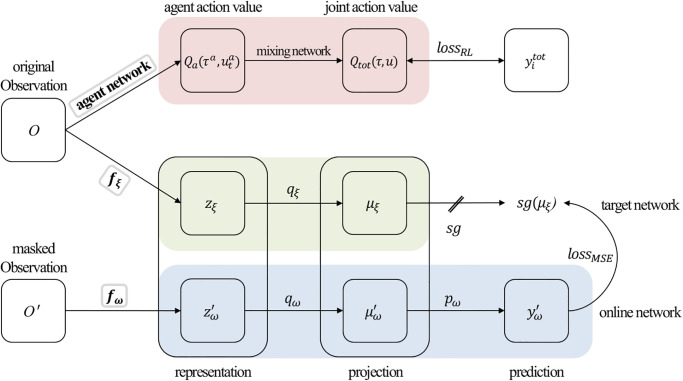
Deep reinforcement learning (DRL) is a powerful approach that combines reinforcement learning (RL) and deep learning to address complex decision-making problems in high-dimensional environments. Although DRL has been remarkably successful, its low sample efficiency necessitates extensive training times and large amounts of data to learn optimal policies. These limitations are more pronounced in the context of multi-agent reinforcement learning (MARL). To address these limitations, various studies have been conducted to improve DRL. In this study, we propose an approach that combines a masked reconstruction task with QMIX (M-QMIX). By introducing a masked reconstruction task as an auxiliary task, we aim to achieve enhanced sample efficiency-a fundamental limitation of RL in multi-agent systems. Experiments were conducted using the StarCraft II micromanagement benchmark to validate the effectiveness of the proposed method. We used 11 scenarios comprising five easy, three hard, and three very hard scenarios. We particularly focused on using a limited number of time steps for each scenario to demonstrate the improved sample efficiency. Compared to QMIX, the proposed method is superior in eight of the 11 scenarios. These results provide strong evidence that the proposed method is more sample-efficient than QMIX, demonstrating that it effectively addresses the limitations of DRL in multi-agent systems.
深度强化学习(DRL)是一种强大的方法,它结合了强化学习(RL)和深度学习,以解决高维环境中的复杂决策问题。尽管 DRL 已经取得了显著的成功,但它的低样本效率需要大量的训练时间和数据来学习最优策略。这些限制在多智能体强化学习(MARL)的背景下更为明显。为了解决这些限制,已经进行了各种研究来改进 DRL。在本研究中,我们提出了一种结合掩蔽重建任务和 QMIX(M-QMIX)的方法。通过引入掩蔽重建任务作为辅助任务,我们旨在实现增强的样本效率——这是 RL 在多智能体系统中的一个基本限制。使用星际争霸 II 微观管理基准进行实验,以验证所提出方法的有效性。我们使用了 11 个场景,其中包括 5 个简单、3 个困难和 3 个非常困难的场景。我们特别关注在每个场景中使用有限的时间步骤来演示提高的样本效率。与 QMIX 相比,所提出的方法在 11 个场景中的 8 个场景中表现更好。这些结果提供了强有力的证据表明,所提出的方法比 QMIX 更具样本效率,有效地解决了 DRL 在多智能体系统中的限制。