Department of Diagnostic Radiology, Graduate School of Medical Sciences, Kumamoto University, 1-1-1 Honjo, Chuo-ku, Kumamoto-shi, Kumamoto, 860-8556, Japan.
Department of Medical Physics, Faculty of Life Sciences, Kumamoto University, Honjo 1-1-1, Kumamoto, 860-8556, Japan.
Jpn J Radiol. 2024 Feb;42(2):190-200. doi: 10.1007/s11604-023-01487-y. Epub 2023 Sep 15.
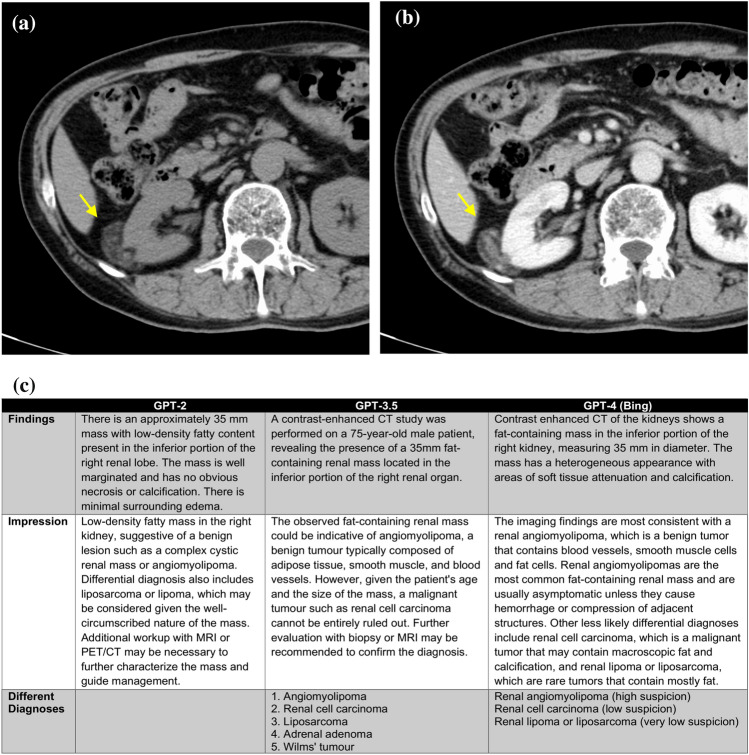
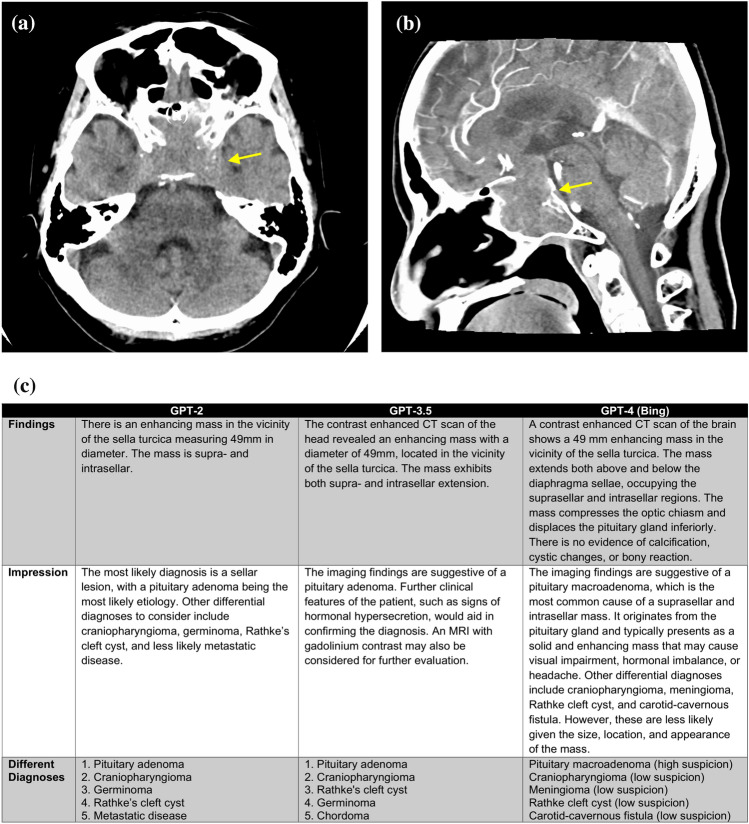
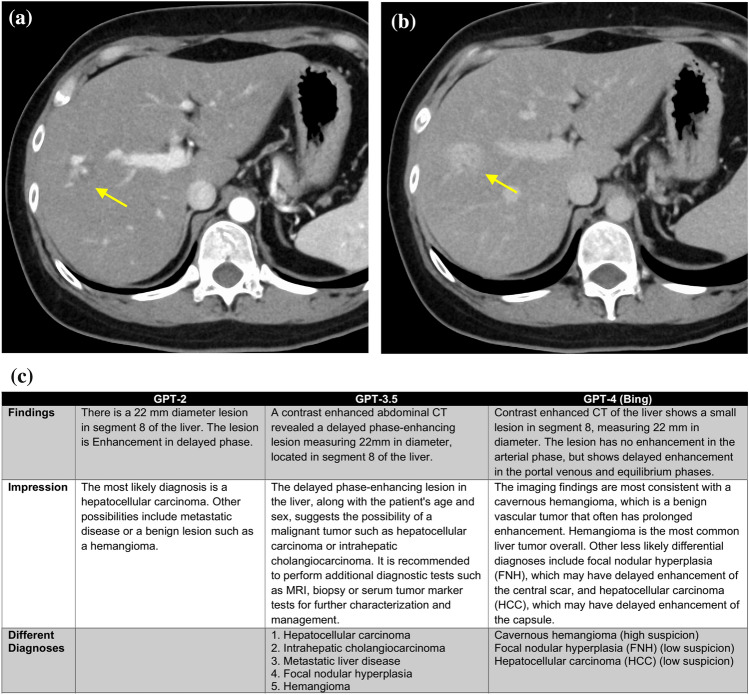
In this preliminary study, we aimed to evaluate the potential of the generative pre-trained transformer (GPT) series for generating radiology reports from concise imaging findings and compare its performance with radiologist-generated reports.
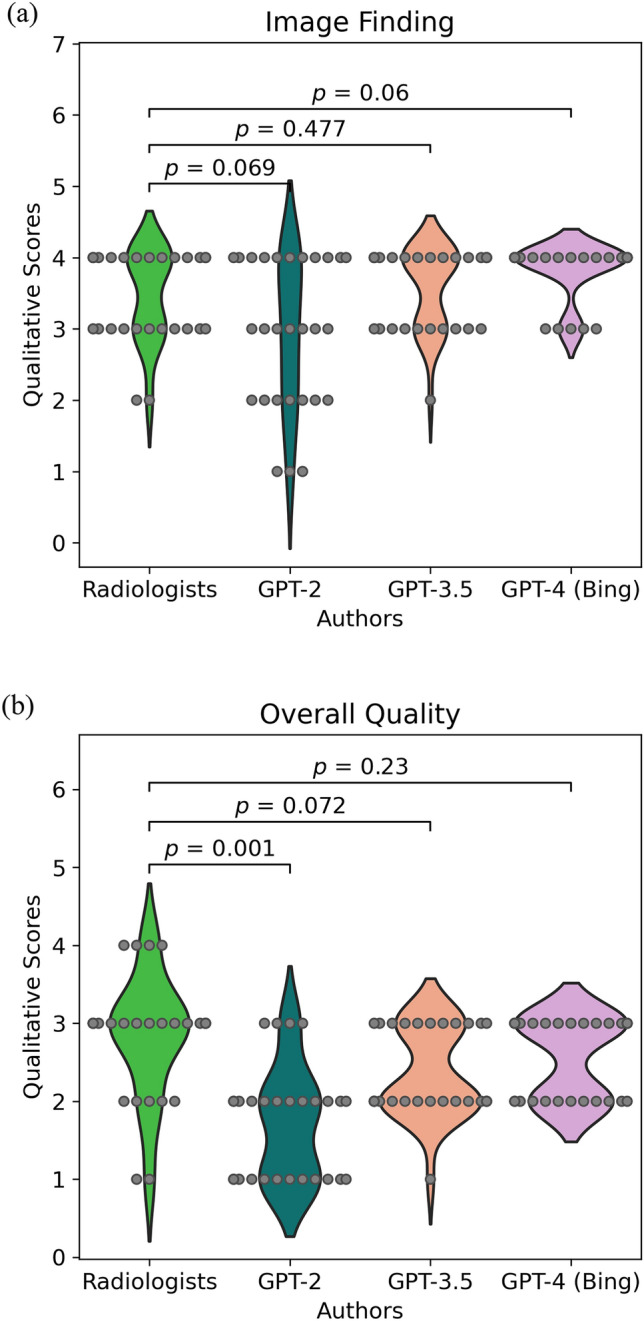
This retrospective study involved 28 patients who underwent computed tomography (CT) scans and had a diagnosed disease with typical imaging findings. Radiology reports were generated using GPT-2, GPT-3.5, and GPT-4 based on the patient's age, gender, disease site, and imaging findings. We calculated the top-1, top-5 accuracy, and mean average precision (MAP) of differential diagnoses for GPT-2, GPT-3.5, GPT-4, and radiologists. Two board-certified radiologists evaluated the grammar and readability, image findings, impression, differential diagnosis, and overall quality of all reports using a 4-point scale.
Top-1 and Top-5 accuracies for the different diagnoses were highest for radiologists, followed by GPT-4, GPT-3.5, and GPT-2, in that order (Top-1: 1.00, 0.54, 0.54, and 0.21, respectively; Top-5: 1.00, 0.96, 0.89, and 0.54, respectively). There were no significant differences in qualitative scores about grammar and readability, image findings, and overall quality between radiologists and GPT-3.5 or GPT-4 (p > 0.05). However, qualitative scores of the GPT series in impression and differential diagnosis scores were significantly lower than those of radiologists (p < 0.05).
Our preliminary study suggests that GPT-3.5 and GPT-4 have the possibility to generate radiology reports with high readability and reasonable image findings from very short keywords; however, concerns persist regarding the accuracy of impressions and differential diagnoses, thereby requiring verification by radiologists.
在这项初步研究中,我们旨在评估生成式预训练转换器(GPT)系列从简洁的影像学发现中生成放射学报告的潜力,并将其与放射科医生生成的报告进行比较。
这项回顾性研究涉及 28 名接受计算机断层扫描(CT)检查且具有典型影像学表现的确诊疾病的患者。根据患者的年龄、性别、疾病部位和影像学表现,使用 GPT-2、GPT-3.5 和 GPT-4 生成放射学报告。我们计算了 GPT-2、GPT-3.5、GPT-4 和放射科医生对鉴别诊断的准确率、top-5 准确率和平均准确率(MAP)。两位具有董事会认证的放射科医生使用 4 分制评估了所有报告的语法和可读性、图像发现、印象、鉴别诊断和整体质量。
不同诊断的 top-1 和 top-5 准确率最高的是放射科医生,其次是 GPT-4、GPT-3.5 和 GPT-2(top-1:1.00、0.54、0.54 和 0.21;top-5:1.00、0.96、0.89 和 0.54)。放射科医生与 GPT-3.5 或 GPT-4 之间在语法和可读性、图像发现和整体质量方面的定性评分没有显著差异(p>0.05)。然而,GPT 系列在印象和鉴别诊断评分方面的定性评分明显低于放射科医生(p<0.05)。
我们的初步研究表明,GPT-3.5 和 GPT-4 有可能从非常短的关键字生成具有高可读性和合理图像发现的放射学报告;然而,对印象和鉴别诊断的准确性仍存在担忧,因此需要放射科医生进行验证。