Horiuchi Daisuke, Tatekawa Hiroyuki, Oura Tatsushi, Shimono Taro, Walston Shannon L, Takita Hirotaka, Matsushita Shu, Mitsuyama Yasuhito, Miki Yukio, Ueda Daiju
Department of Diagnostic and Interventional Radiology, Graduate School of Medicine, Osaka Metropolitan University, Osaka, Japan.
Department of Artificial Intelligence, Graduate School of Medicine, Osaka Metropolitan University, Osaka, Japan.
Eur Radiol. 2025 Jan;35(1):506-516. doi: 10.1007/s00330-024-10902-5. Epub 2024 Jul 12.
To compare the diagnostic accuracy of Generative Pre-trained Transformer (GPT)-4-based ChatGPT, GPT-4 with vision (GPT-4V) based ChatGPT, and radiologists in musculoskeletal radiology.
We included 106 "Test Yourself" cases from Skeletal Radiology between January 2014 and September 2023. We input the medical history and imaging findings into GPT-4-based ChatGPT and the medical history and images into GPT-4V-based ChatGPT, then both generated a diagnosis for each case. Two radiologists (a radiology resident and a board-certified radiologist) independently provided diagnoses for all cases. The diagnostic accuracy rates were determined based on the published ground truth. Chi-square tests were performed to compare the diagnostic accuracy of GPT-4-based ChatGPT, GPT-4V-based ChatGPT, and radiologists.
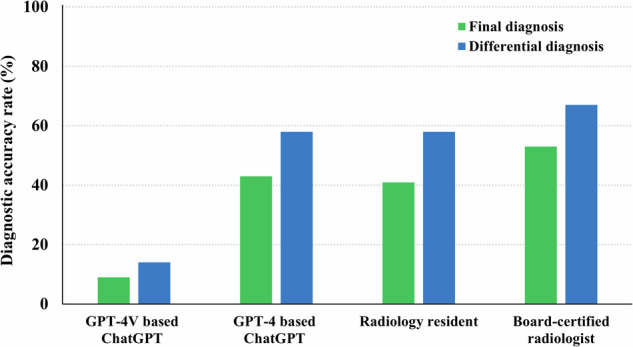
GPT-4-based ChatGPT significantly outperformed GPT-4V-based ChatGPT (p < 0.001) with accuracy rates of 43% (46/106) and 8% (9/106), respectively. The radiology resident and the board-certified radiologist achieved accuracy rates of 41% (43/106) and 53% (56/106). The diagnostic accuracy of GPT-4-based ChatGPT was comparable to that of the radiology resident, but was lower than that of the board-certified radiologist although the differences were not significant (p = 0.78 and 0.22, respectively). The diagnostic accuracy of GPT-4V-based ChatGPT was significantly lower than those of both radiologists (p < 0.001 and < 0.001, respectively).
GPT-4-based ChatGPT demonstrated significantly higher diagnostic accuracy than GPT-4V-based ChatGPT. While GPT-4-based ChatGPT's diagnostic performance was comparable to radiology residents, it did not reach the performance level of board-certified radiologists in musculoskeletal radiology.
GPT-4-based ChatGPT outperformed GPT-4V-based ChatGPT and was comparable to radiology residents, but it did not reach the level of board-certified radiologists in musculoskeletal radiology. Radiologists should comprehend ChatGPT's current performance as a diagnostic tool for optimal utilization.
This study compared the diagnostic performance of GPT-4-based ChatGPT, GPT-4V-based ChatGPT, and radiologists in musculoskeletal radiology. GPT-4-based ChatGPT was comparable to radiology residents, but did not reach the level of board-certified radiologists. When utilizing ChatGPT, it is crucial to input appropriate descriptions of imaging findings rather than the images.
比较基于生成式预训练变换器(GPT)-4的ChatGPT、基于GPT-4且具备视觉功能(GPT-4V)的ChatGPT以及放射科医生在肌肉骨骼放射学方面的诊断准确性。
我们纳入了2014年1月至2023年9月间《骨骼放射学》中的106个“自我测试”病例。我们将病史和影像检查结果输入基于GPT-4的ChatGPT,将病史和影像输入基于GPT-4V的ChatGPT,然后二者分别针对每个病例生成诊断结果。两位放射科医生(一名放射科住院医师和一名获得委员会认证的放射科医生)独立对所有病例进行诊断。根据已公布的真实诊断结果确定诊断准确率。进行卡方检验以比较基于GPT-4的ChatGPT、基于GPT-4V的ChatGPT和放射科医生的诊断准确性。
基于GPT-4的ChatGPT显著优于基于GPT-4V的ChatGPT(p < 0.001),准确率分别为43%(46/106)和8%(9/106)。放射科住院医师和获得委员会认证的放射科医生的准确率分别为41%(43/106)和53%(56/106)。基于GPT-4的ChatGPT的诊断准确性与放射科住院医师相当,但低于获得委员会认证的放射科医生,尽管差异不显著(分别为p = 0.78和0.22)。基于GPT-4V的ChatGPT的诊断准确性显著低于两位放射科医生(分别为p < 0.001和< 0.001)。
基于GPT-4的ChatGPT的诊断准确性显著高于基于GPT-4V的ChatGPT。虽然基于GPT-4的ChatGPT的诊断性能与放射科住院医师相当,但在肌肉骨骼放射学方面未达到获得委员会认证的放射科医生的性能水平。
基于GPT-4的ChatGPT优于基于GPT-4V的ChatGPT,且与放射科住院医师相当,但在肌肉骨骼放射学方面未达到获得委员会认证的放射科医生的水平。放射科医生应了解ChatGPT作为诊断工具的当前性能,以便最佳利用。
本研究比较了基于GPT-4的ChatGPT、基于GPT-4V的ChatGPT和放射科医生在肌肉骨骼放射学方面的诊断性能。基于GPT-4的ChatGPT与放射科住院医师相当,但未达到获得委员会认证的放射科医生的水平。使用ChatGPT时,输入影像学检查结果的适当描述而非图像至关重要。