Department of Diagnostic Imaging, Chaim Sheba Medical Center, Ramat Gan, Israel.
Faculty of Medicine, Tel-Aviv University, Tel-Aviv, Israel.
Sci Rep. 2023 Oct 1;13(1):16492. doi: 10.1038/s41598-023-43436-9.
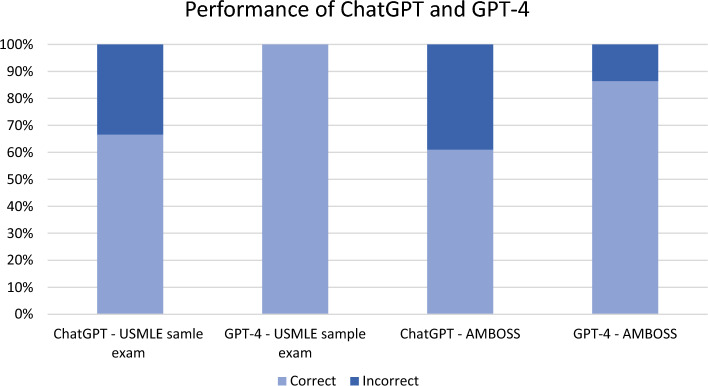
The United States Medical Licensing Examination (USMLE) has been a subject of performance study for artificial intelligence (AI) models. However, their performance on questions involving USMLE soft skills remains unexplored. This study aimed to evaluate ChatGPT and GPT-4 on USMLE questions involving communication skills, ethics, empathy, and professionalism. We used 80 USMLE-style questions involving soft skills, taken from the USMLE website and the AMBOSS question bank. A follow-up query was used to assess the models' consistency. The performance of the AI models was compared to that of previous AMBOSS users. GPT-4 outperformed ChatGPT, correctly answering 90% compared to ChatGPT's 62.5%. GPT-4 showed more confidence, not revising any responses, while ChatGPT modified its original answers 82.5% of the time. The performance of GPT-4 was higher than that of AMBOSS's past users. Both AI models, notably GPT-4, showed capacity for empathy, indicating AI's potential to meet the complex interpersonal, ethical, and professional demands intrinsic to the practice of medicine.
美国医师执照考试(USMLE)一直是人工智能(AI)模型的性能研究课题。然而,它们在涉及 USMLE 软技能的问题上的表现仍未得到探索。本研究旨在评估 ChatGPT 和 GPT-4 在涉及沟通技巧、伦理、同理心和专业精神的 USMLE 问题上的表现。我们使用了 80 个来自 USMLE 网站和 AMBOSS 题库的涉及软技能的 USMLE 风格问题。后续查询用于评估模型的一致性。AI 模型的性能与之前的 AMBOSS 用户进行了比较。GPT-4 的表现优于 ChatGPT,正确回答了 90%的问题,而 ChatGPT 的正确回答率为 62.5%。GPT-4 表现出更高的信心,没有修改任何回答,而 ChatGPT 有 82.5%的时间修改了其原始回答。GPT-4 的表现高于 AMBOSS 过去用户的表现。这两个 AI 模型,特别是 GPT-4,都表现出了同理心的能力,这表明 AI 有潜力满足医学实践中固有的复杂的人际、伦理和专业要求。