Jain Khushboo, Kaushik Keshav, Gupta Sachin Kumar, Mahajan Shubham, Kadry Seifedine
School of Computer Science, University of Petroleum and Energy Studies, Dehradun, India.
Department of Electronics and Communication Engineering, Central University of Jammu, Samba, Jammu, Jammu and Kashmir, 181143, India.
Sci Rep. 2023 Oct 9;13(1):17042. doi: 10.1038/s41598-023-44111-9.
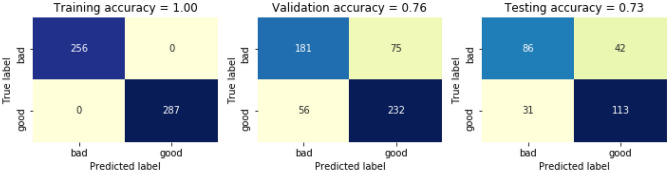
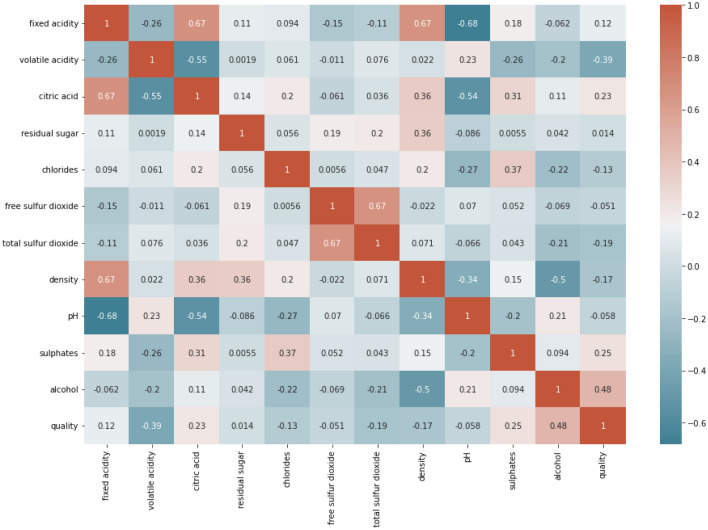
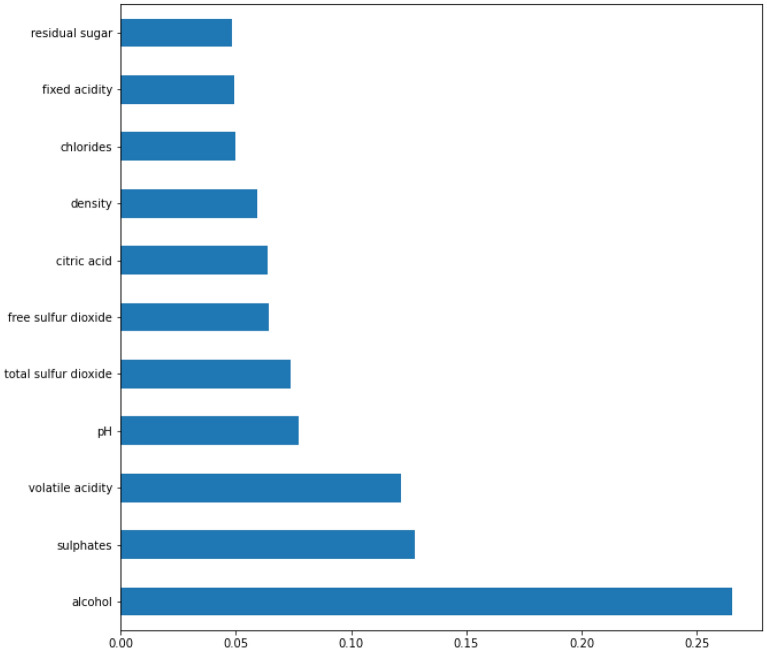
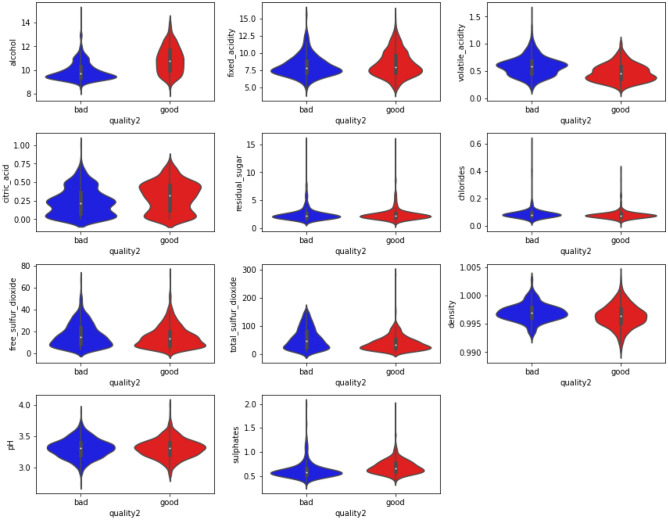
The certification of wine quality is essential to the wine industry. The main goal of this work is to develop a machine learning model to forecast wine quality using the dataset. We utilised samples from the red wine dataset (RWD) with eleven distinct physiochemical properties. With the initial RWD, five machine learning (ML) models were trained and put to the test. The most accurate algorithms are Random Forest (RF) and Extreme Gradient Boosting (XGBoost). Using these two ML approaches, the top three features from a total of eleven features are chosen, and ML analysis is performed on the remaining features. Several graphs are employed to demonstrate the feature importance based on the XGBoost model and RF. Wine quality was predicted using relevant characteristics, often referred to as fundamental elements, that were shown to be essential during the feature selection procedure. When trained and tested without feature selection, with feature selection (RF), and with key attributes, the XGBoost classifier displayed 100% accuracy. In the presence of essential variables, the RF classifier performed better. Finally, to assess the precision of their predictions, the authors trained an RF classifier, validated it, and changed its hyperparameters. To address collinearity and decrease the quantity of predictors without sacrificing model accuracy, we have also used cluster analysis.
葡萄酒质量认证对葡萄酒行业至关重要。这项工作的主要目标是开发一种机器学习模型,使用该数据集预测葡萄酒质量。我们使用了来自红葡萄酒数据集(RWD)的样本,这些样本具有11种不同的理化特性。利用初始的RWD,训练并测试了五个机器学习(ML)模型。最准确的算法是随机森林(RF)和极端梯度提升(XGBoost)。使用这两种ML方法,从总共11个特征中选择前三个特征,并对其余特征进行ML分析。使用几个图表来展示基于XGBoost模型和RF的特征重要性。使用在特征选择过程中显示为必不可少的相关特征(通常称为基本要素)来预测葡萄酒质量。当不进行特征选择、进行特征选择(RF)以及使用关键属性进行训练和测试时,XGBoost分类器的准确率均为100%。在存在基本变量的情况下,RF分类器表现更好。最后,为了评估预测的精度,作者训练了一个RF分类器,对其进行验证并更改其超参数。为了解决共线性问题并在不牺牲模型准确性的情况下减少预测变量的数量,我们还使用了聚类分析。