Voskergian Daniel, Bakir-Gungor Burcu, Yousef Malik
Computer Engineering Department, Faculty of Engineering, Al-Quds University, Jerusalem, Palestine.
Department of Computer Engineering, Faculty of Engineering, Abdullah Gul University, Kayseri, Türkiye.
Front Genet. 2023 Oct 5;14:1243874. doi: 10.3389/fgene.2023.1243874. eCollection 2023.
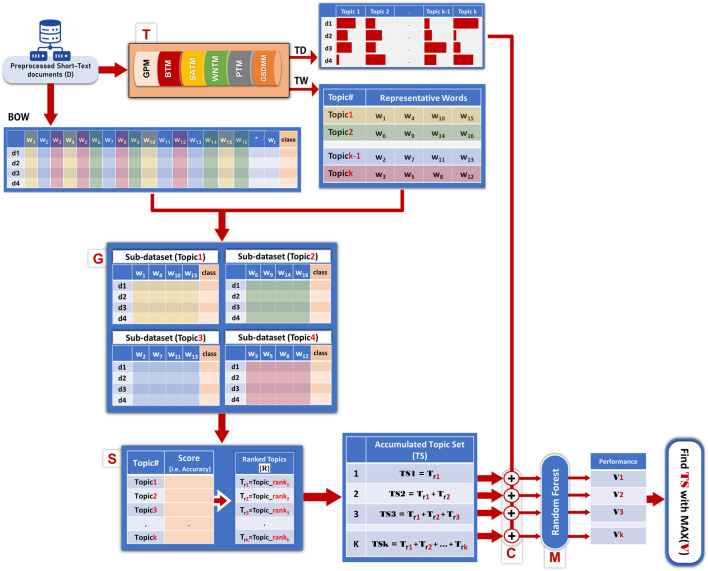
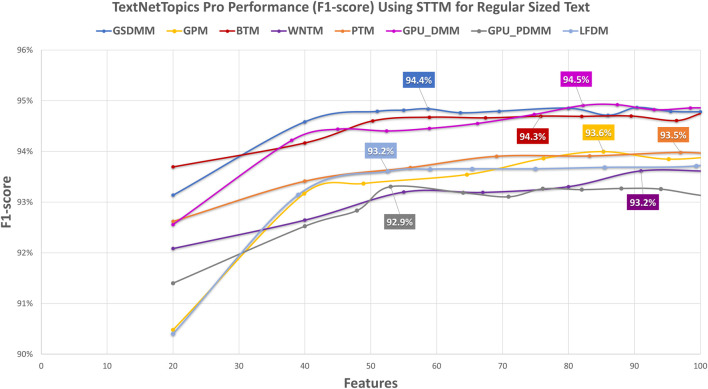
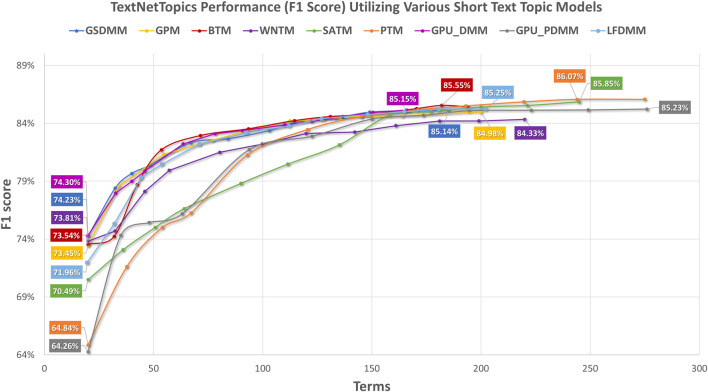
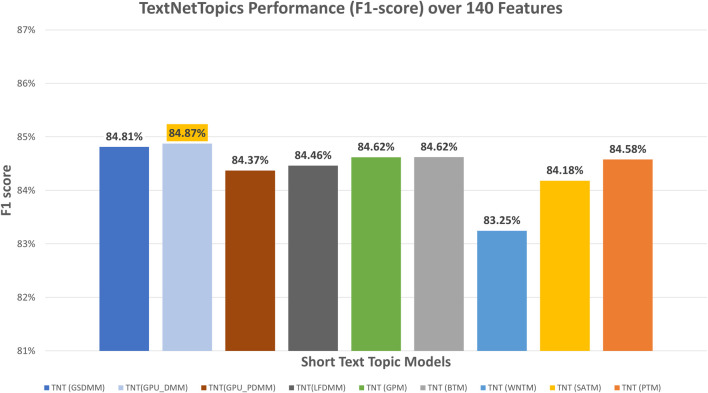
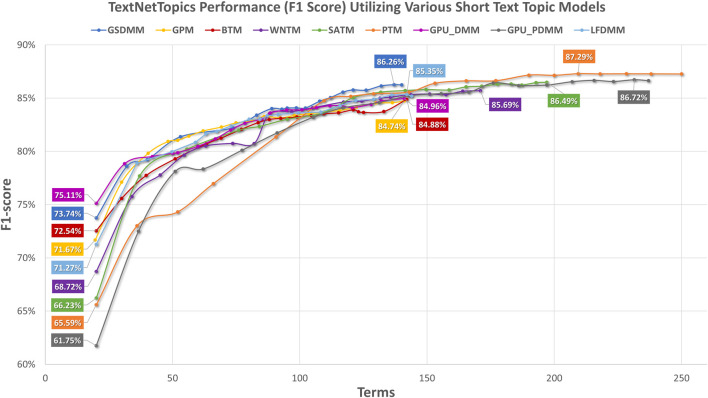
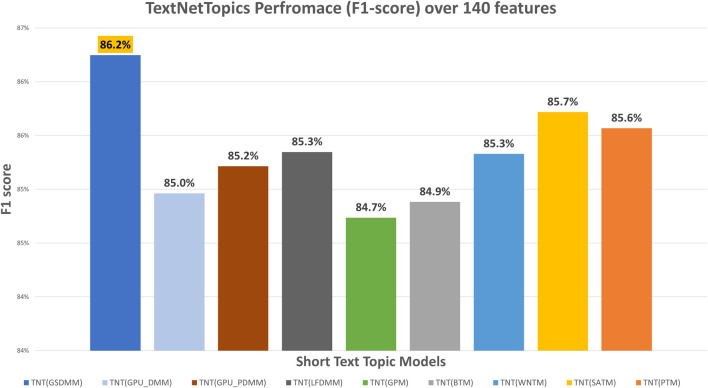
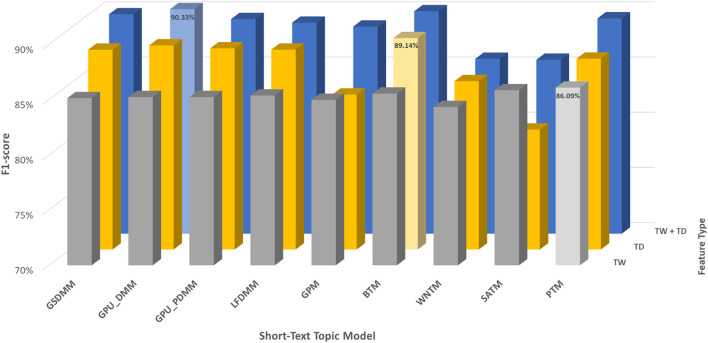
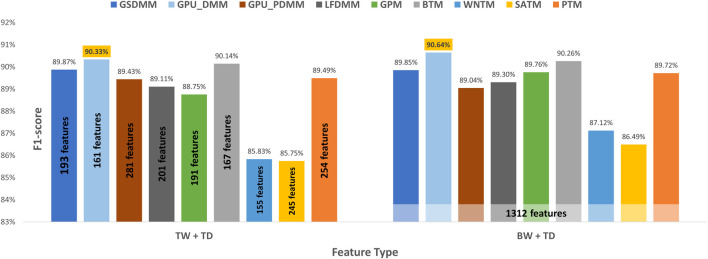
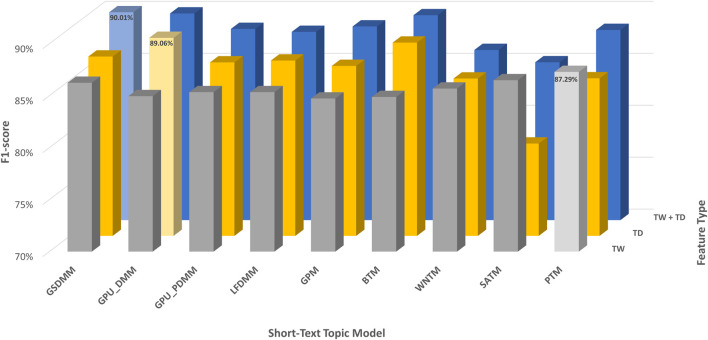
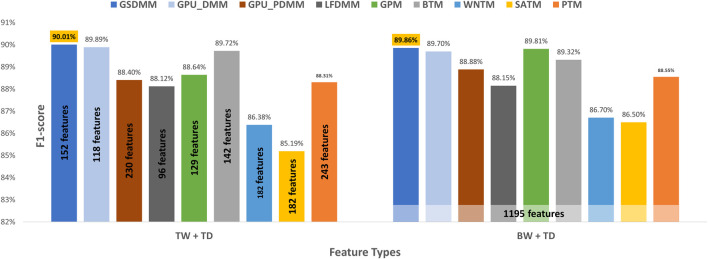
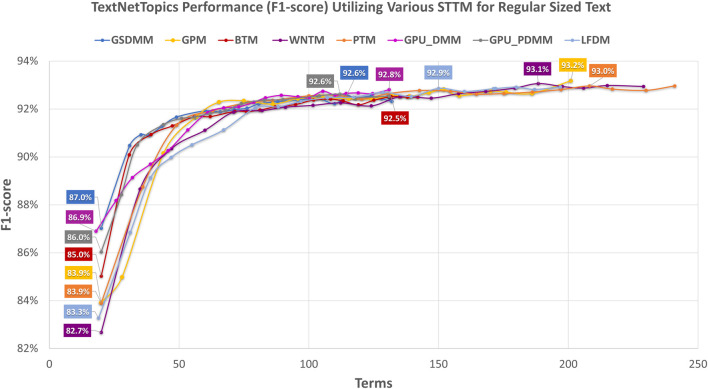
With the exponential growth in the daily publication of scientific articles, automatic classification and categorization can assist in assigning articles to a predefined category. Article titles are concise descriptions of the articles' content with valuable information that can be useful in document classification and categorization. However, shortness, data sparseness, limited word occurrences, and the inadequate contextual information of scientific document titles hinder the direct application of conventional text mining and machine learning algorithms on these short texts, making their classification a challenging task. This study firstly explores the performance of our earlier study, TextNetTopics on the short text. Secondly, here we propose an advanced version called , which is a novel short-text classification framework that utilizes a promising combination of lexical features organized in topics of words and topic distribution extracted by a topic model to alleviate the data-sparseness problem when classifying short texts. We evaluate our proposed approach using nine state-of-the-art short-text topic models on two publicly available datasets of scientific article titles as short-text documents. The first dataset is related to the Biomedical field, and the other one is related to Computer Science publications. Additionally, we comparatively evaluate the predictive performance of the models generated with and without using the abstracts. Finally, we demonstrate the robustness and effectiveness of the proposed approach in handling the imbalanced data, particularly in the classification of Drug-Induced Liver Injury articles as part of the CAMDA challenge. Taking advantage of the semantic information detected by topic models proved to be a reliable way to improve the overall performance of ML classifiers.
随着科学文章每日发表数量呈指数级增长,自动分类有助于将文章归入预定义类别。文章标题是对文章内容的简洁描述,包含对文档分类有用的宝贵信息。然而,科学文档标题的简短性、数据稀疏性、有限的词频以及上下文信息不足,阻碍了传统文本挖掘和机器学习算法在这些短文本上的直接应用,使其分类成为一项具有挑战性的任务。本研究首先探讨我们早期的研究TextNetTopics在短文本上的性能。其次,我们在此提出一个名为 的高级版本,它是一种新颖的短文本分类框架,利用按词主题组织的词汇特征和主题模型提取的主题分布的有前景组合,以缓解短文本分类时的数据稀疏问题。我们使用九个最先进的短文本主题模型,在两个作为短文本文档的科学文章标题公开可用数据集上评估我们提出的方法。第一个数据集与生物医学领域相关,另一个与计算机科学出版物相关。此外,我们比较评估了使用和不使用摘要生成的模型的预测性能。最后,我们展示了所提出方法在处理不平衡数据方面的稳健性和有效性,特别是在作为CAMDA挑战一部分的药物性肝损伤文章分类中。利用主题模型检测到的语义信息被证明是提高机器学习分类器整体性能的可靠方法。