Dramé Khadim, Mougin Fleur, Diallo Gayo
University of Bordeaux, ERIAS, Centre INSERM U897, F-33000, Bordeaux, France.
J Biomed Semantics. 2016 Jun 16;7:40. doi: 10.1186/s13326-016-0073-1.
With the large and increasing volume of textual data, automated methods for identifying significant topics to classify textual documents have received a growing interest. While many efforts have been made in this direction, it still remains a real challenge. Moreover, the issue is even more complex as full texts are not always freely available. Then, using only partial information to annotate these documents is promising but remains a very ambitious issue.
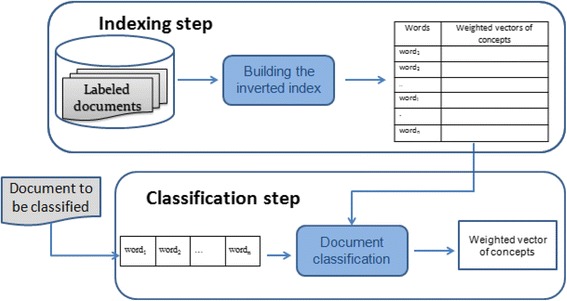
We propose two classification methods: a k-nearest neighbours (kNN)-based approach and an explicit semantic analysis (ESA)-based approach. Although the kNN-based approach is widely used in text classification, it needs to be improved to perform well in this specific classification problem which deals with partial information. Compared to existing kNN-based methods, our method uses classical Machine Learning (ML) algorithms for ranking the labels. Additional features are also investigated in order to improve the classifiers' performance. In addition, the combination of several learning algorithms with various techniques for fixing the number of relevant topics is performed. On the other hand, ESA seems promising for this classification task as it yielded interesting results in related issues, such as semantic relatedness computation between texts and text classification. Unlike existing works, which use ESA for enriching the bag-of-words approach with additional knowledge-based features, our ESA-based method builds a standalone classifier. Furthermore, we investigate if the results of this method could be useful as a complementary feature of our kNN-based approach.
Experimental evaluations performed on large standard annotated datasets, provided by the BioASQ organizers, show that the kNN-based method with the Random Forest learning algorithm achieves good performances compared with the current state-of-the-art methods, reaching a competitive f-measure of 0.55 % while the ESA-based approach surprisingly yielded unsatisfactory results.
We have proposed simple classification methods suitable to annotate textual documents using only partial information. They are therefore adequate for large multi-label classification and particularly in the biomedical domain. Thus, our work contributes to the extraction of relevant information from unstructured documents in order to facilitate their automated processing. Consequently, it could be used for various purposes, including document indexing, information retrieval, etc.
随着文本数据量的不断增大且持续增长,用于识别重要主题以对文本文档进行分类的自动化方法越来越受到关注。尽管在这方面已经做出了许多努力,但它仍然是一个真正的挑战。此外,由于全文并非总是可免费获取,这个问题变得更加复杂。因此,仅使用部分信息来注释这些文档是有前景的,但仍然是一个极具挑战性的问题。
我们提出了两种分类方法:一种基于k近邻(kNN)的方法和一种基于显式语义分析(ESA)的方法。尽管基于kNN的方法在文本分类中被广泛使用,但在处理部分信息的这个特定分类问题中,它需要改进才能表现良好。与现有的基于kNN的方法相比,我们的方法使用经典机器学习(ML)算法对标签进行排序。还研究了其他特征以提高分类器的性能。此外,将几种学习算法与各种确定相关主题数量的技术相结合。另一方面,ESA在这个分类任务中似乎很有前景,因为它在相关问题上取得了有趣的结果,如文本之间的语义相关性计算和文本分类。与现有的使用ESA通过基于知识的附加特征来丰富词袋方法的工作不同,我们基于ESA的方法构建了一个独立的分类器。此外,我们研究了该方法的结果是否可以作为我们基于kNN的方法的补充特征。
对由BioASQ组织者提供的大型标准注释数据集进行的实验评估表明,与当前的最先进方法相比,基于随机森林学习算法的基于kNN的方法取得了良好的性能,达到了具有竞争力的0.55%的F值,而基于ESA的方法出人意料地产生了不令人满意的结果。
我们提出了适合仅使用部分信息来注释文本文档的简单分类方法。因此,它们适用于大型多标签分类,特别是在生物医学领域。因此,我们的工作有助于从非结构化文档中提取相关信息,以促进其自动化处理。因此,它可用于各种目的,包括文档索引、信息检索等。