Fang Zihao, Chen Dejun, Zeng Yunxiu, Wang Tao, Xu Kai
College of Systems Engineering, National University of Defense Technology, Changsha 410000, China.
Entropy (Basel). 2023 Oct 4;25(10):1415. doi: 10.3390/e25101415.
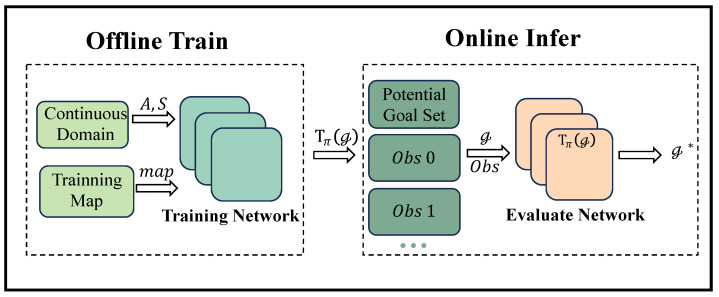
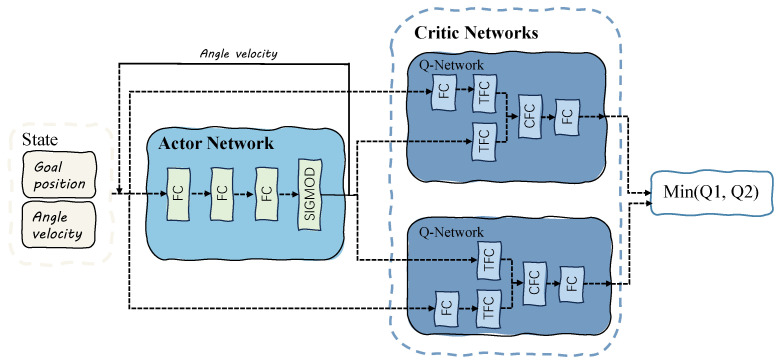
The problem of goal recognition involves inferring the high-level task goals of an agent based on observations of its behavior in an environment. Current methods for achieving this task rely on offline comparison inference of observed behavior in discrete environments, which presents several challenges. First, accurately modeling the behavior of the observed agent requires significant computational resources. Second, continuous simulation environments cannot be accurately recognized using existing methods. Finally, real-time computing power is required to infer the likelihood of each potential goal. In this paper, we propose an advanced and efficient real-time online goal recognition algorithm based on deep reinforcement learning in continuous domains. By leveraging the offline modeling of the observed agent's behavior with deep reinforcement learning, our algorithm achieves real-time goal recognition. We evaluate the algorithm's online goal recognition accuracy and stability in continuous simulation environments under communication constraints.