Department of Biostatistics, Hacettepe University Faculty of Medicine, Sıhhiye, 06230, Ankara, Türkiye.
BMC Bioinformatics. 2023 Oct 30;24(1):407. doi: 10.1186/s12859-023-05540-5.
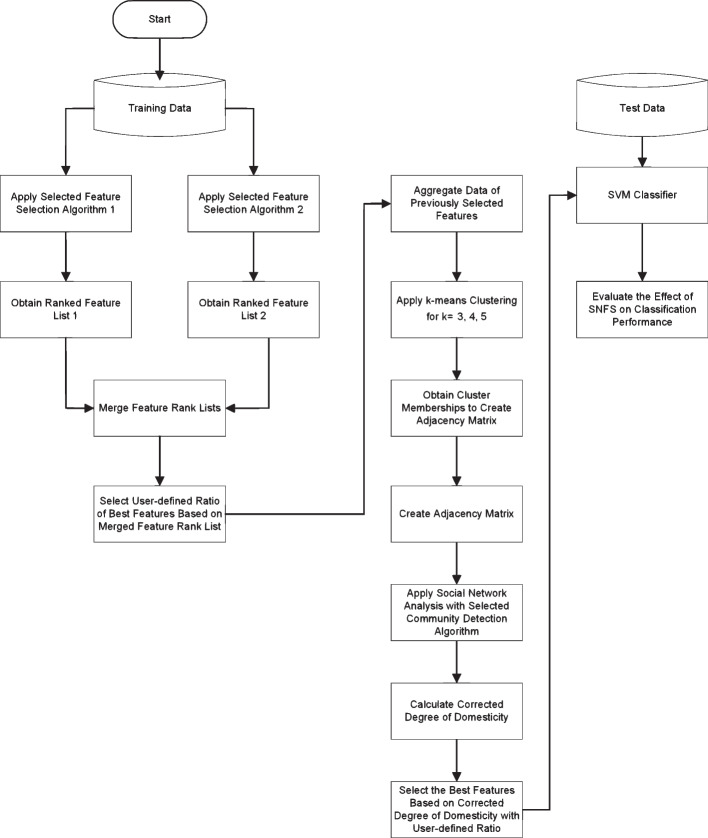
Dimension reduction, especially feature selection, is an important step in improving classification performance for high-dimensional data. Particularly in cancer research, when reducing the number of features, i.e., genes, it is important to select the most informative features/potential biomarkers that could affect the diagnostic accuracy. Therefore, researchers continuously try to explore more efficient ways to reduce the large number of features/genes to a small but informative subset before the classification task. Hybrid methods have been extensively investigated for this purpose, and research to find the optimal approach is ongoing. Social network analysis is used as a part of a hybrid method, although there are several issues that have arisen when using social network tools, such as using a single environment for computing, constructing an adjacency matrix or computing network measures. Therefore, in our study, we apply a hybrid feature selection method consisting of several machine learning algorithms in addition to social network analysis with our proposed network metric, called the corrected degree of domesticity, in a single environment, R, to improve the support vector machine classifier's performance. In addition, we evaluate and compare the performances of several combinations used in the different steps of the method with a simulation experiment.
The proposed method improves the classifier's performance compared to using the whole feature set in all the cases we investigate. Additionally, in terms of the area under the receiver operating characteristic (ROC) curve, our approach improves classification performance compared to several approaches in the literature.
When using the corrected degree of domesticity as a network degree centrality measure, it is important to use our correction to compare nodes/features with no connection outside of their community since it provides a more accurate ranking among the features. Due to the nature of the hybrid method, which includes social network analysis, it is necessary to investigate possible combinations to provide an optimal solution for the microarray data used in the research.
降维,尤其是特征选择,是提高高维数据分类性能的重要步骤。特别是在癌症研究中,当减少特征数量,即基因数量时,选择最有信息量的特征/潜在生物标志物以影响诊断准确性是很重要的。因此,研究人员不断尝试探索更有效的方法,以便在分类任务之前,将大量的特征/基因减少到一个小但信息量丰富的子集。为此目的,已经广泛研究了混合方法,并且正在寻找最佳方法的研究仍在进行中。社会网络分析被用作混合方法的一部分,尽管在使用社会网络工具时出现了几个问题,例如在单个环境中计算、构建邻接矩阵或计算网络度量值。因此,在我们的研究中,我们应用了一种混合特征选择方法,该方法由除了社会网络分析之外的几种机器学习算法组成,并且在单个环境 R 中,使用我们提出的网络度量标准,即校正的内婚度,来改进支持向量机分类器的性能。此外,我们使用模拟实验评估并比较了方法的不同步骤中使用的几种组合的性能。
与使用整个特征集的情况相比,所提出的方法提高了分类器的性能。此外,就接收器操作特性(ROC)曲线下的面积而言,与文献中的几种方法相比,我们的方法提高了分类性能。
当将校正的内婚度用作网络度中心性度量标准时,使用我们的校正标准来比较节点/特征与社区之外没有连接的节点/特征是很重要的,因为它在特征之间提供了更准确的排名。由于混合方法的性质,其中包括社会网络分析,因此有必要研究可能的组合,以为研究中使用的微阵列数据提供最佳解决方案。