Buoy Rina, Iwamura Masakazu, Srun Sovila, Kise Koichi
Department of Core Informatics, Graduate School of Informatics, Osaka Metropolitan University, Osaka 599-8531, Japan.
Department of Information Technology Engineering, Faculty of Engineering, Royal University of Phnom Penh, Phnom Penh 12156, Cambodia.
J Imaging. 2023 Nov 15;9(11):248. doi: 10.3390/jimaging9110248.
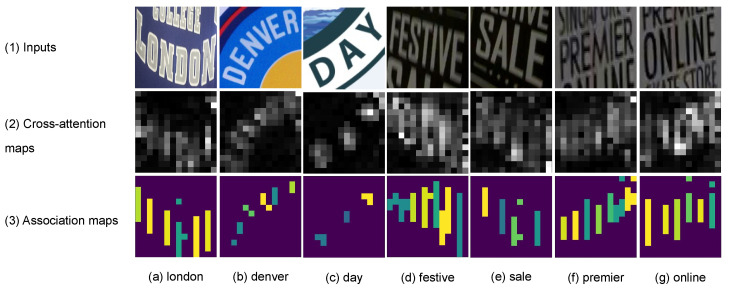
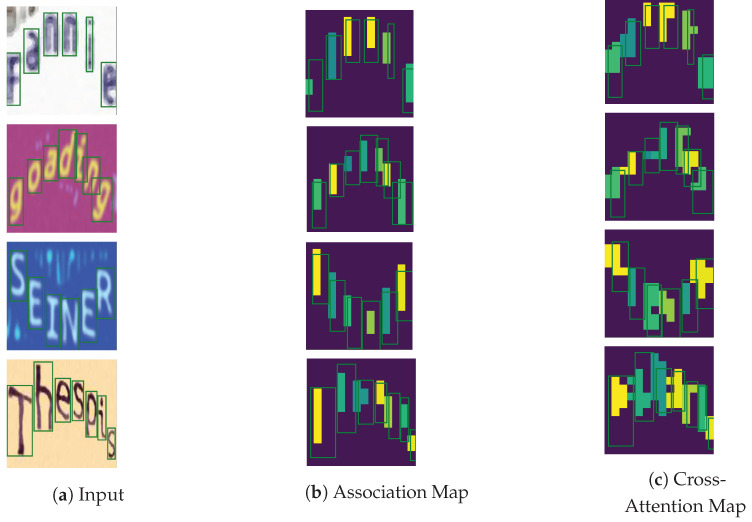
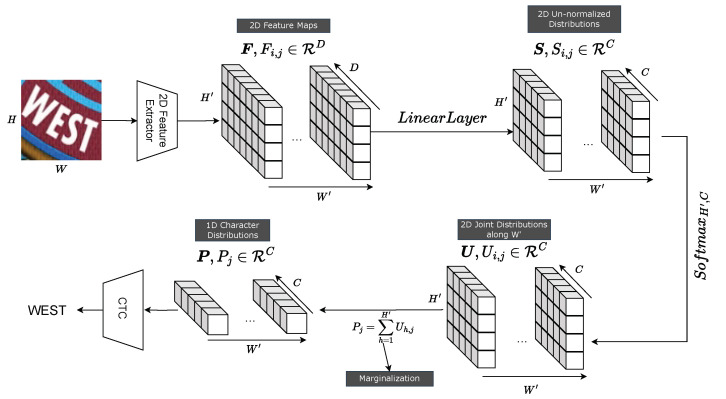
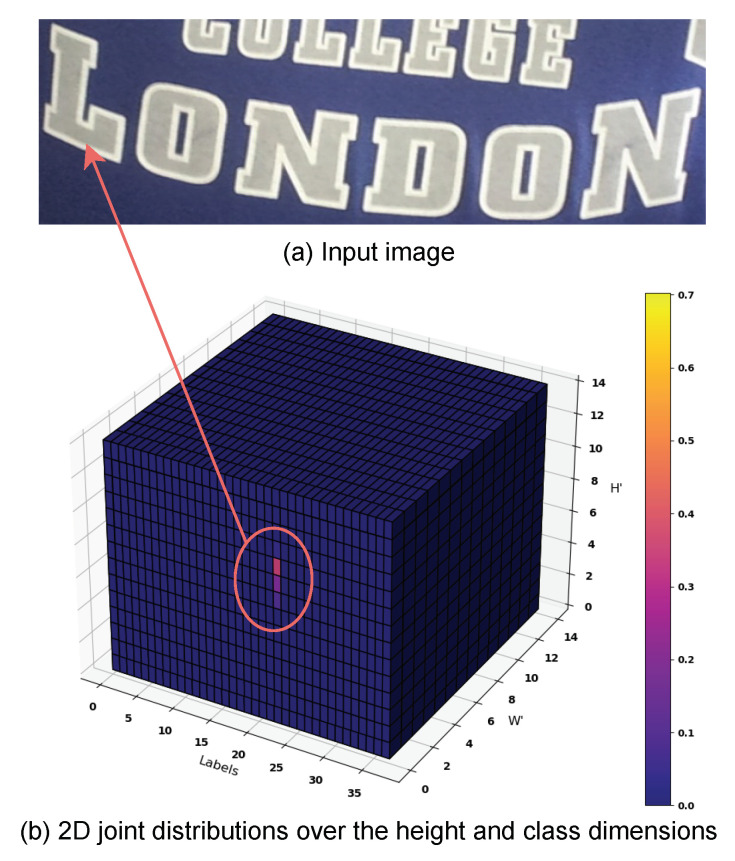
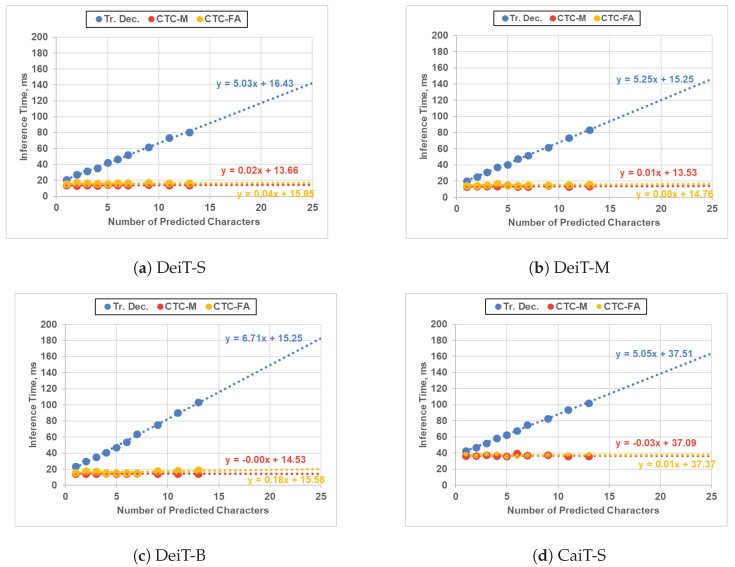
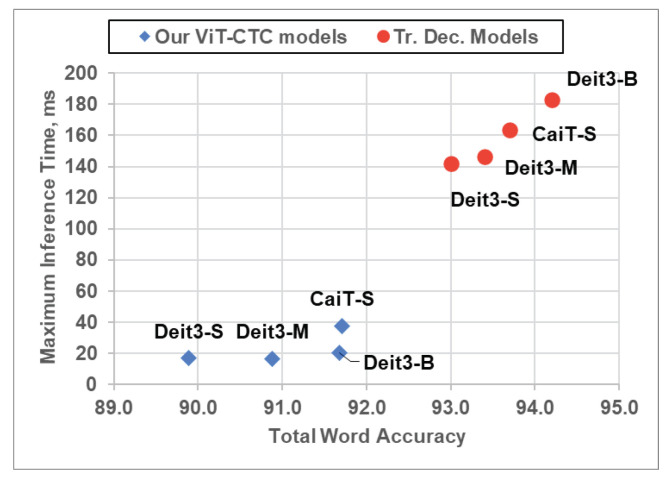
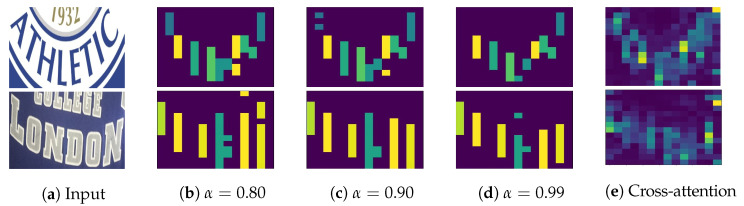
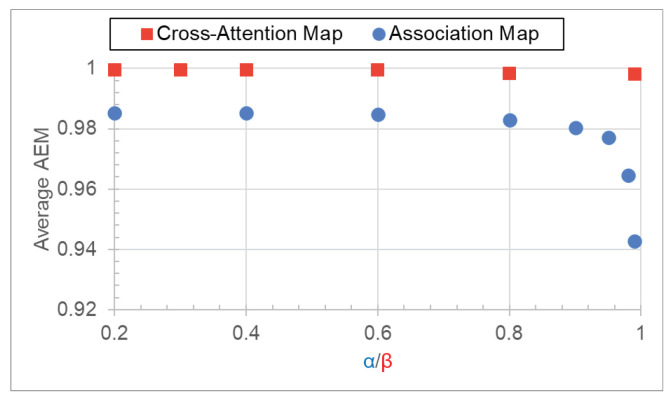
Connectionist temporal classification (CTC) is a favored decoder in scene text recognition (STR) for its simplicity and efficiency. However, most CTC-based methods utilize one-dimensional (1D) vector sequences, usually derived from a recurrent neural network (RNN) encoder. This results in the absence of explainable 2D spatial relationship between the predicted characters and corresponding image regions, essential for model explainability. On the other hand, 2D attention-based methods enhance recognition accuracy and offer character location information via cross-attention mechanisms, linking predictions to image regions. However, these methods are more computationally intensive, compared with the 1D CTC-based methods. To achieve both low latency and model explainability via character localization using a 1D CTC decoder, we propose a marginalization-based method that processes 2D feature maps and predicts a sequence of 2D joint probability distributions over the height and class dimensions. Based on the proposed method, we newly introduce an association map that aids in character localization and model prediction explanation. This map parallels the role of a cross-attention map, as seen in computationally-intensive attention-based architectures. With the proposed method, we consider a ViT-CTC STR architecture that uses a 1D CTC decoder and a pretrained vision Transformer (ViT) as a 2D feature extractor. Our ViT-CTC models were trained on synthetic data and fine-tuned on real labeled sets. These models outperform the recent state-of-the-art (SOTA) CTC-based methods on benchmarks in terms of recognition accuracy. Compared with the baseline Transformer-decoder-based models, our ViT-CTC models offer a speed boost up to 12 times regardless of the backbone, with a maximum 3.1% reduction in total word recognition accuracy. In addition, both qualitative and quantitative assessments of character locations estimated from the association map align closely with those from the cross-attention map and ground-truth character-level bounding boxes.
连接主义时间分类(CTC)因其简单性和效率,在场景文本识别(STR)中是一种受欢迎的解码器。然而,大多数基于CTC的方法使用一维(1D)向量序列,通常由循环神经网络(RNN)编码器导出。这导致预测字符与相应图像区域之间缺乏可解释的二维空间关系,而这对于模型的可解释性至关重要。另一方面,基于二维注意力的方法通过交叉注意力机制提高了识别准确率,并提供了字符定位信息,将预测与图像区域联系起来。然而,与基于一维CTC的方法相比,这些方法的计算量更大。为了通过使用一维CTC解码器进行字符定位来实现低延迟和模型可解释性,我们提出了一种基于边缘化的方法,该方法处理二维特征图,并预测高度和类别维度上的二维联合概率分布序列。基于所提出的方法,我们新引入了一个关联图,它有助于字符定位和模型预测解释。该图类似于计算量较大的基于注意力的架构中的交叉注意力图的作用。使用所提出的方法,我们考虑了一种ViT-CTC STR架构,该架构使用一维CTC解码器和预训练的视觉Transformer(ViT)作为二维特征提取器。我们的ViT-CTC模型在合成数据上进行训练,并在真实标记集上进行微调。在基准测试中,这些模型在识别准确率方面优于最近基于CTC的最新技术(SOTA)方法。与基于Transformer解码器的基线模型相比,我们的ViT-CTC模型无论主干如何,速度都能提高到12倍,总单词识别准确率最多降低3.1%。此外,从关联图估计的字符位置的定性和定量评估与从交叉注意力图和真实字符级边界框的评估密切一致。