Institute for Genomic Medicine, Nationwide Children's Hospital, Columbus, OH, USA.
Department of Pediatrics, The Ohio State University College of Medicine, Columbus, OH, USA.
Nat Genet. 2024 Feb;56(2):327-335. doi: 10.1038/s41588-023-01637-y. Epub 2024 Jan 10.
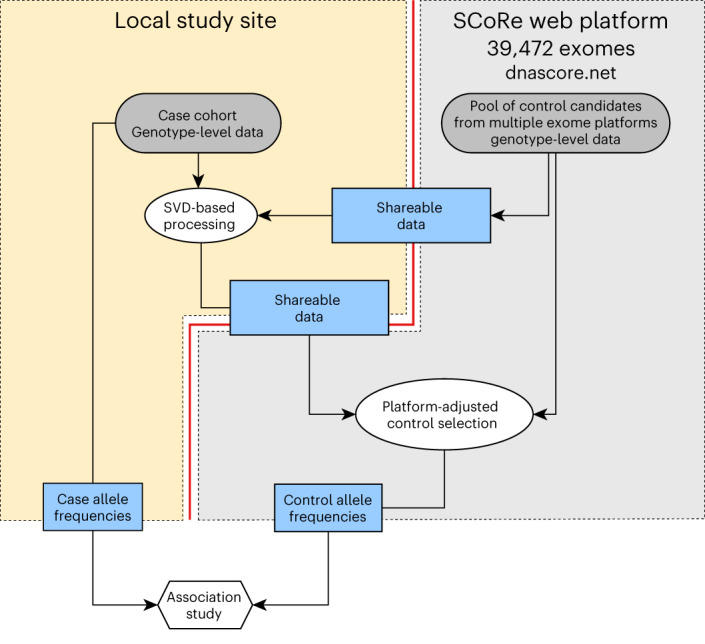
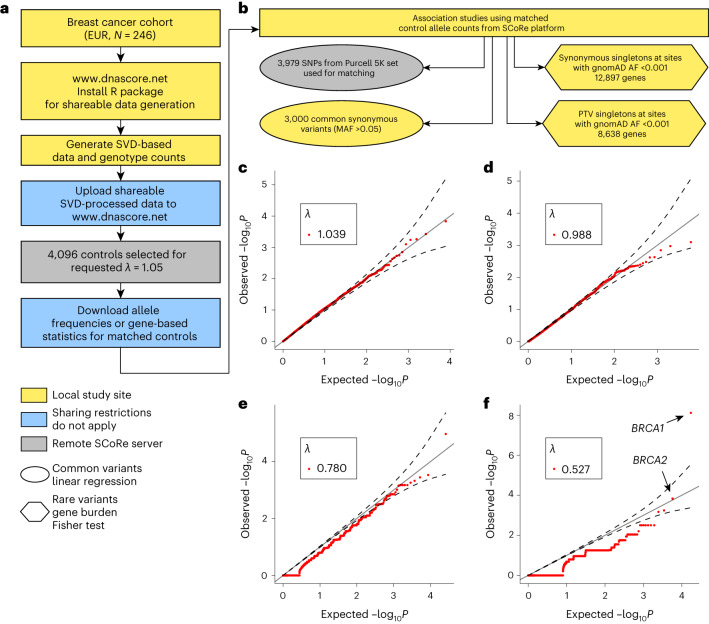
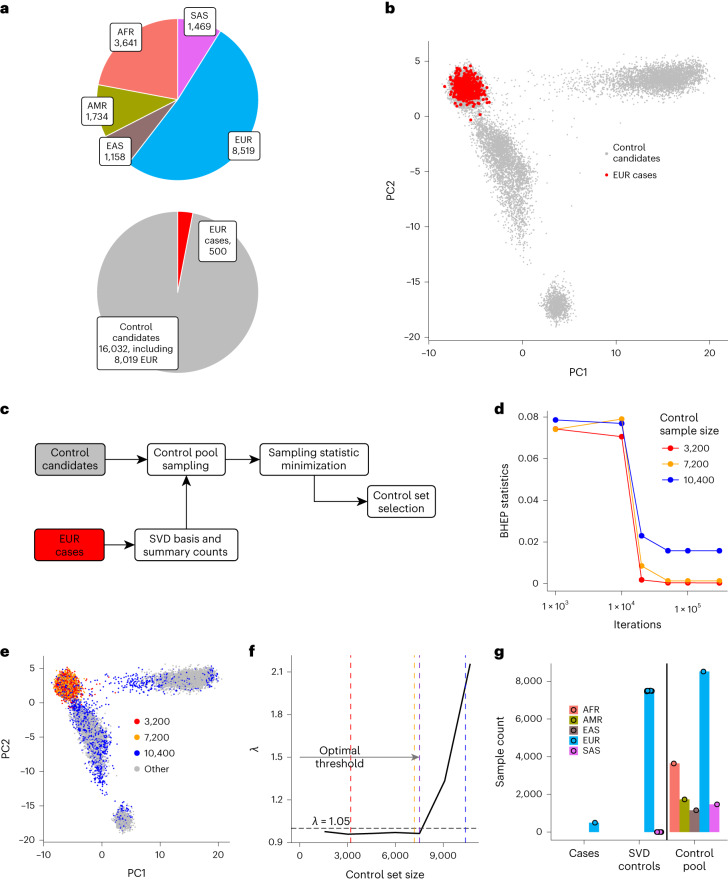
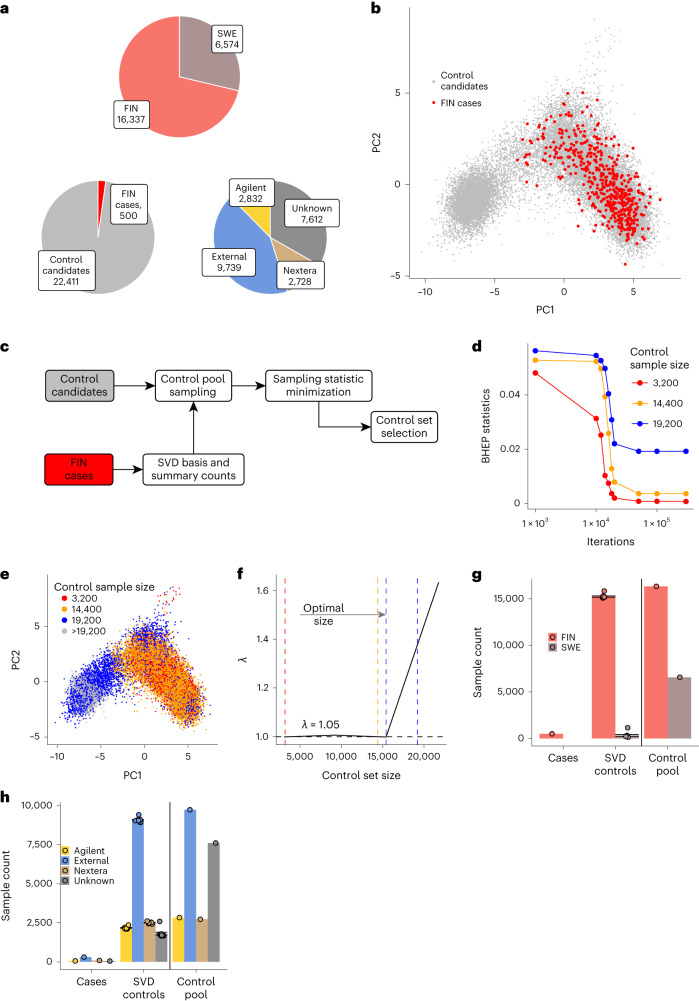
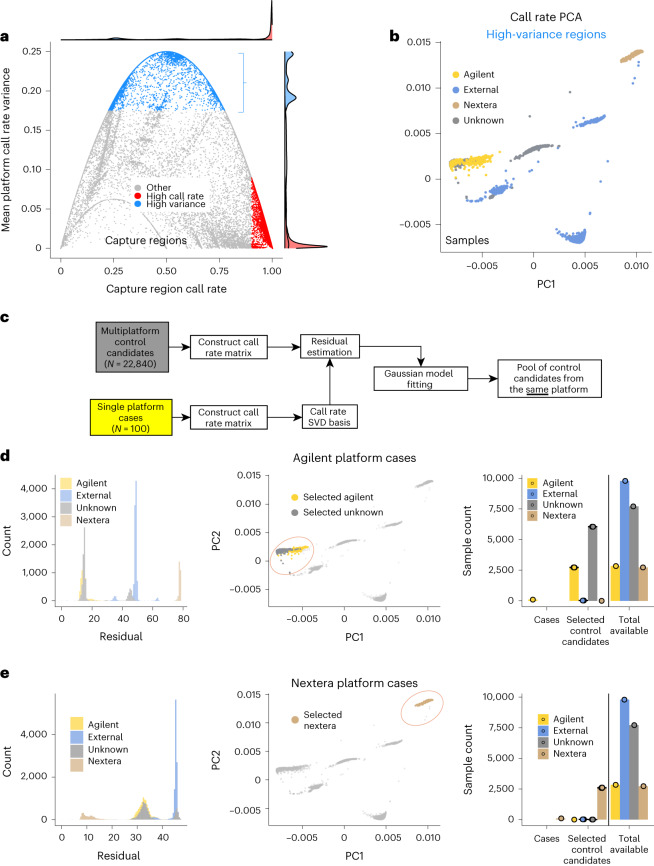
Acquiring a sufficiently powered cohort of control samples matched to a case sample can be time-consuming or, in some cases, impossible. Accordingly, an ability to leverage genetic data from control samples that were already collected elsewhere could dramatically improve power in genetic association studies. Sharing of control samples can pose significant challenges, since most human genetic data are subject to strict sharing regulations. Here, using the properties of singular value decomposition and subsampling algorithm, we developed a method allowing selection of the best-matching controls in an external pool of samples compliant with personal data protection and eliminating the need for genotype sharing. We provide access to a library of 39,472 exome sequencing controls at http://dnascore.net enabling association studies for case cohorts lacking control subjects. Using this approach, control sets can be selected from this online library with a prespecified matching accuracy, ensuring well-calibrated association analysis for both rare and common variants.
获得与病例样本相匹配的具有足够效力的对照样本队列可能既耗时,又在某些情况下无法实现。因此,利用已经在其他地方收集的对照样本的遗传数据的能力可以极大地提高遗传关联研究的效力。共享对照样本可能会带来重大挑战,因为大多数人类遗传数据都受到严格的共享法规的约束。在这里,我们使用奇异值分解和抽样算法的特性,开发了一种方法,允许在外层样本池中选择最佳匹配的对照,同时符合个人数据保护的要求,并消除了基因型共享的需要。我们在 http://dnascore.net 上提供了 39472 个外显子测序对照的库,以供缺乏对照的病例队列进行关联研究。使用这种方法,可以从这个在线库中选择具有预设匹配精度的对照集,确保对罕见和常见变体进行校准良好的关联分析。