Perea-Trigo Marina, Botella-López Celia, Martínez-Del-Amor Miguel Ángel, Álvarez-García Juan Antonio, Soria-Morillo Luis Miguel, Vegas-Olmos Juan José
Department of Languages and Computer Systems, Universidad de Sevilla, 41012 Sevilla, Spain.
Department of Computer Science and Artificial Intelligence, Universidad de Sevilla, 41012 Sevilla, Spain.
Sensors (Basel). 2024 Feb 24;24(5):1472. doi: 10.3390/s24051472.
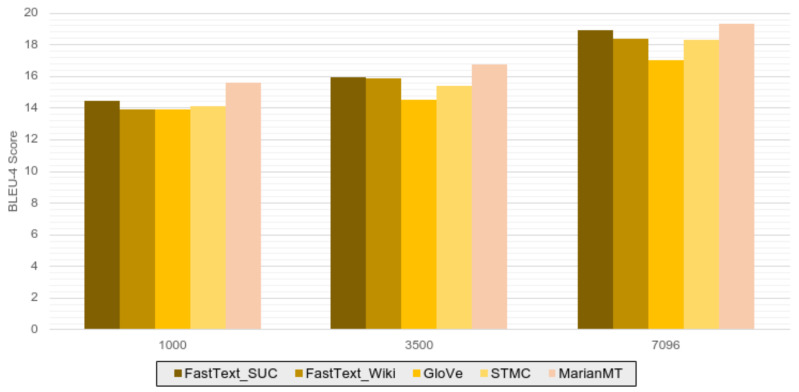
Sign language serves as the primary mode of communication for the deaf community. With technological advancements, it is crucial to develop systems capable of enhancing communication between deaf and hearing individuals. This paper reviews recent state-of-the-art methods in sign language recognition, translation, and production. Additionally, we introduce a rule-based system, called , for generating synthetic datasets in Spanish Sign Language. To check the usefulness of these datasets, we conduct experiments with two state-of-the-art models based on Transformers, MarianMT and Transformer-STMC. In general, we observe that the former achieves better results (+3.7 points in the BLEU-4 metric) although the latter is up to four times faster. Furthermore, the use of pre-trained word embeddings in Spanish enhances results. The rule-based system demonstrates superior performance and efficiency compared to Transformer models in Sign Language Production tasks. Lastly, we contribute to the state of the art by releasing the generated synthetic dataset in Spanish named .
手语是聋人社区的主要交流方式。随着技术进步,开发能够增强聋人和听力正常者之间交流的系统至关重要。本文回顾了手语识别、翻译和生成方面的最新先进方法。此外,我们介绍了一个名为 的基于规则的系统,用于生成西班牙手语的合成数据集。为检验这些数据集的实用性,我们使用了基于Transformer的两个先进模型MarianMT和Transformer-STMC进行实验。总体而言,我们观察到前者取得了更好的结果(在BLEU-4指标上提高了3.7分),尽管后者速度快达四倍。此外,在西班牙语中使用预训练词嵌入可提高结果。在手语生成任务中,基于规则的系统相比Transformer模型展现出卓越的性能和效率。最后,我们通过发布名为 的西班牙语合成数据集为该领域的发展做出了贡献。