Li Ziyi, Shen Yu, Ning Jing
Department of Biostatistics, The University of Texas MD Anderson Cancer Center, Houston, TX, USA.
J Am Stat Assoc. 2023;118(544):2276-2287. doi: 10.1080/01621459.2023.2210336. Epub 2023 Jun 26.
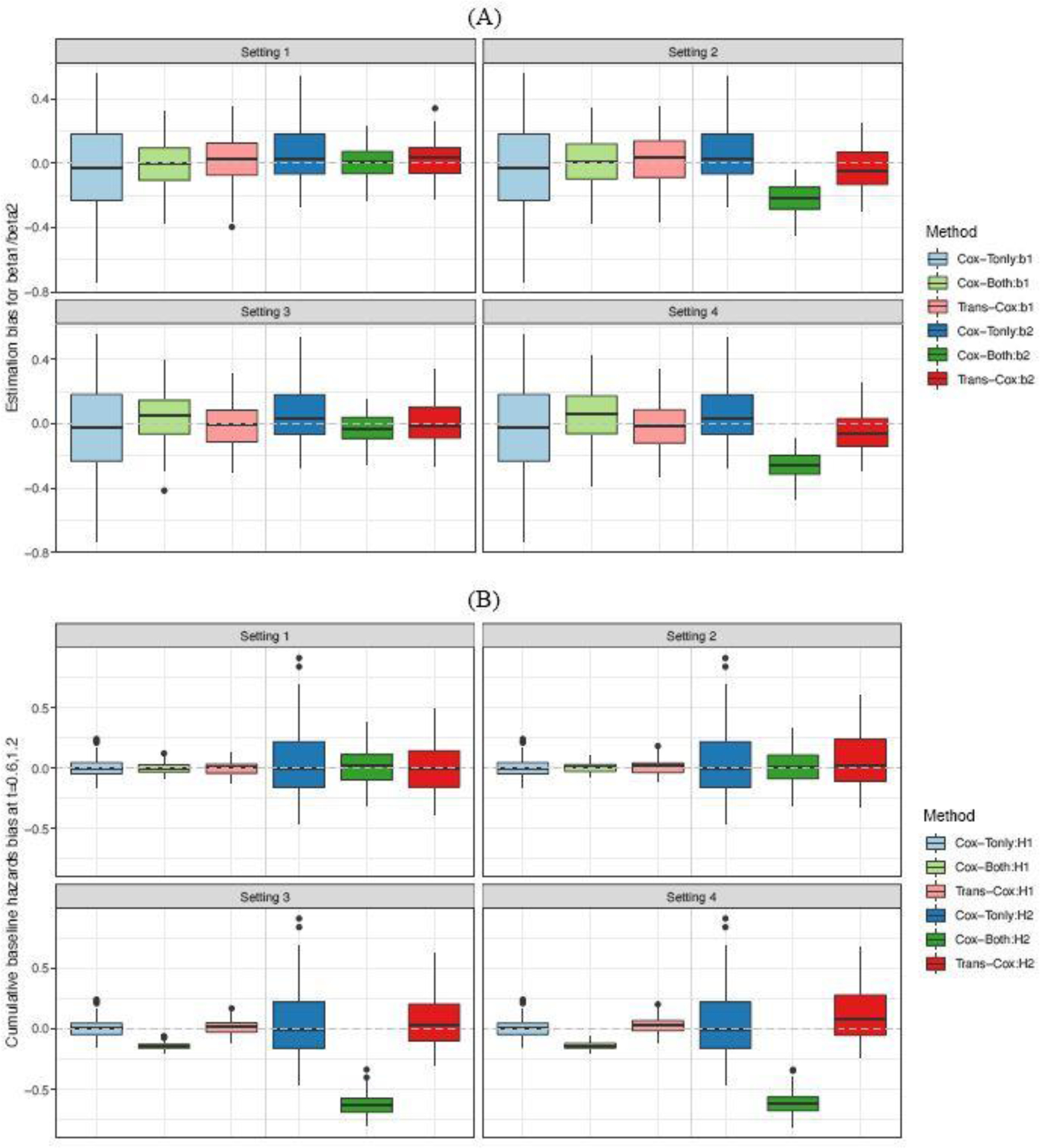
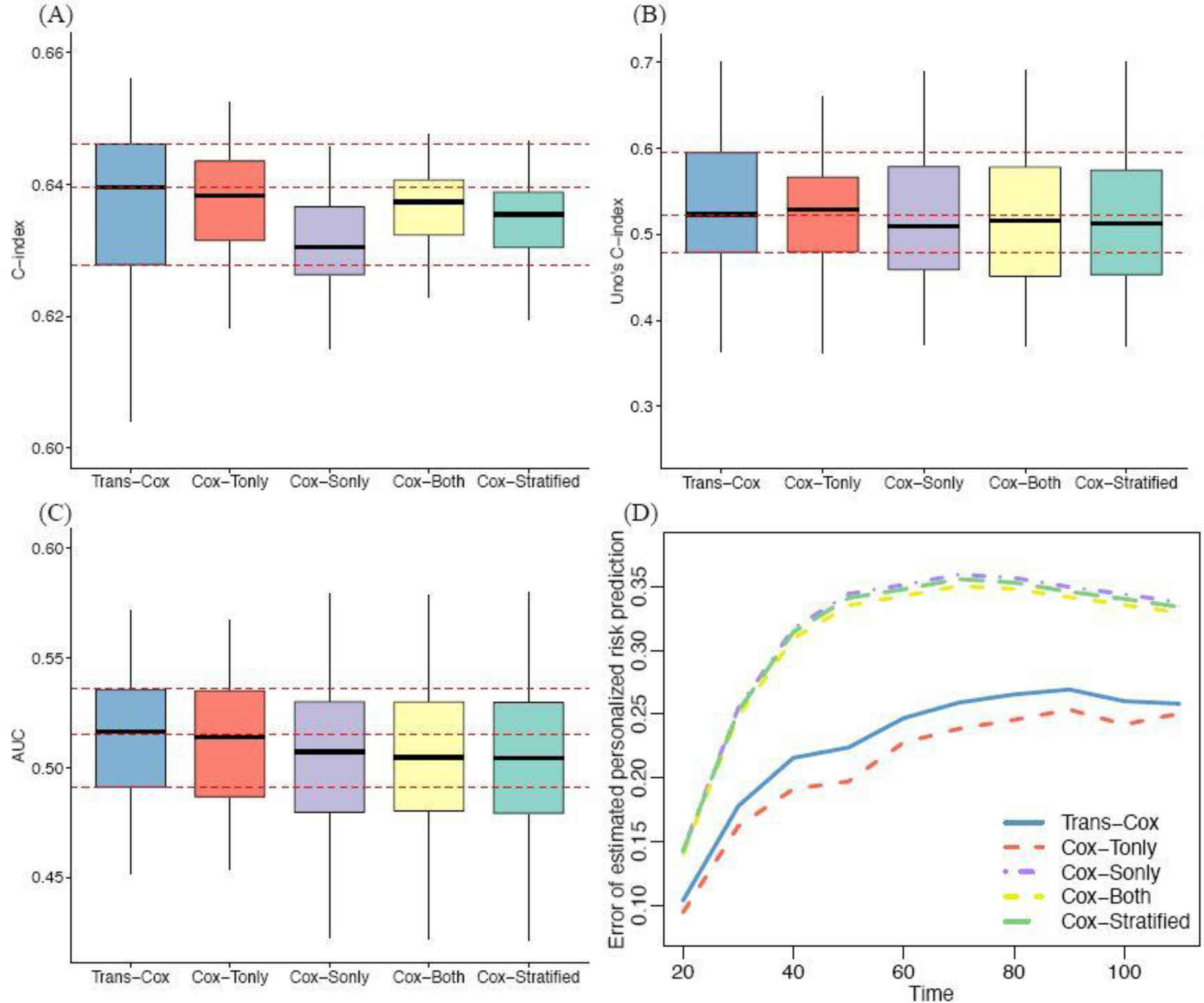
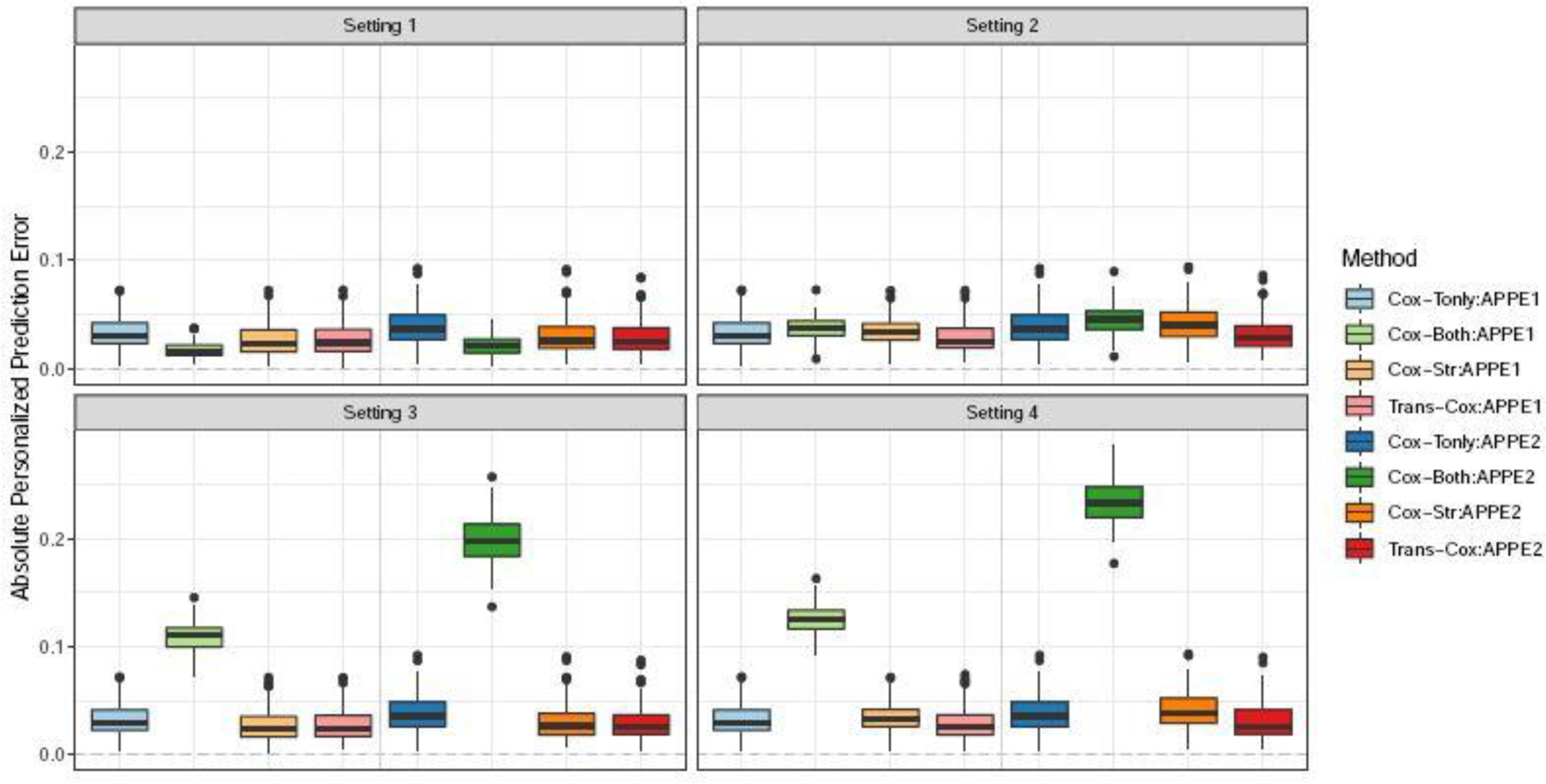
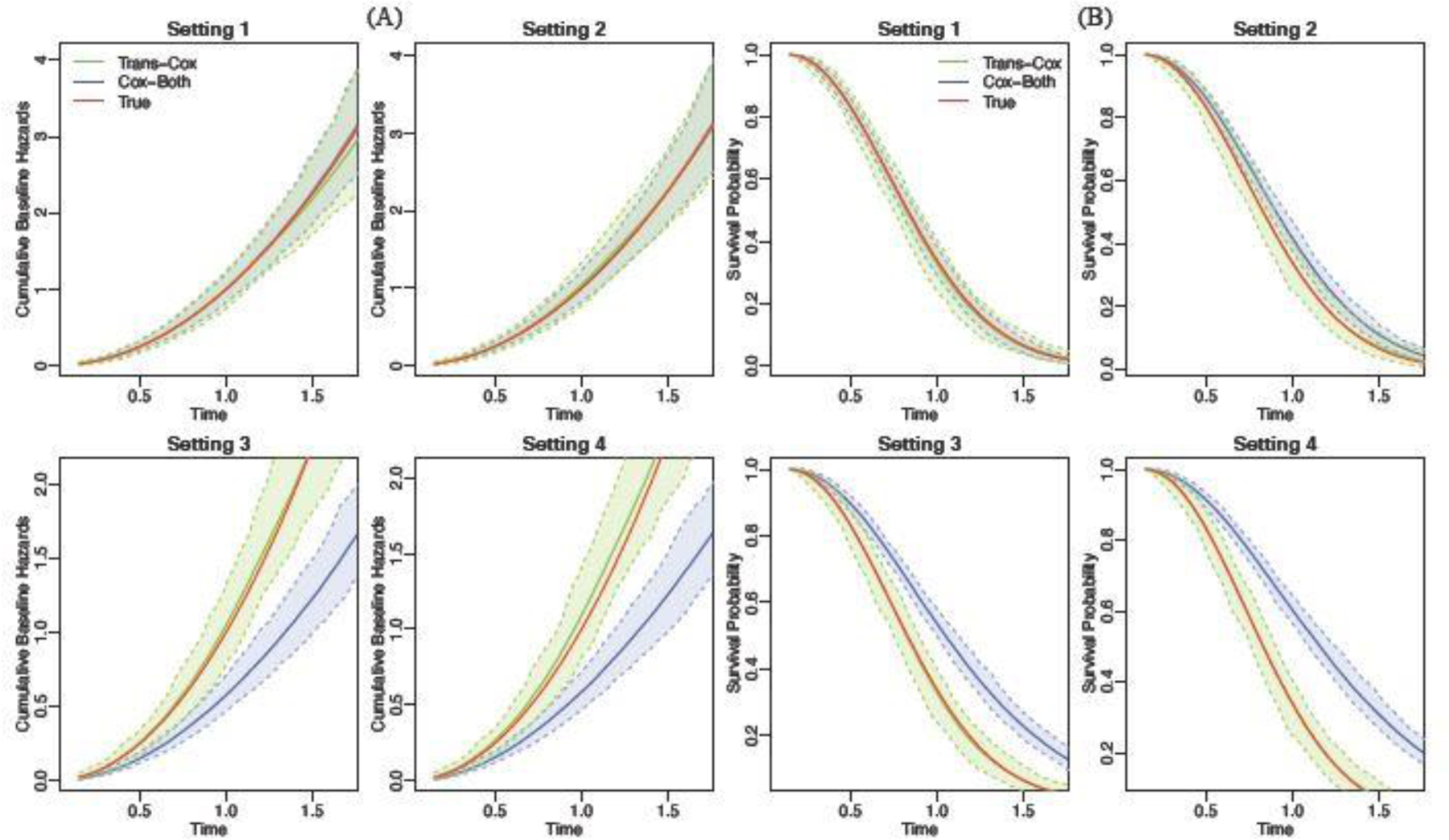
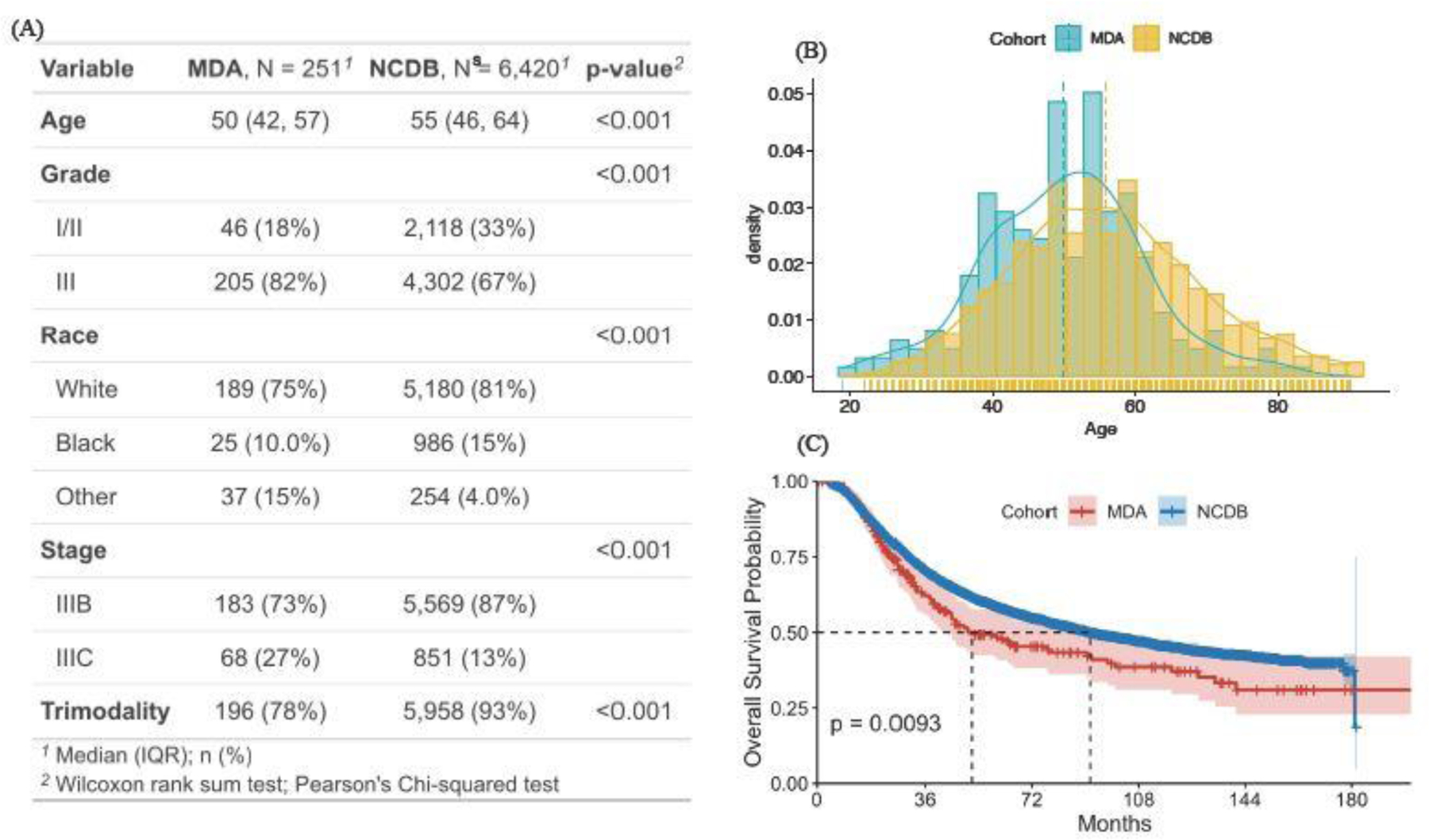
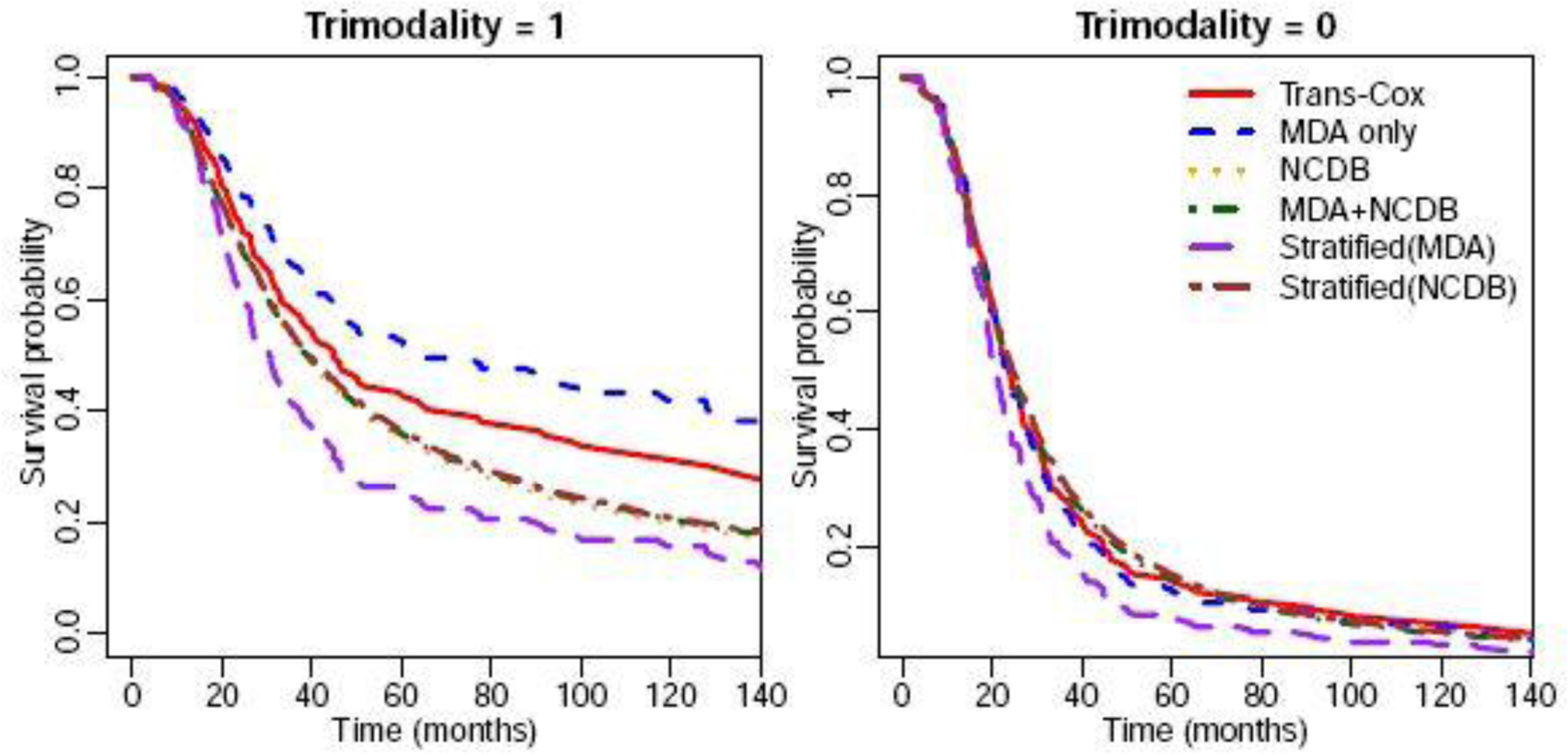
Transfer learning has attracted increasing attention in recent years for adaptively borrowing information across different data cohorts in various settings. Cancer registries have been widely used in clinical research because of their easy accessibility and large sample size. Our method is motivated by the question of how to utilize cancer registry data as a complement to improve the estimation precision of individual risks of death for inflammatory breast cancer (IBC) patients at The University of Texas MD Anderson Cancer Center. When transferring information for risk estimation based on the cancer registries (i.e., source cohort) to a single cancer center (i.e., target cohort), time-varying population heterogeneity needs to be appropriately acknowledged. However, there is no literature on how to adaptively transfer knowledge on risk estimation with time-to-event data from the source cohort to the target cohort while adjusting for time-varying differences in event risks between the two sources. Our goal is to address this statistical challenge by developing a transfer learning approach under the Cox proportional hazards model. To allow data-adaptive levels of information borrowing, we impose Lasso penalties on the discrepancies in regression coefficients and baseline hazard functions between the two cohorts, which are jointly solved in the proposed transfer learning algorithm. As shown in the extensive simulation studies, the proposed method yields more precise individualized risk estimation than using the target cohort alone. Meanwhile, our method demonstrates satisfactory robustness against cohort differences compared with the method that directly combines the target and source data in the Cox model. We develop a more accurate risk estimation model for the MD Anderson IBC cohort given various treatment and baseline covariates, while adaptively borrowing information from the National Cancer Database to improve risk assessment.
近年来,迁移学习因能在各种场景中跨不同数据群组自适应地借用信息而备受关注。癌症登记处因其易于获取且样本量大,已在临床研究中广泛使用。我们的方法是受这样一个问题驱动的:如何利用癌症登记数据作为补充,以提高德克萨斯大学MD安德森癌症中心炎性乳腺癌(IBC)患者个体死亡风险的估计精度。当基于癌症登记处(即源群组)将风险估计信息迁移到单个癌症中心(即目标群组)时,需要适当考虑随时间变化的人群异质性。然而,尚无关于如何在调整两个数据源之间事件风险的随时间变化差异的同时,将源群组中具有事件发生时间数据的风险估计知识自适应地迁移到目标群组的文献。我们的目标是通过在Cox比例风险模型下开发一种迁移学习方法来应对这一统计挑战。为了允许数据自适应的信息借用水平,我们对两个群组之间回归系数和基线风险函数的差异施加Lasso惩罚,这些惩罚在提出的迁移学习算法中联合求解。如广泛的模拟研究所示,所提出的方法比仅使用目标群组能产生更精确的个体风险估计。同时,与在Cox模型中直接组合目标和源数据的方法相比,我们的方法在面对群组差异时表现出令人满意的稳健性。我们针对MD安德森IBC群组,在考虑各种治疗和基线协变量的情况下,开发了一个更准确的风险估计模型,同时从国家癌症数据库自适应地借用信息以改进风险评估。