Qian Wenjia, Wang Xiaorui, Kang Yu, Pan Peichen, Hou Tingjun, Hsieh Chang-Yu
College of Pharmaceutical Sciences, Zhejiang University, Hangzhou, 310058, Zhejiang, China.
Dr. Neher's Biophysics Laboratory for Innovative Drug Discovery, State Key Laboratory of Quality Research in Chinese Medicine, Macau Institute for Applied Research in Medicine and Health, Macau University of Science and Technology, Macao, 999078, China.
J Cheminform. 2024 Mar 31;16(1):38. doi: 10.1186/s13321-024-00827-y.
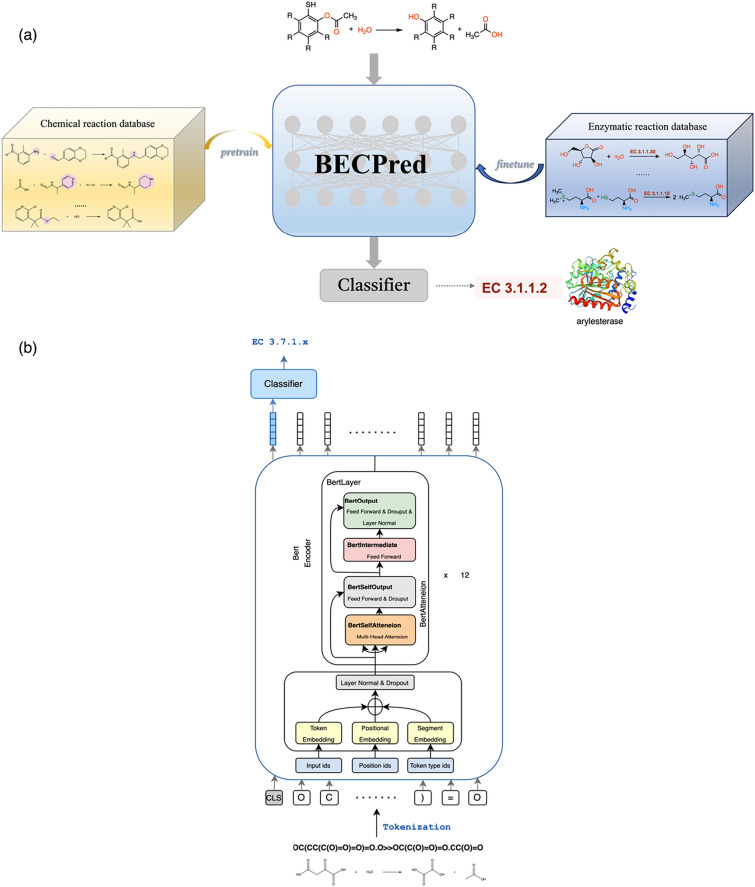
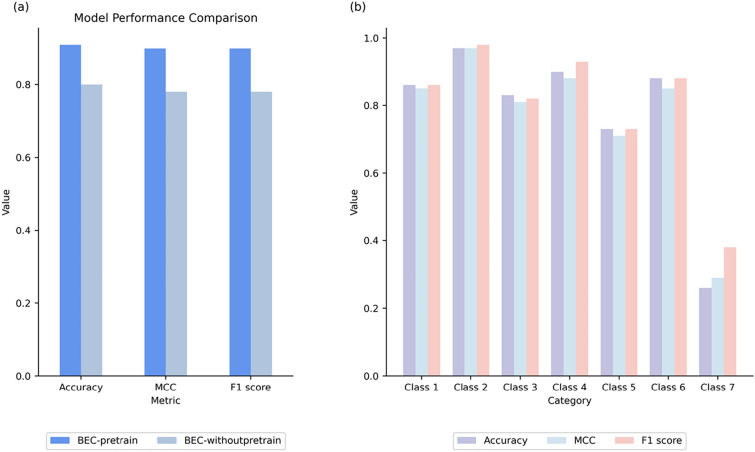
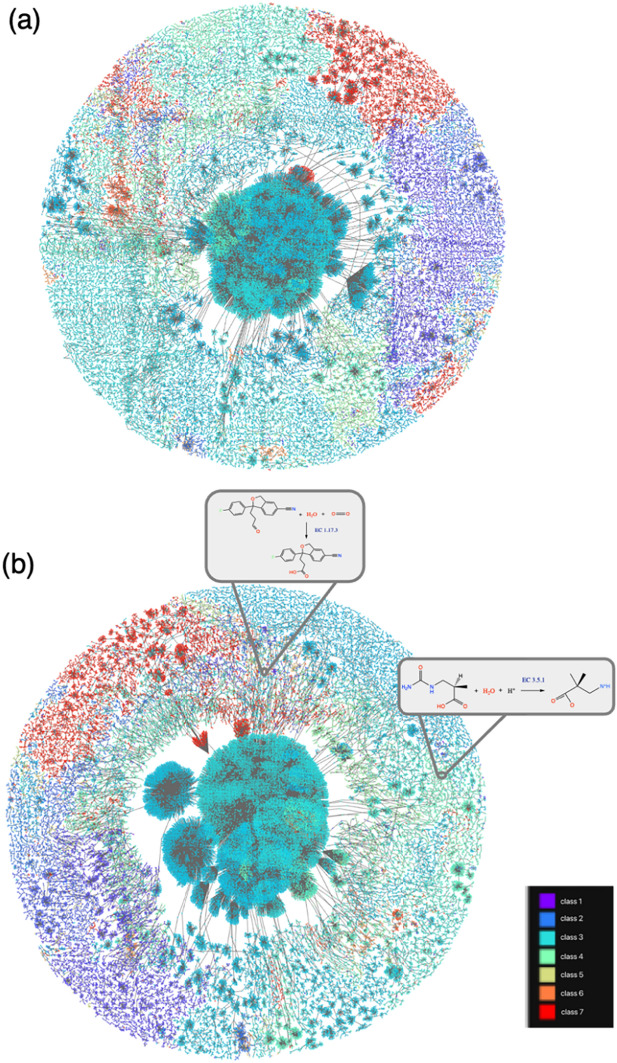
Accurate prediction of the enzyme comission (EC) numbers for chemical reactions is essential for the understanding and manipulation of enzyme functions, biocatalytic processes and biosynthetic planning. A number of machine leanring (ML)-based models have been developed to classify enzymatic reactions, showing great advantages over costly and long-winded experimental verifications. However, the prediction accuracy for most available models trained on the records of chemical reactions without specifying the enzymatic catalysts is rather limited. In this study, we introduced BEC-Pred, a BERT-based multiclassification model, for predicting EC numbers associated with reactions. Leveraging transfer learning, our approach achieves precise forecasting across a wide variety of Enzyme Commission (EC) numbers solely through analysis of the SMILES sequences of substrates and products. BEC-Pred model outperformed other sequence and graph-based ML methods, attaining a higher accuracy of 91.6%, surpassing them by 5.5%, and exhibiting superior F1 scores with improvements of 6.6% and 6.0%, respectively. The enhanced performance highlights the potential of BEC-Pred to serve as a reliable foundational tool to accelerate the cutting-edge research in synthetic biology and drug metabolism. Moreover, we discussed a few examples on how BEC-Pred could accurately predict the enzymatic classification for the Novozym 435-induced hydrolysis and lipase efficient catalytic synthesis. We anticipate that BEC-Pred will have a positive impact on the progression of enzymatic research.
准确预测化学反应的酶委员会(EC)编号对于理解和操控酶的功能、生物催化过程及生物合成规划至关重要。已经开发了许多基于机器学习(ML)的模型来对酶促反应进行分类,相较于成本高昂且冗长的实验验证展现出了巨大优势。然而,大多数基于未指定酶催化剂的化学反应记录训练的现有模型的预测准确性相当有限。在本研究中,我们引入了BEC-Pred,一种基于BERT的多分类模型,用于预测与反应相关的EC编号。利用迁移学习,我们的方法仅通过分析底物和产物的SMILES序列就能在各种酶委员会(EC)编号上实现精确预测。BEC-Pred模型优于其他基于序列和图的ML方法,达到了91.6%的更高准确率,比它们高出5.5%,并且分别在F1分数上有6.6%和6.0%的提升,展现出卓越性能。性能的提升凸显了BEC-Pred作为可靠基础工具加速合成生物学和药物代谢前沿研究的潜力。此外,我们讨论了一些关于BEC-Pred如何能够准确预测诺维信435诱导的水解和脂肪酶高效催化合成的酶分类的例子。我们预计BEC-Pred将对酶学研究的进展产生积极影响。