University Institute of Computing, Chandigarh University, NH-05-Chandigarh-Ludhiana, Mohali, Punjab, India.
Department of Computer Science, University of Kashmir, South Campus, Anantnag, Jammu and Kashmir, India.
BMC Bioinformatics. 2024 Apr 16;25(1):152. doi: 10.1186/s12859-024-05712-x.
Text summarization is a challenging problem in Natural Language Processing, which involves condensing the content of textual documents without losing their overall meaning and information content, In the domain of bio-medical research, summaries are critical for efficient data analysis and information retrieval. While several bio-medical text summarizers exist in the literature, they often miss out on an essential text aspect: text semantics.
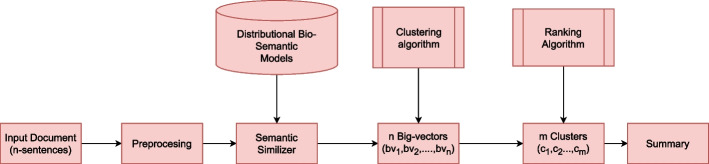
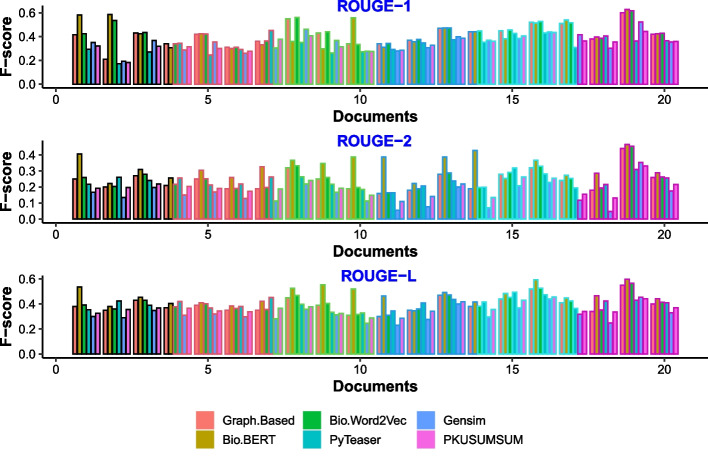
This paper proposes a novel extractive summarizer that preserves text semantics by utilizing bio-semantic models. We evaluate our approach using ROUGE on a standard dataset and compare it with three state-of-the-art summarizers. Our results show that our approach outperforms existing summarizers.
The usage of semantics can improve summarizer performance and lead to better summaries. Our summarizer has the potential to aid in efficient data analysis and information retrieval in the field of biomedical research.
文本摘要是自然语言处理中的一个具有挑战性的问题,它涉及到在不丢失整体意义和信息内容的情况下对文本文档的内容进行压缩。在生物医学研究领域,摘要对于高效数据分析和信息检索至关重要。虽然文献中存在几种生物医学文本摘要器,但它们往往忽略了文本的一个重要方面:文本语义。
本文提出了一种新颖的提取式摘要器,通过利用生物语义模型来保留文本语义。我们使用 ROUGE 在标准数据集上评估我们的方法,并将其与三种最先进的摘要器进行比较。我们的结果表明,我们的方法优于现有的摘要器。
语义的使用可以提高摘要器的性能,并生成更好的摘要。我们的摘要器有可能帮助生物医学研究领域进行高效数据分析和信息检索。