Lavan Nadine, McGettigan Carolyn
Department of Experimental and Biological Psychology, Queen Mary University of London, London, UK.
Department of Speech, Hearing, and Phonetic Sciences, University College London, London, UK.
Commun Psychol. 2023;1(1):1. doi: 10.1038/s44271-023-00001-4. Epub 2023 Jul 25.
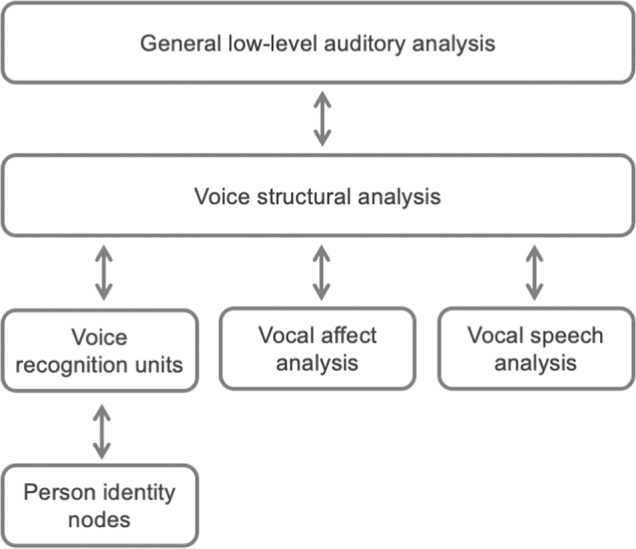
When hearing a voice, listeners can form a detailed impression of the person behind the voice. Existing models of voice processing focus primarily on one aspect of person perception - identity recognition from familiar voices - but do not account for the perception of other person characteristics (e.g., sex, age, personality traits). Here, we present a broader perspective, proposing that listeners have a common perceptual goal of perceiving who they are hearing, whether the voice is familiar or unfamiliar. We outline and discuss a model - the Person Perception from Voices (PPV) model - that achieves this goal via a common mechanism of recognising a familiar person, persona, or set of speaker characteristics. Our PPV model aims to provide a more comprehensive account of how listeners perceive the person they are listening to, using an approach that incorporates and builds on aspects of the hierarchical frameworks and prototype-based mechanisms proposed within existing models of voice identity recognition.
当听到一个声音时,听众可以对声音背后的人形成详细的印象。现有的语音处理模型主要关注人物感知的一个方面——从熟悉的声音中识别身份——但没有考虑对其他人的特征(如性别、年龄、性格特征)的感知。在这里,我们提出一个更广泛的观点,即听众有一个共同的感知目标,即感知他们正在听谁的声音,无论这个声音是熟悉还是陌生。我们概述并讨论了一个模型——语音人物感知(PPV)模型——该模型通过识别熟悉的人、角色或说话者特征集的共同机制来实现这一目标。我们的PPV模型旨在通过一种整合并基于现有语音身份识别模型中提出的层次框架和基于原型的机制的方法,更全面地解释听众如何感知他们正在聆听的人。