RMIT University, Melbourne, Australia.
La Trobe University, Melbourne, Australia.
Behav Res Methods. 2024 Oct;56(7):7674-7690. doi: 10.3758/s13428-024-02443-y. Epub 2024 Jun 4.
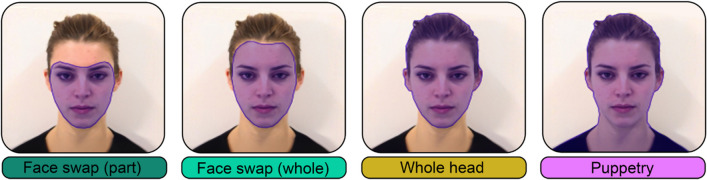
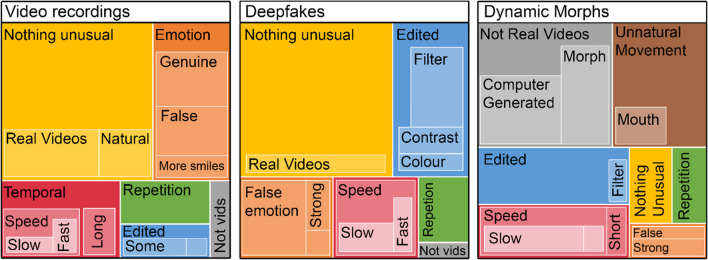
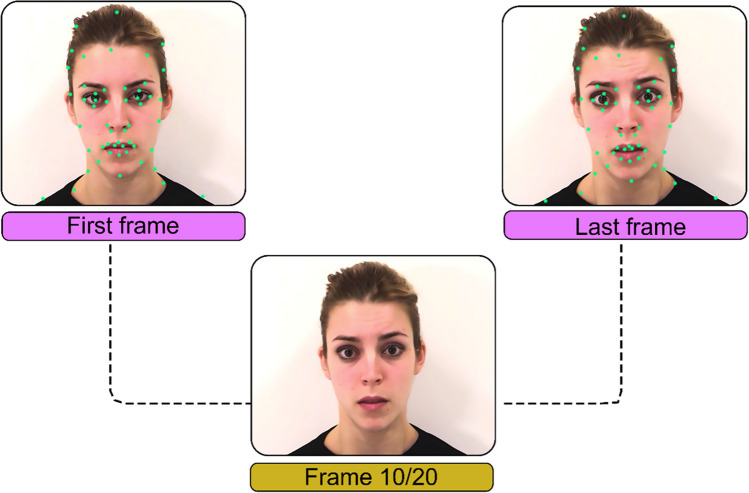
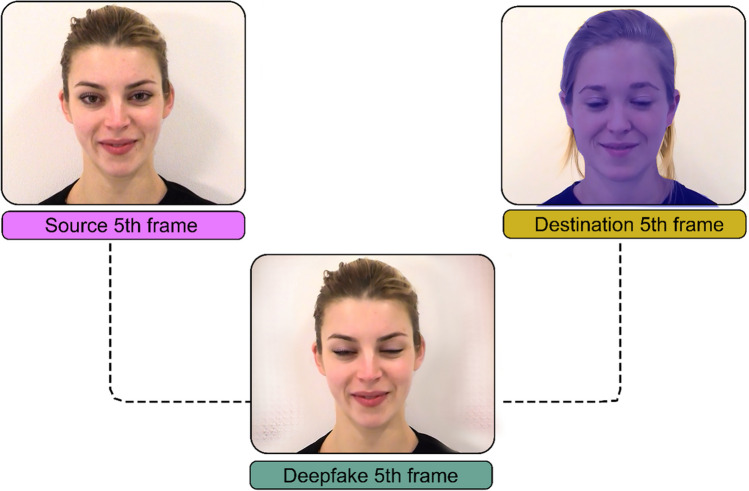
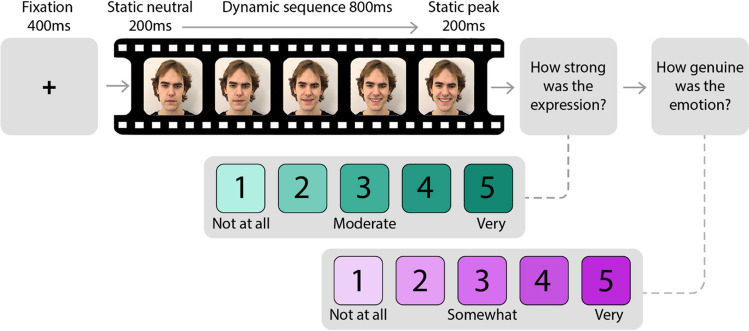
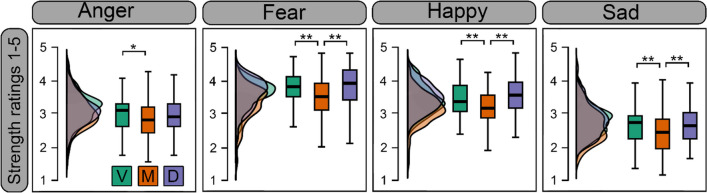
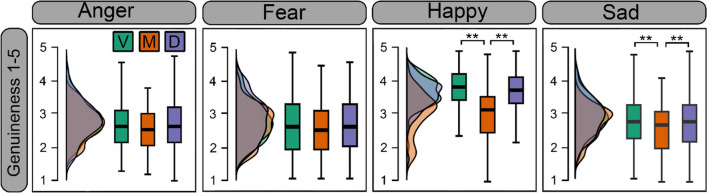
Video recordings accurately capture facial expression movements; however, they are difficult for face perception researchers to standardise and manipulate. For this reason, dynamic morphs of photographs are often used, despite their lack of naturalistic facial motion. This study aimed to investigate how humans perceive emotions from faces using real videos and two different approaches to artificially generating dynamic expressions - dynamic morphs, and AI-synthesised deepfakes. Our participants perceived dynamic morphed expressions as less intense when compared with videos (all emotions) and deepfakes (fearful, happy, sad). Videos and deepfakes were perceived similarly. Additionally, they perceived morphed happiness and sadness, but not morphed anger or fear, as less genuine than other formats. Our findings support previous research indicating that social responses to morphed emotions are not representative of those to video recordings. The findings also suggest that deepfakes may offer a more suitable standardized stimulus type compared to morphs. Additionally, qualitative data were collected from participants and analysed using ChatGPT, a large language model. ChatGPT successfully identified themes in the data consistent with those identified by an independent human researcher. According to this analysis, our participants perceived dynamic morphs as less natural compared with videos and deepfakes. That participants perceived deepfakes and videos similarly suggests that deepfakes effectively replicate natural facial movements, making them a promising alternative for face perception research. The study contributes to the growing body of research exploring the usefulness of generative artificial intelligence for advancing the study of human perception.
视频记录可以准确捕捉面部表情动作;然而,对于面部感知研究人员来说,它们很难标准化和操作。出于这个原因,尽管动态照片缺乏自然的面部运动,但通常会使用动态变形来代替。本研究旨在探讨人类如何通过真实视频以及两种不同的方法来感知人工生成的动态表情——动态变形和 AI 合成的深度伪造——来感知面部表情。与视频(所有情绪)和深度伪造(恐惧、快乐、悲伤)相比,参与者认为动态变形的表情不那么强烈。视频和深度伪造的感知效果相似。此外,他们认为变形的快乐和悲伤,而不是变形的愤怒或恐惧,不如其他格式真实。我们的发现支持了先前的研究,表明对变形情绪的社会反应并不代表对视频记录的反应。研究结果还表明,与变形相比,深度伪造可能提供更适合标准化的刺激类型。此外,还从参与者那里收集了定性数据,并使用大型语言模型 ChatGPT 进行了分析。ChatGPT 成功地从数据中识别出与独立人类研究人员识别出的主题一致的主题。根据该分析,参与者认为动态变形与视频和深度伪造相比不那么自然。参与者对深度伪造和视频的感知相似,这表明深度伪造有效地复制了自然的面部运动,使其成为面部感知研究的一种有前途的替代方法。这项研究为探索生成式人工智能在促进人类感知研究方面的有用性的不断增长的研究做出了贡献。