Department of Computer Science, Lakehead University, Thunder Bay, Ontario, Canada.
Department of Social Work, Lakehead University, Thunder Bay, Ontario, Canada.
PLoS One. 2024 Aug 15;19(8):e0307741. doi: 10.1371/journal.pone.0307741. eCollection 2024.
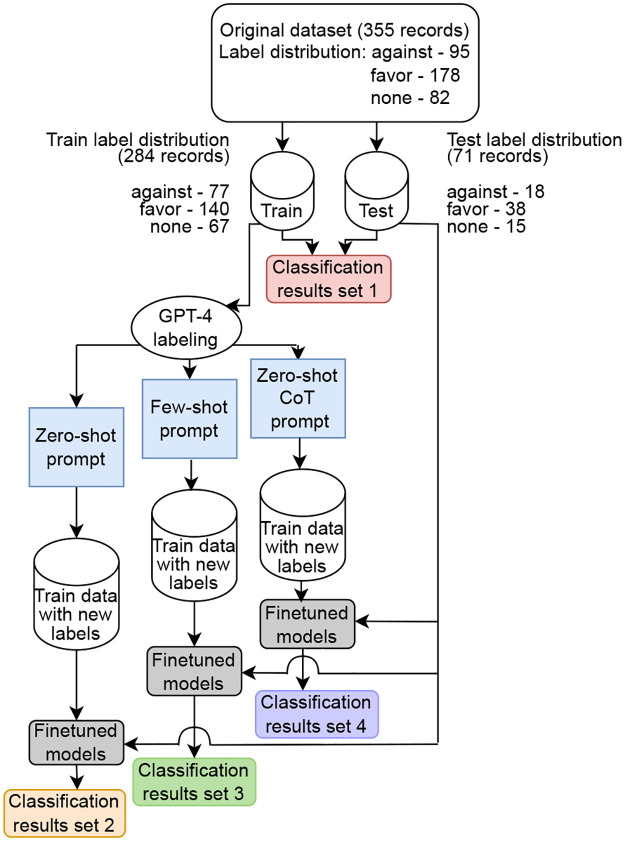
Data annotation in NLP is a costly and time-consuming task, traditionally handled by human experts who require extensive training to enhance the task-related background knowledge. Besides, labeling social media texts is particularly challenging due to their brevity, informality, creativity, and varying human perceptions regarding the sociocultural context of the world. With the emergence of GPT models and their proficiency in various NLP tasks, this study aims to establish a performance baseline for GPT-4 as a social media text annotator. To achieve this, we employ our own dataset of tweets, expertly labeled for stance detection with full inter-rater agreement among three annotators. We experiment with three techniques: Zero-shot, Few-shot, and Zero-shot with Chain-of-Thoughts to create prompts for the labeling task. We utilize four training sets constructed with different label sets, including human labels, to fine-tune transformer-based large language models and various combinations of traditional machine learning models with embeddings for stance classification. Finally, all fine-tuned models undergo evaluation using a common testing set with human-generated labels. We use the results from models trained on human labels as the benchmark to assess GPT-4's potential as an annotator across the three prompting techniques. Based on the experimental findings, GPT-4 achieves comparable results through the Few-shot and Zero-shot Chain-of-Thoughts prompting methods. However, none of these labeling techniques surpass the top three models fine-tuned on human labels. Moreover, we introduce the Zero-shot Chain-of-Thoughts as an effective strategy for aspect-based social media text labeling, which performs better than the standard Zero-shot and yields results similar to the high-performing yet expensive Few-shot approach.
自然语言处理中的数据标注是一项昂贵且耗时的任务,传统上由需要广泛培训以增强与任务相关的背景知识的人类专家来完成。此外,由于社交媒体文本的简洁性、非正式性、创造性以及人们对世界社会文化背景的不同看法,对其进行标注特别具有挑战性。随着 GPT 模型的出现及其在各种 NLP 任务中的熟练程度,本研究旨在为 GPT-4 作为社交媒体文本标注器建立性能基准。为了实现这一目标,我们使用了自己的推文数据集,这些推文经过专业标注,用于立场检测,三位标注员之间具有完全的评分者间一致性。我们尝试了三种技术:零样本、少样本和零样本与思维链提示,为标注任务创建提示。我们使用了四个不同标签集构建的训练集,包括人类标签,对基于转换器的大型语言模型进行微调,并对各种带有嵌入的传统机器学习模型进行微调,以进行立场分类。最后,所有经过微调的模型都使用带有人类生成标签的公共测试集进行评估。我们使用基于人类标签训练的模型的结果作为基准,评估 GPT-4 在三种提示技术中的标注能力。根据实验结果,GPT-4 通过少样本和零样本思维链提示方法实现了可比的结果。然而,这些标注技术都没有超过基于人类标签微调的前三个模型。此外,我们引入了零样本思维链提示作为一种有效的基于方面的社交媒体文本标注策略,其性能优于标准的零样本提示,并且与表现良好但昂贵的少样本提示方法的结果相似。