Chang Li-Chun, Sun Chi-Chin, Chen Ting-Han, Tsai Der-Chong, Lin Hui-Ling, Liao Li-Ling
School of Nursing, Chang Gung University of Science and Technology, Gueishan.
School of Nursing, College of Medicine, Chang Gung University, Tao-Yuan.
Digit Health. 2024 Sep 2;10:20552076241277021. doi: 10.1177/20552076241277021. eCollection 2024 Jan-Dec.
ChatGPT can serve as an adjunct informational tool for ophthalmologists and their patients. However, the reliability and readability of its responses to myopia-related queries in the Chinese language remain underexplored.
This study aimed to evaluate the ability of ChatGPT to address frequently asked questions (FAQs) about myopia by parents and caregivers.
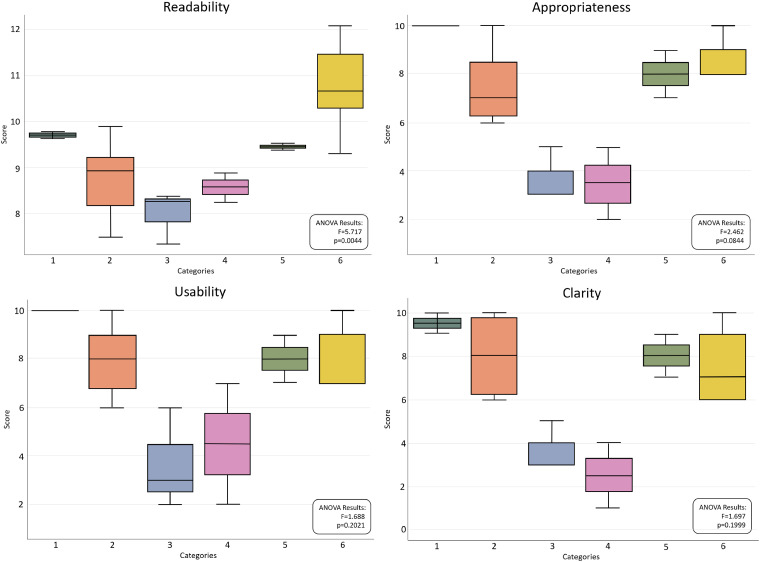
Myopia-related FAQs were input three times into fresh ChatGPT sessions, and the responses were evaluated by 10 ophthalmologists using a Likert scale for appropriateness, usability, and clarity. The Chinese Readability Index Explorer (CRIE) was used to evaluate the readability of each response. Inter-rater reliability among the reviewers was examined using Cohen's kappa coefficient, and Spearman's rank correlation analysis and one-way analysis of variance were used to investigate the relationship between CRIE scores and each criterion.
Forty-five percent of the responses of ChatGPT in Chinese language were appropriate and usable and only 35% met all the set criteria. The CRIE scores for 20 ChatGPT responses ranged from 7.29 to 12.09, indicating that the readability level was equivalent to a middle-to-high school level. Responses about the treatment efficacy and side effects were deficient for all three criteria.
The performance of ChatGPT in addressing pediatric myopia-related questions is currently suboptimal. As parents increasingly utilize digital resources to obtain health information, it has become crucial for eye care professionals to familiarize themselves with artificial intelligence-driven information on pediatric myopia.
ChatGPT可作为眼科医生及其患者的辅助信息工具。然而,其对中文近视相关问题回答的可靠性和可读性仍未得到充分探索。
本研究旨在评估ChatGPT回答家长和护理人员关于近视常见问题的能力。
将近视相关常见问题输入新的ChatGPT会话三次,由10名眼科医生使用李克特量表对回答的适当性、可用性和清晰度进行评估。使用中文可读性指数浏览器(CRIE)评估每个回答的可读性。使用科恩kappa系数检验评审员之间的评分者间信度,并使用斯皮尔曼等级相关分析和单因素方差分析研究CRIE分数与每个标准之间的关系。
ChatGPT的中文回答中有45%是适当且可用的,只有35%符合所有设定标准。20条ChatGPT回答的CRIE分数在7.29至12.09之间,表明可读性水平相当于初中到高中水平。关于治疗效果和副作用的回答在所有三个标准上都存在不足。
ChatGPT在回答儿童近视相关问题方面的表现目前并不理想。随着家长越来越多地利用数字资源获取健康信息,眼科护理专业人员熟悉人工智能驱动的儿童近视信息变得至关重要。