Department of Urology, Saint George Hospital, Kogarah, Australia.
Faculty of Medicine, The University of New South Wales, Sydney, Australia.
J Med Internet Res. 2024 Aug 14;26:e55939. doi: 10.2196/55939.
Artificial intelligence (AI) chatbots, such as ChatGPT, have made significant progress. These chatbots, particularly popular among health care professionals and patients, are transforming patient education and disease experience with personalized information. Accurate, timely patient education is crucial for informed decision-making, especially regarding prostate-specific antigen screening and treatment options. However, the accuracy and reliability of AI chatbots' medical information must be rigorously evaluated. Studies testing ChatGPT's knowledge of prostate cancer are emerging, but there is a need for ongoing evaluation to ensure the quality and safety of information provided to patients.
This study aims to evaluate the quality, accuracy, and readability of ChatGPT-4's responses to common prostate cancer questions posed by patients.
Overall, 8 questions were formulated with an inductive approach based on information topics in peer-reviewed literature and Google Trends data. Adapted versions of the Patient Education Materials Assessment Tool for AI (PEMAT-AI), Global Quality Score, and DISCERN-AI tools were used by 4 independent reviewers to assess the quality of the AI responses. The 8 AI outputs were judged by 7 expert urologists, using an assessment framework developed to assess accuracy, safety, appropriateness, actionability, and effectiveness. The AI responses' readability was assessed using established algorithms (Flesch Reading Ease score, Gunning Fog Index, Flesch-Kincaid Grade Level, The Coleman-Liau Index, and Simple Measure of Gobbledygook [SMOG] Index). A brief tool (Reference Assessment AI [REF-AI]) was developed to analyze the references provided by AI outputs, assessing for reference hallucination, relevance, and quality of references.
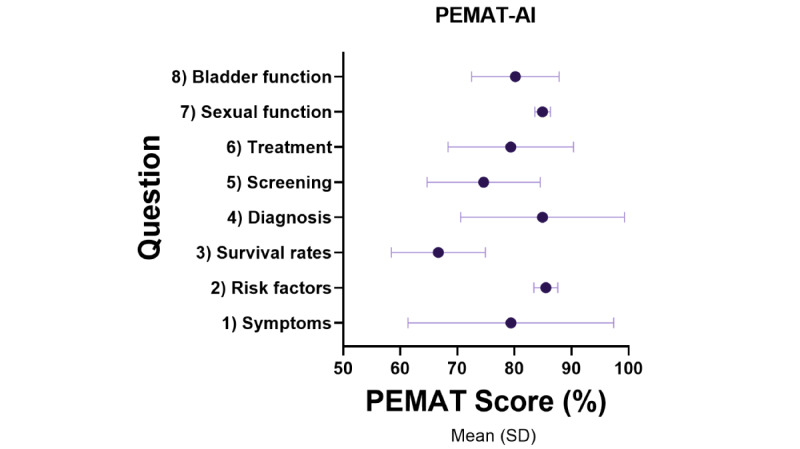
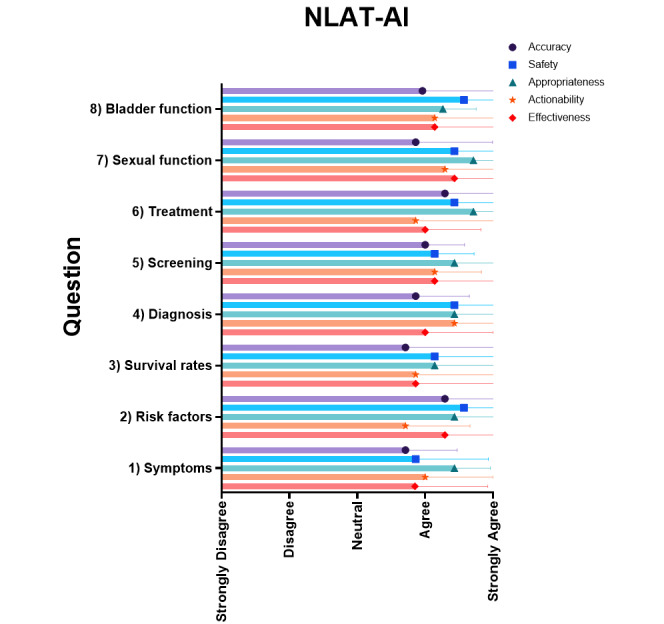
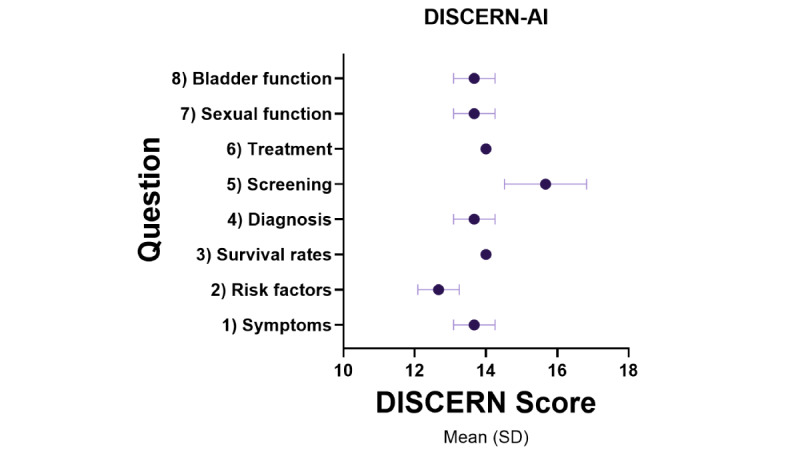
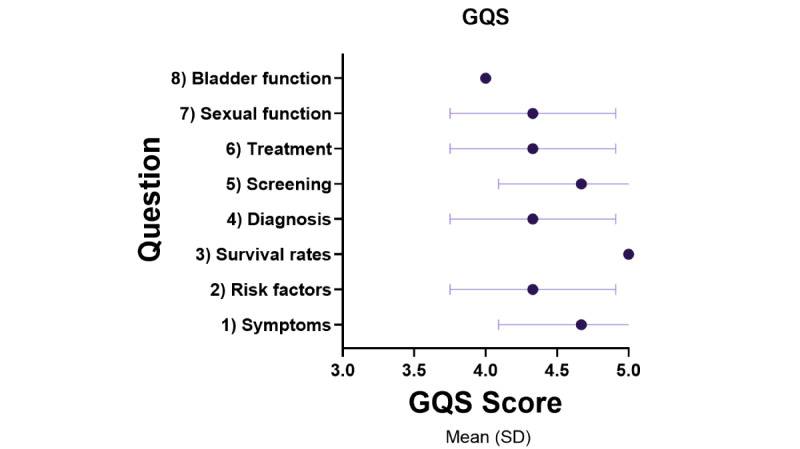
The PEMAT-AI understandability score was very good (mean 79.44%, SD 10.44%), the DISCERN-AI rating was scored as "good" quality (mean 13.88, SD 0.93), and the Global Quality Score was high (mean 4.46/5, SD 0.50). Natural Language Assessment Tool for AI had pooled mean accuracy of 3.96 (SD 0.91), safety of 4.32 (SD 0.86), appropriateness of 4.45 (SD 0.81), actionability of 4.05 (SD 1.15), and effectiveness of 4.09 (SD 0.98). The readability algorithm consensus was "difficult to read" (Flesch Reading Ease score mean 45.97, SD 8.69; Gunning Fog Index mean 14.55, SD 4.79), averaging an 11th-grade reading level, equivalent to 15- to 17-year-olds (Flesch-Kincaid Grade Level mean 12.12, SD 4.34; The Coleman-Liau Index mean 12.75, SD 1.98; SMOG Index mean 11.06, SD 3.20). REF-AI identified 2 reference hallucinations, while the majority (28/30, 93%) of references appropriately supplemented the text. Most references (26/30, 86%) were from reputable government organizations, while a handful were direct citations from scientific literature.
Our analysis found that ChatGPT-4 provides generally good responses to common prostate cancer queries, making it a potentially valuable tool for patient education in prostate cancer care. Objective quality assessment tools indicated that the natural language processing outputs were generally reliable and appropriate, but there is room for improvement.
人工智能(AI)聊天机器人,如 ChatGPT,取得了显著进展。这些聊天机器人在医疗保健专业人员和患者中尤其受欢迎,正在通过个性化信息改变患者教育和疾病体验。准确、及时的患者教育对于知情决策至关重要,特别是在前列腺特异性抗原筛查和治疗选择方面。然而,必须严格评估 AI 聊天机器人的医疗信息的准确性和可靠性。虽然有研究测试 ChatGPT 对前列腺癌的了解,但需要持续评估,以确保提供给患者的信息的质量和安全性。
本研究旨在评估 ChatGPT-4 对患者提出的常见前列腺癌问题的回答的质量、准确性和可读性。
总体而言,根据同行评议文献和 Google Trends 数据中的信息主题,采用归纳法提出了 8 个问题。使用经过修改的人工智能患者教育材料评估工具(PEMAT-AI)、全球质量评分和 DISCERN-AI 工具,由 4 名独立评审员评估 AI 回复的质量。7 名泌尿科专家使用开发的评估框架对 8 个 AI 输出进行评估,以评估准确性、安全性、适当性、可操作性和有效性。使用已建立的算法(Flesch 阅读容易度得分、Gunning Fog 指数、Flesch-Kincaid 等级、Coleman-Liau 指数和简单测量混杂度 [SMOG] 指数)评估 AI 回复的可读性。开发了一个简短的工具(参考评估 AI [REF-AI])来分析 AI 输出提供的参考资料,评估参考资料的幻觉、相关性和质量。
PEMAT-AI 理解得分非常好(平均 79.44%,SD 10.44%),DISCERN-AI 评分评为“良好”质量(平均 13.88,SD 0.93),全球质量评分高(平均 4.46/5,SD 0.50)。自然语言评估 AI 的平均准确率为 3.96(SD 0.91),安全性为 4.32(SD 0.86),适当性为 4.45(SD 0.81),可操作性为 4.05(SD 1.15),有效性为 4.09(SD 0.98)。可读性算法的共识是“难以阅读”(Flesch 阅读容易度得分平均 45.97,SD 8.69;Gunning Fog 指数平均 14.55,SD 4.79),平均阅读水平为 11 年级,相当于 15-17 岁(Flesch-Kincaid 等级平均 12.12,SD 4.34;Coleman-Liau 指数平均 12.75,SD 1.98;SMOG 指数平均 11.06,SD 3.20)。REF-AI 识别出 2 个参考资料幻觉,而大多数(28/30,93%)的参考资料恰当地补充了文本。大多数(26/30,86%)参考资料来自信誉良好的政府组织,而少数则直接引用科学文献。
我们的分析发现,ChatGPT-4 对常见前列腺癌查询提供了一般较好的回复,使其成为前列腺癌护理中患者教育的潜在有价值工具。客观质量评估工具表明,自然语言处理输出通常是可靠和适当的,但仍有改进的空间。